Amazon Web Services ブログ
AWS Transform がフルスタック Windows モダナイゼーション機能を発表
2025 年の 5 月、.NET アプリケーションを大規模にモダナイズするための初のエージェント型 AI サー […]

AWS Lambda マネージドインスタンスのご紹介:サーバーレスの簡単さと EC2 の柔軟性
2025 年 11 月 30 日、AWS Lambda マネージドインスタンスを発表しました。これは、サーバー […]

AWS Clean Rooms が ML モデルトレーニング用のプライバシーを強化する合成データセットの生成を開始します
2025 年 11 月 30 日、AWS Clean Rooms 向けのプライバシーを強化する合成データセット […]

株式会社アーベルソフト様の AWS 事例「社内システムをオンプレミスから AWS へ 2 週間で移行、運用工数の 9 割以上を削減」のご紹介
本ブログは 株式会社アーベルソフト 様と Amazon Web Services Japan 合同会社が共同で […]

IAM Policy Autopilot(ビルダー向け新規オープンソース MCP サーバー)で、IAM ポリシー作成を簡素化しましょう
2025 年 11 月 30 日、アプリケーションコードを分析し、AI コーディングアシスタントが AWS I […]

AWS パートナーセントラルが AWS マネジメントコンソールで利用できるようになりました。
2025 月 11 月 30 日、AWS パートナーセントラルがAWS マネジメントコンソールで直接利用できる […]

Amazon EKS の新機能発表:ワークロードオーケストレーションとクラウドリソース管理
2025 年 11 月 30 日、 Amazon Elastic Kubernetes Service (Am […]

AWS re:Invent 2025 での注目の発表
11 月 30 日から12 月 4 日にラスベガスで開催されるAWS re: Invent 2025からの最も […]

安全な Anycast DNS 解決のための Amazon Route 53 グローバルリゾルバーのご紹介(プレビュー)
2025 年 11 月 30 日、Amazon Route 53 グローバルリゾルバーを発表しました。 Ama […]
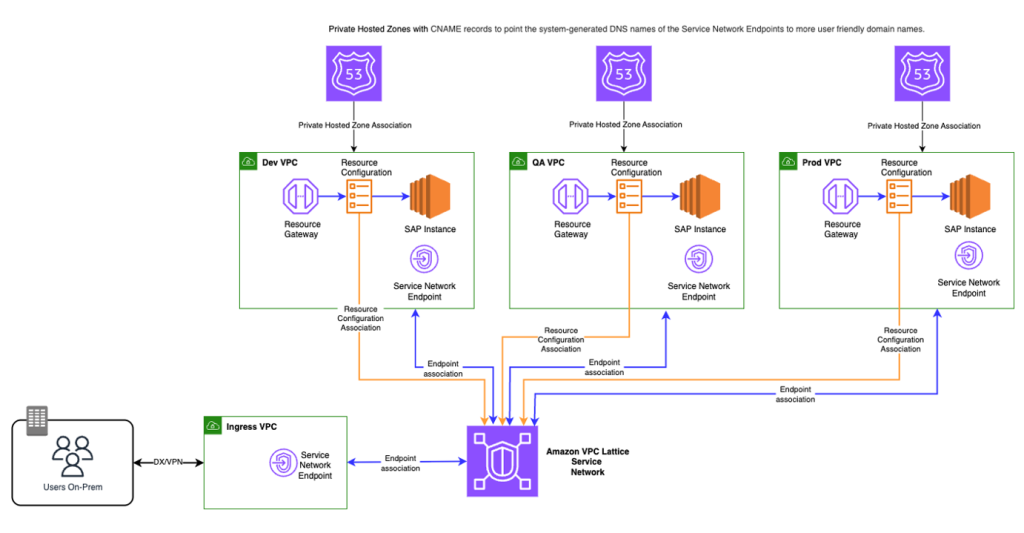
Amazon VPC Latticeによる堅牢なSAPランドスケープ分離の実現
このブログでは、AWS PrivateLinkとAmazon VPC Latticeが、ネットワーク管理を簡素化し、運用の複雑さを軽減しながら、組織が堅牢なSAPランドスケープ分離を実現する方法を探ります。