Amazon Web Services ブログ
Pgpool と Amazon ElastiCache を使って Amazon Redshift でクエリーキャッシュを実現する
Felipe Garcia と Hugo Rozestraten は Amazon Web Services の Solutions Architect です。
この記事では、実際のお客様の事例をもとに、Amazon Redshift の前段に pgpool と Amazon ElastiCache を使ってキャシングレイヤを構築する方法を紹介します(訳注:原文執筆時にはRedshiftにキャッシュ搭載されていなかったのですが、現在はRedshiftには結果キャッシュの機能が備わっているため、キャッシュするだけのためにこのようなソリューションを作成する必要はありません。しかしpgpoolはキャッシュ以外にも利用できる柔軟なソリューションであり、それを分かりやすく示している資料として価値があるため、翻訳記事を掲載しています)
近年、業務アプリケーションはほとんどの場合データベースの利用を想定して構築されます。SQLによるデータベースへのクエリは広く普及した技術ですが、エンドユーザとアプリケーション間の協調を意識しないアーキテクチャ設計が、まったく同一のクエリの複数回実行といった無駄な処理を時として発生させます。このような冗長な処理は計算資源の無駄遣いであり、こういった無駄を省くことができれば他の処理に計算資源を有効活用することができるようになります。
キャッシュとは
コンピュータ用語としてのキャッシュは、将来発生し得るリクエストに迅速に回答するためにデータを事前に蓄積しておくハードウェアコンポーネントまたはソフトウェアコンポーネントを指します。また、必要なデータがキャッシュの中に見つかることをキャッシュヒットといい、必要なデータがキャッシュの中に存在しないことをキャッシュミスといいます。キャッシュの存在により、重い計算の再実行や遅いデータストアからの読み出しが発生しなくなり、高速に結果を得られるようになります。より多くの要求がキャッシュで処理できれば、システムはより高いパフォーマンスを発揮することができます。
お客様事例:臨床研究での遺伝子情報の検索
この事例では、6-10名程度からなる科学者のチームが200万からなる遺伝子のコードの中から特定の遺伝子変異を探し出します。特定の遺伝子変異に隣接する遺伝子も重要な遺伝子で、これらにより異常や病気などが特定できるようになります。
科学者たちは、1つのDNAサンプルをチームで同時に解析し、その後ミーティングを開き自分たちの発見について議論し、結論へと到達します。
この事例では、Node.js のウェブアプリケーションにロジックを実装し、Amazon Redshift にクエリを発行しています。Amazon Redshfit に直接接続したアプリケーションでは、クエリのレイテンシは約10秒でした。アーキテクチャを変更しpgpoolを使用するようにしたところキャッシュにヒットした際に1秒未満で同一のクエリの結果を得られるようになりました。(言い換えると、キャッシュヒット時に10倍高速に応答できるようになりました。) (訳注:現時点ではRedshiftに結果キャッシュの機能が存在するため、こういった仕組み無しでもキャッシュヒット時に高速な応答が実現されています)

Pgpoolの紹介
Pgpool はデータベース・クライアントとデータベース・サーバの間で動作するソフトウェアです。リバースプロキシとして動作し、クライアントからの接続要求を受け、サーバへとそれをフォワードします。もともと PostgreSQL のために書かれており、キャッシング以外にも、コネクションプーリング、レプリケーション、ロードバランシング、コネクションキューイングといった機能を備えます。本稿では、キャッシング機能のみを検証しています。
Pgpool は、Amazon EC2 上でも、オンプレミス環境でも動作させることができます。たとえば、開発やテスト目的でEC2のシングル構成をとるこもできますし、本番環境のために Elastic Load Balancing 、Auto Scaling 構成のEC2複数台構成をとることもできます。
臨床研究の事例では、psql(コマンドライン)と Node.js アプリケーションから Amazon Redshift に対してクエリを発行していて、実際に期待通りに動作することが確認できています。ご自身の環境に適用する場合には、十分な検証を経た上での採用をおすすめいたします。
Pgpool のキャッシング機能
Pgpool のキャッシング機能はデフォルトでは無効になっています。構成のしかたは2種類あります。
- On-memory(shmem)
- これがデフォルトの方式です。なにも設定変更せずにセットアップするとこの設定になります 。 Memcached の構成よりもやや高速に動作します。また、構成や維持管理もより簡単な方式です。一方で、高可用性が求められる環境では、メモリの利用とデータベースクエリ処理が冗長になり無駄になります。クエリが各サーバごとに個別に最低1回実行され、個別にキャッシュされるためです。たとえば、4台からなるpgpoolのクラスタ環境で、20GBのキャッシュが必要であるならば、4台のm3.xlargeをプロビジョニングする必要があり、料金も4倍必要になります。キャッシュは各キャッシング・サーバで独立しているため、同一のクエリが最低4回ずつ実行されることになります。
- Memcached(memcached)
- この方式では、キャッシュはサーバ外部で保持されます。この方式の優位性は、キャッシングストレージ層(Memcached)とキャッシング処理層(pgpool)の疎結合化です。これによりメモリの無駄とデータベースのクエリにかかる負荷の無駄を削減することができます。
- Memcached はどこで動作させても構いませんが、Amazon ElastiCache でのMemcached の利用をおすすめします。Amazon ElastiCache は障害が発生したノードを発見し自動的にリプレースします。耐久性の高いシステムにより、セルフマネージドなインフラストラクチャで発生するようなオーバヘッドが削減され、ウェブサイトやアプリケーションのスローダウンを引き起こすデータベースの過負荷が発生するリスクを低減します。
Pgpool によるクエリのキャッシング
以下のフローチャートは、pgpoolのクエリのキャッシングの動作を示しています。

以下の図は、開発/テスト環境での最小構成のアーキテクチャを示しています。

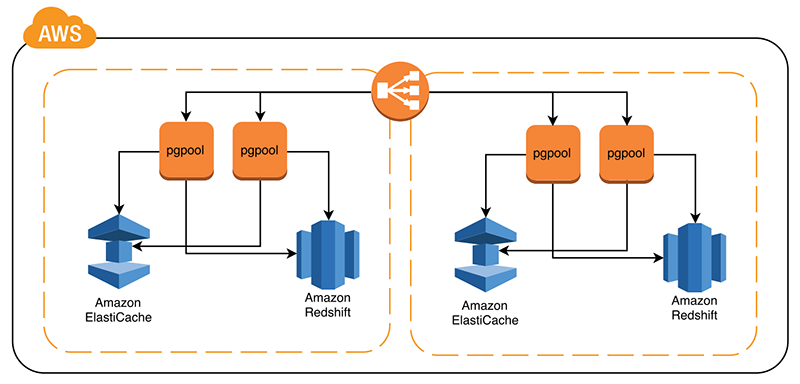
以下の図は、本番環境での推奨最小構成を示しています。
前提条件
この記事では、AWS Command Line Interface (AWS CLI)の使用を前提としています。 ご自身の Mac, Linux, Microsoft Windows マシンを利用する場合、環境に合わせて AWS CLI をインストールしてください。 インストール方法については、こちらをご参照ください。
Pgpool の導入と設定
1. 変数の設定:
IMAGEID=ami-c481fad3
KEYNAME=<set your key name here>
IMAGEID変数は、本稿では、US East (N. Virginia) リージョンを使う想定になっています。
KEYNAME変数は、各自のEC2 キーペアの名前を設定してください。キーペアは、US East (N. Virginia) リージョンで作成されたものであることを確認してください。
各自の環境にあわせて別のリージョンで試す場合は、IMAGEID と KEYNAME をそれぞれ適切な値に変更してください。
2. EC2インスタンスを作成する
aws ec2 create-security-group --group-name PgPoolSecurityGroup --description "Security group to allow access to pgpool"
MYIP=$(curl eth0.me -s | awk '{print $1"/32"}')
aws ec2 authorize-security-group-ingress --group-name PgPoolSecurityGroup --protocol tcp --port 5432 --cidr $MYIP
aws ec2 authorize-security-group-ingress --group-name PgPoolSecurityGroup --protocol tcp --port 22 --cidr $MYIP
INSTANCEID=$(aws ec2 run-instances \
--image-id $IMAGEID \
--security-groups PgPoolSecurityGroup \
--key-name $KEYNAME \
--instance-type m3.medium \
--query 'Instances[0].InstanceId' \
| sed "s/\"//g")
aws ec2 wait instance-status-ok --instance-ids $INSTANCEID
INSTANCEIP=$(aws ec2 describe-instances \
--filters "Name=instance-id,Values=$INSTANCEID" \
--query "Reservations[0].Instances[0].PublicIpAddress" \
| sed "s/\"//g")
3. Amazon ElastiCache Cluster の作成する
aws ec2 create-security-group --group-name MemcachedSecurityGroup --description "Security group to allow access to Memcached" aws ec2 authorize-security-group-ingress --group-name MemcachedSecurityGroup --protocol tcp --port 11211 --source-group PgPoolSecurityGroup MEMCACHEDSECURITYGROUPID=$(aws ec2 describe-security-groups \ --group-names MemcachedSecurityGroup \ --query 'SecurityGroups[0].GroupId' | \ sed "s/\"//g") aws elasticache create-cache-cluster \ --cache-cluster-id PgPoolCache \ --cache-node-type cache.m3.medium \ --num-cache-nodes 1 \ --engine memcached \ --engine-version 1.4.5 \ --security-group-ids $MEMCACHEDSECURITYGROUPID aws elasticache wait cache-cluster-available --cache-cluster-id PgPoolCache
4. SSHを使って、EC2インスタンスにアクセスし、アップデートし、パッケージをインストールする
ssh -i ec2-user@$INSTANCEIP sudo yum update -y sudo yum group install "Development Tools" -y sudo yum install postgresql-devel libmemcached libmemcached-devel -y
5. pgpool のソースコードをダウンロードする
curl -L -o pgpool-II-3.5.3.tar.gz http://www.pgpool.net/download.php?f=pgpool-II-3.5.3.tar.gz
6. ソースコードの展開とコンパイル
tar xvzf pgpool-II-3.5.3.tar.gz cd pgpool-II-3.5.3 ./configure --with-memcached=/usr/include/libmemcached-1.0 make sudo make install
7. サンプルの confファイルから自分用のpgpool.confを作成する
sudo cp /usr/local/etc/pgpool.conf.sample /usr/local/etc/pgpool.conf
8. pgpool.confを編集する
各自の好みのエディタで、/usr/local/etc/pgpool.conf を開き編集してください。以下のパラメータを設定します。
- listen_addresses を * に
- port を 5432 に
- backend_hostname0 を Amazon Redshift cluster のエンドポイントアドレスに
- backend_port0 を 5439 に
- memory_cache_enabled を on に
- memqcache_method を memcached に
- memqcache_memcached_host を Elasticache のエンドポイントアドレスに
- memqcache_memcached_port を Elasticache のエンドポイントポートに
- log_connections を on に
- log_per_node_statement を on に
- pool_passwd を ” に
変更後の設定ファイルは以下のようになっているはずです。
listen_addresses = '*' port = 5432 backend_hostname0 = '' backend_port0 = 5439 memory_cache_enabled = on memqcache_method = 'memcached' memqcache_memcached_host = '' memqcache_memcached_port = 11211 log_connections = on log_per_node_statement = on
9. パーミッションの設定
sudo mkdir /var/run/pgpool sudo chmod u+rw,g+rw,o+rw /var/run/pgpool sudo mkdir /var/log/pgpool sudo chmod u+rw,g+rw,o+rw /var/log/pgpool
10. pgpool の起動
pgpool -n
pgpool が ポート番号5432で起動していることが確認できます。
2016-06-21 16:04:15: pid 18689: LOG: Setting up socket for 0.0.0.0:5432 2016-06-21 16:04:15: pid 18689: LOG: Setting up socket for :::5432 2016-06-21 16:04:15: pid 18689: LOG: pgpool-II successfully started. version 3.5.3 (ekieboshi)
11. テスト
すでに pgpool は起動しています。 Amazon Redshift のクライアントの接続先を Amazon Redshift cluster のエンドポイントから pgpool のエンドポイントに変更しましょう。エンドポイントのアドレスは、マネージメントコンソールまたはCLIを利用し、EC2インスタンスのパブリックIPアドレスを取得するか、あるいは、単に $INSTANCEIP 変数を参照することでも得られます。
#psql –h -p 5432 –U
クエリの初回実行時は以下のような情報が pgpoolのログに残ります
2016-06-21 17:36:33: pid 18689: LOG: DB node id: 0 backend pid: 25936 statement: select
s_acctbal,
s_name,
p_partkey,
p_mfgr,
s_address,
s_phone,
s_comment
from
part,
supplier,
partsupp,
nation,
region
where
p_partkey = ps_partkey
and s_suppkey = ps_suppkey
and p_size = 5
and p_type like '%TIN'
and s_nationkey = n_nationkey
and n_regionkey = r_regionkey
and r_name = 'AFRICA'
and ps_supplycost = (
select
min(ps_supplycost)
from
partsupp,
supplier,
nation,
region
where
p_partkey = ps_partkey,
and s_suppkey = ps_suppkey,
and s_nationkey = n_nationkey,
and n_regionkey = r_regionkey,
and r_name = 'AFRICA'
)
order by
s_acctbal desc,
n_name,
s_name,
p_partkey
limit 100;
最初の行は、クエリが Amazon Redshift クラスタで直接実行されたことを示しています。つまりこれはキャッシュミスです。データベースに対してクエリを実行し結果を返すまでに 6814.595 ms を要しています。
もし、このクエリの実行が2回目だった場合、ログに書かれる内容は違ったものになります。
2016-06-21 17:40:19: pid 18689: LOG: fetch from memory cache
2016-06-21 17:40:19: pid 18689: DETAIL: query result fetched from cache. statement:
select
s_acctbal,
s_name,
p_partkey,
p_mfgr,
s_address,
s_phone,
s_comment
from
part,
supplier,
partsupp,
nation,
region
where
p_partkey = ps_partkey
and s_suppkey = ps_suppkey
and p_size = 5
and p_type like '%TIN'
and s_nationkey = n_nationkey
and n_regionkey = r_regionkey
and r_name = 'AFRICA'
and ps_supplycost = (
select
min(ps_supplycost)
from
partsupp,
supplier,
nation,
region
where
p_partkey = ps_partkey,
and s_suppkey = ps_suppkey,
and s_nationkey = n_nationkey,
and n_regionkey = r_regionkey,
and r_name = 'AFRICA'
)
order by
s_acctbal desc,
n_name,
s_name,
p_partkey
limit 100;
今度は、ログの最初の2行にキャッシュから結果を取り出したことが書かれています。この差は重要です。クエリにかかった時間は 247.719 ms となっています。 言い換えると 以前の実行と比較して 30倍高速になっています。
Pgpool のキャッシュの動作の理解
Pgpool は、SELECT文を結果の取り出しの際のキーにします。
キャッシングの動作と無効化の設定は何通りか方法で可能です。
- 自動無効化
- デフォルトでは、memqcache_auto_cache_invalidation が on になっています。Amazon Redshift のテーブルが更新されると、pgpool のキャッシュは無効化されます。
- 期限設定
- memqcache_expire により、秒単位で結果のキャッシュ保持期間を設定することができます。デフォルトの値は 0 で、この場合、保持期間は無期限になります。
- ブラックリストとホワイトリスト
- white_memqcache_table_list
- コンマ区切りのテーブルのリストでキャッシュすべきテーブルを指定します。正規表現も使用できます。
- black_memqcache_table_list
- コンマ区切りのテーブルのリストでキャッシュすべきでないテーブルを指定します。正規表現も使用できます。
- white_memqcache_table_list
- キャッシュの回避
- /* NO QUERY CACHE */
- SQL文に /* NO QUERY CACHE */ というコメントを挿入することで、クエリは pgpool のキャッシュを無視して、データベースを直接参照するように指定できます。
- /* NO QUERY CACHE */
pgpool が 名前解決の失敗やルーティング上の問題でキャッシュに到達できなかった場合は、データベースのエンドポイントを参照し、キャッシュは参照しなくなります。
まとめ
Pgpool を使って、Amazon Redshift と Amazon ElastiCache でキャッシングソリューションが簡単に実装できることがおわかりいただけたと思います。このソリューションはエンドユーザエクスペリエンスを劇的に改善し、データベースクラスタの負荷を何桁というオーダーで軽減します。
この記事は、pgpool とキャッシングアーキテクチャによって、資源の利用効率が高まることが示されるほんの一例です。さらに詳しく pgpool のキャッシング機能について学ぶ場合は、こちらまたはこちらを参照してください。
Happy querying (and caching, of course) !
このブログは2016年10月に、AWS Solution Architect の Felipe Garcia と Hugo Rozenstraten によって書かれました。原文はこちら。翻訳は AWS Professional Services 芳賀が担当しました。また、原文が書かれた後に追加されたAmazon Redshift の結果キャッシュ機能については、こちらを参照ください。
関連記事
Query Routing and Rewrite: Introducing pgbouncer-rr for Amazon Redshift and PostgreSQL