Amazon Web Services ブログ

新しい Amazon API Gateway Portal で API の発見性を向上させる
Amazon API Gateway は、フルマネージドなポータル機能である Amazon API Gateway Portal を提供開始しました。これにより、静的ウェブサイト、オープンソースソリューション、またはサードパーティ製品を使用する必要がなくなります。これらの従来の方法は、API ライフサイクル管理の断片化やコスト増加につながることがよくありました。API Gateway Portal は API Gateway サービスと統合され、API 製品、インタラクティブな「Try it」機能、API ポートフォリオのドキュメントなどの機能を提供します。

SAP証明書管理のオーバーヘッドをAWS Certificate Managerで削減
多くのSAP管理者やセキュリティ専門家にとって、証明書の管理は、すでに要求の厳しい環境において、さらに複雑なタスクのように思えるかもしれません。ここでAWS Certificate Manager(ACM)が役立ちます。AWS Certificate Managerは、パブリックおよびプライベートSSL/TLS証明書のプロビジョニング、管理、デプロイに使用されるサービスです。これらの証明書を使用して、SAPワークロードなど、EC2インスタンス上で実行されているような証明書を必要とする任意のコンピューティングワークロードでトラフィックを終端できます。
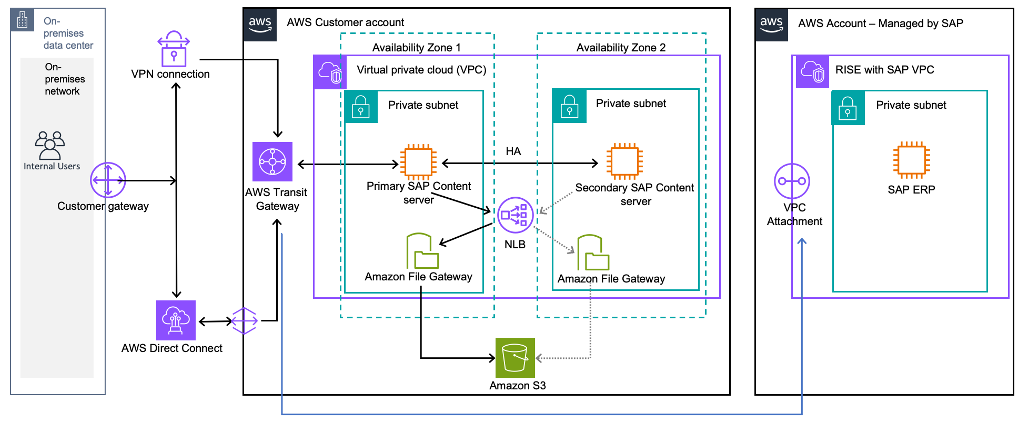
Amazon S3によるHA対応の持続可能で耐久性の高いSAPドキュメントおよびデータアーカイブ – Part2
このブログシリーズのPart 1では、SAP Content Serverを使用しているお客様が、Amazon S3をドキュメントストアとして活用して、コスト効率が高く、堅牢でスケーラブルなドキュメント管理ソリューションを構築する方法を探求しました。このブログシリーズの第2部では、高可用性(HA)を実装することで、お客様がAmazon S3上のSAP Content Serverの信頼性を向上させる方法を共有します。
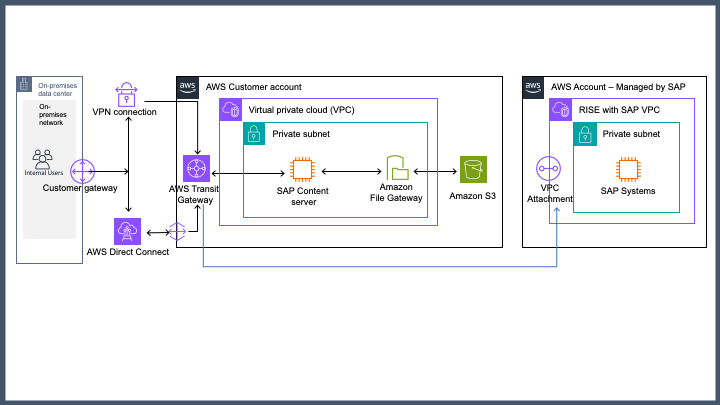
Amazon S3を使用した持続可能で耐久性の高いSAPドキュメントおよびデータアーカイブ
このブログでは、MaxDBに代わるストレージメカニズムを提供し、Amazon Simple Storage Service (S3) File GatewayでSAP Content Serverを使用する方法を紹介します。MaxDB上で実行されている既存のSAP Content ServerをAmazon S3 File Gatewayに移行するための段階的なプロセスをご案内します。
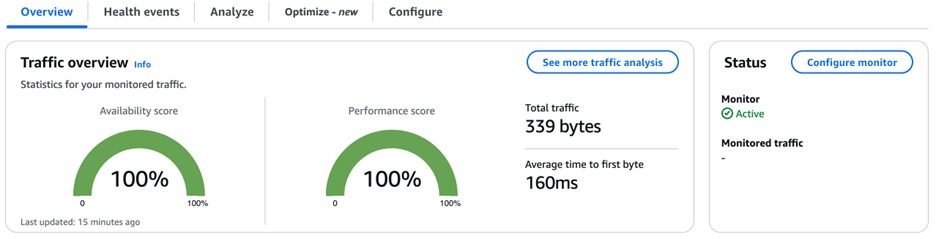
SAP on AWSのエンドツーエンド・オブザーバビリティ: Part-3 Amazon CloudWatch Internet Monitor for SAP
Amazon CloudWatch Internet Monitor for SAP Applications は、インターネット接続に関するリアルタイムのインサイトを提供し、企業が問題をトラブルシューティングし、ネットワークパフォーマンスを最適化するのを支援します。
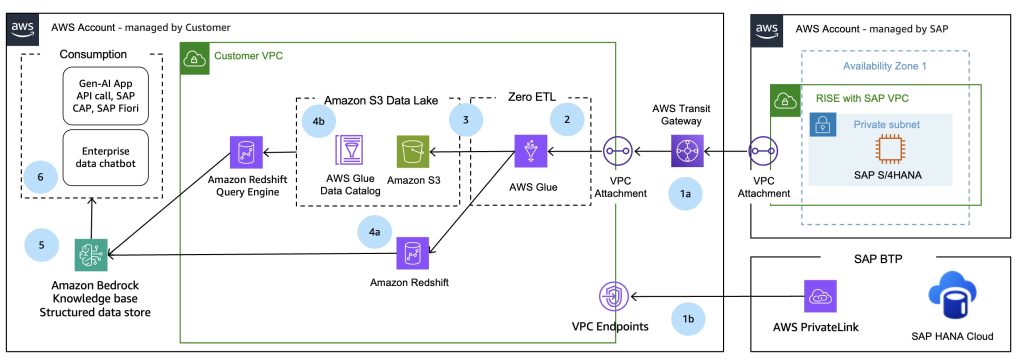
Amazon Bedrock Knowledge BasesでSAPおよびエンタープライズデータから新たな可能性を解き放つ
生成AI(Generative AI)の力とエンタープライズデータインテリジェンスを組み合わせた新しいソリューションを見てみましょう。この記事では、Amazon Bedrock Knowledge Basesが組織のSAPおよびエンタープライズデータの活用方法をどのように革新し、イノベーション、効率性、戦略的意思決定のための新たな可能性を創出しているかを探ります。自然言語クエリから自動化されたドキュメント処理、インテリジェントなインサイト生成まで、このソリューションが企業のSAP投資をAI時代の戦略的資産に変革する方法をご紹介します。

AWS Database Migration Service で PostgreSQL のテーブルをグループ毎にタスク化
本投稿は、 Manojit Saha Sardar と Chirantan Pandya による記事 「Gro […]

大容量テーブルの継続的レプリケーションを、AWS DMS の列フィルターによる並列化でパフォーマンス向上
本投稿は、Vanshika Nigam による記事 「Improve AWS DMS continuous r […]
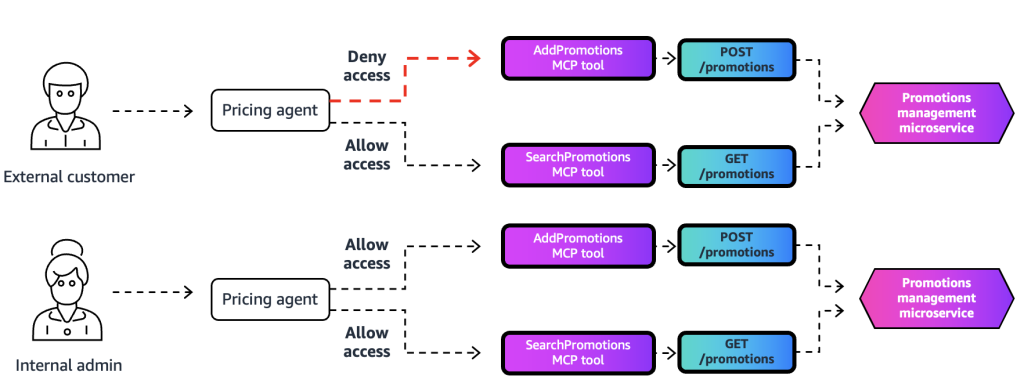
Amazon Bedrock AgentCore ゲートウェイインターセプター: きめ細かなアクセス制御の実現
企業が AI エージェントを採用してワークフローを自動化する中で、組織全体で数千のツールへの安全なアクセスを管理することが重要な課題となっています。数百のエージェントや自動化されたワークフローが、異なる部門にまたがる数千の Model Context Protocol (MCP) ツールにアクセスする統合 AI プラットフォームでは、各呼び出し元が許可されたツールのみにアクセス できるようにする必要があります。また、ユーザー ID やエージェントのコンテキストに基づいてツールへのアクセスを動的にフィルタリングし、マルチホップのワークフローを通じて機密データを保護しながら、パフォーマンスを維持することが求められます。これらの課題 に対応するため、Amazon Bedrock AgentCore Gateway はゲートウェイインターセプターという新機能を提供開始し、きめ細かなセキュリティ、動的なアクセス制御、柔軟なスキーマ管理を可能にします。

【開催報告】セキュリティと生成AI について学ぶ GameDay with AWS Partners
みなさんこんにちは。ソリューションアーキテクトの三厨です。2025 年 10 月 14 日にお客様を AWS […]