Amazon Web Services ブログ

日産自動車、AWS と連携し SDV 実現に向けたソフトウェア開発を加速
日産自動車は、SDV 開発の3つの目標(「迅速かつ継続的な価値提供」「必要な安全性と性能の確保」「EV、HEV からガソリン車まですべての顧客への SDV 提供」)実現に向け、AWS 上に「Nissan Scalable Open Software Platform」を構築した。
その特徴は、1)CI プロセスの自動化による開発効率の向上、2)グローバルな開発環境の統一、3)次世代コンテナ管理によるプラットフォームの革新、などです。
今後は、AI 技術の活用によりさらなる進化を目指します。

フルマネージド Amazon EKS MCP Server (プレビュー) の紹介
複雑な kubectl コマンドや深い Kubernetes の専門知識の代わりに、シンプルな会話を通じて Amazon Elastic Kubernetes Service (Amazon EKS) クラスターを管理する方法を学びましょう。この記事では、新しいフルマネージド EKS Model Context Protocol (MCP) Server (プレビュー) を使用して、深い Kubernetes の専門知識を必要とせず、自然言語でアプリケーションのデプロイ、問題のトラブルシューティング、クラスターのアップグレードを行う方法を紹介します。複数ステップの手動タスクをシンプルな自然言語リクエストに変換する会話型 AI の実際のシナリオを説明します。

AWS Compute Optimizer での未使用の NAT ゲートウェイの推奨事項を発表
本日より、AWS Compute Optimizer はアイドル状態のリソース検出機能を NAT ゲートウェイ […]

AWS Compute Optimizer での Amazon EBS ボリュームの自動最適化のご紹介
本日より、AWS Compute Optimizer は Amazon Elastic Block Store […]
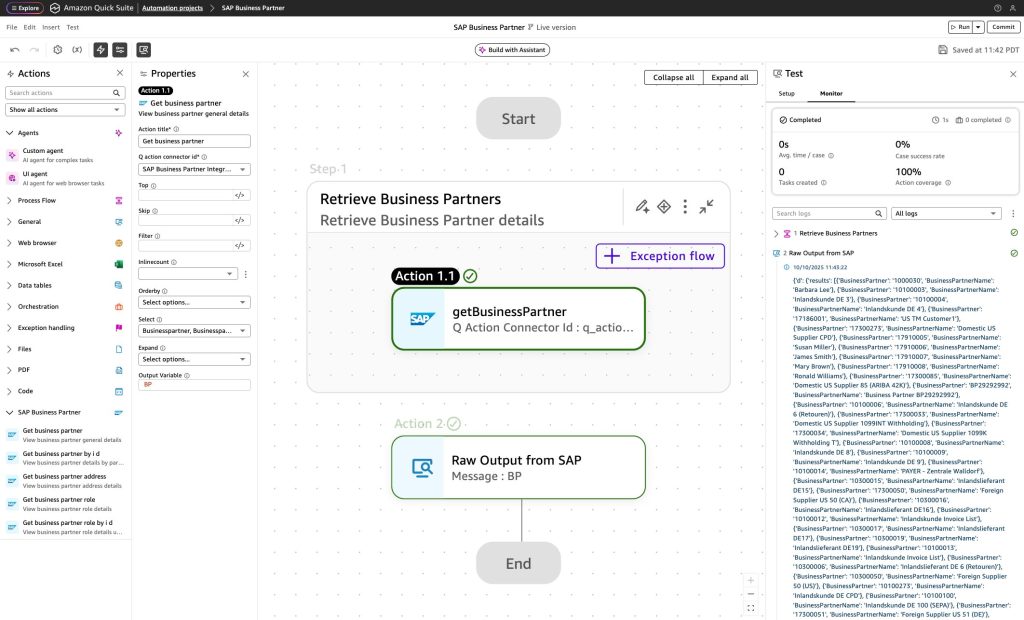
Amazon Quick AutomateでAI駆動のSAP自動化をシームレスに構築
このブログでは、Quick Suite内で利用可能なSAP用の組み込みコネクタと、お客様がAmazon Quick Automateを使用してこれらのコネクタを活用し、ビジネスオペレーションを合理化する強力な自動化を構築する方法について説明します。Quick Automateは、企業が大規模で回復力のある自動化を構築、展開、維持できるようにするQuick Suiteの機能です。AWS Action Connectors for SAPは、お客様がライブSAPデータに対してリアルタイムの読み取り操作を実行できるようにし、Quick AutomateがSAP S/4HANAなどのSAP ERPシステムとシームレスに対話できるようにします。
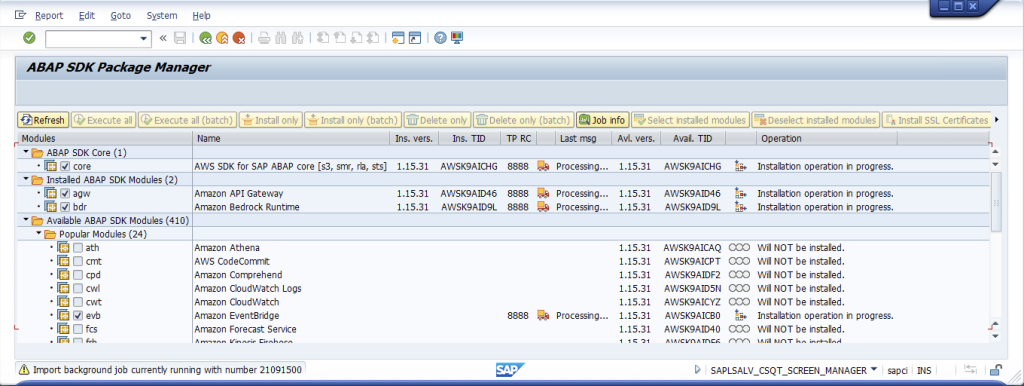
AWS SDK for SAP ABAPをプラグアンドプレイでご体験ください
AWS SDK for SAP ABAP(以下「ABAP SDK」)は、SAP ABAPベースのソフトウェアおよびシステムとAWSサービスとの統合を容易にするために、2023年半ばに初めてリリースされました。他のAWS SDKと同様に、ABAP SDKは一連のモジュールとして提供され、開発プロジェクトにインポートすることで、標準化され、安全でスケーラブルな方法でAWSサービスAPIにアクセスできます。SAP ABAP開発者およびSAP BASIS管理者がより迅速に作業を開始できるようにするため、本ブログでは、ABAP SDK用のグラフィカルインストーラー(以下「ABAP SDKインストーラー」)を紹介します。

Amazon API Gateway TLS セキュリティポリシーによる API セキュリティの強化
コンプライアンスフレームワークが進化し、暗号化標準が進歩するにつれて、組織はクラウドセキュリティ体制を改善するための追加の制御を求めています。必要な制御の1つは、より詳細な TLS 設定です。たとえば、規制要件で CBC のような古い暗号を無効にすることや、TLS 1.3 を最小バージョンとして強制することが義務付けられている場合などです。
この記事では、新しい Amazon API Gateway の強化された TLS セキュリティポリシーが、PCI DSS、Open Banking、FIPS などの標準を満たし、API が TLS ネゴシエーションを処理する方法を強化する仕組みを学びます。この新機能は、運用の複雑さを増やすことなくセキュリティ体制を向上させ、API Gateway インフラストラクチャ全体で TLS 設定を標準化する単一の一貫した方法を提供します。

Application Load Balancer と Amazon API Gateway プライベート統合を使用したスケーラブルな REST API の構築
本日、Amazon API Gateway REST API が Application Load Balancer (ALB) とのプライベート統合をサポートすることを発表しました。この新機能により、ALB をパブリックインターネットに公開することなく、VPC ベースのアプリケーションを REST API 経由で安全に公開できます。
今回のリリース以前は、API Gateway をプライベート ALB に接続する場合、Network Load Balancer (NLB) を中間に配置する必要があり、コストと複雑さが増していました。現在は、NLB を必要とせずに API Gateway をプライベート ALB と直接統合できるため、運用オーバーヘッドが削減され、コストが最適化されます。

AWSとパートナーソリューションによるセキュアなデータメッシュの構築
このブログでは、AWS ネイティブの分析サービスとサードパーティエンジンを同時に活用することを目的としたデータメッシュアーキテクチャを実装するための 3 つの重要な要件を探ります:(1)クロスカタログメタデータフェデレーション、(2)クロスアカウント&クロスエンジンでの認証と認可、(3)分散ポリシーの反映
AWS をデータプロデューサーとコンシューマーの両方として実用的な実装パターンを検討し、Databricks や Snowflake などのパートナーとの統合アプローチを代表例として紹介します。
これらのパターンは、組織が企業全体のガバナンスを維持しながら、データメッシュの中核原則をサポートする柔軟で安全かつスケーラブルなデータアーキテクチャをどのように構築するかを示しています。

AWS CloudTrail データイベントの集約とインサイト機能の発表
AWS CloudTrail は、AWS アカウントの API 呼び出しとイベントを記録し、ガバナンス、コンプライアンス、運用上のトラブルシューティングのための監査証跡を提供します。お客様は CloudTrail でデータイベントを有効にすることで、リソースレベルの操作に対するより深い可視性を得ることもできます。本日、データイベントの監視と対応方法を変革する AWS CloudTrail の強力な新機能を 2 つご紹介できることを嬉しく思います:CloudTrail データイベント用のイベント集約と Insights です。