サーバーレスにおけるべき等性の実装 (バッチ処理と分散トランザクション編) ~ サーバーレスが気になる開発者に捧ぐ「べき等性」ことはじめ 第 4 回
2021-09-02 | Author : 福井 厚

はじめに
このシリーズの 第 2 回 では、クライアントからバックエンドのサービスを利用する際に、なんらかの原因でエラーが発生した場合にクライアント側でリトライ処理が実行されると、リクエストが重複して送られる可能性があることを説明しました。クライアントからキューに対してメッセージを送信するようなサーバーレスのシステムにおいては、リトライ処理によって重複したメッセージが送信されてもメッセージの重複を排除する機能を利用することによってべき等性を実現する方法について解説を行いました。その中では、重複したメッセージをただ一度だけ処理する (Exactly Once) ことで、結果としてべき等性を実現するという具体的な実装方法と共に紹介しました。
第 3 回 では、キューからメッセージを取り出し、バックエンドのデータソースへ保存する処理においても、何らかのエラーによってリトライ処理が発生した場合に重複してデータの書き込みが発生する可能性について説明しました。この際のポイントとして保存されるメッセージを一意に識別する情報がどこで生成されるかによって、べき等性が担保される場合とそうでない場合があること、また保存するデータソースへのプライマリキーの設定、および条件を指定した書き込みによって重複したデータの書き込みを防ぐ方法についても解説しました。
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
AWS Lambda Powertools Python によるべき等性の実装
今回のテーマに入る前に、前回の記事で紹介できなかった AWS Lambda Powertools Python を利用したべき等性の実装について説明したいと思います。
AWS Lambda Powertools Python は、AWS がオープンソースで開発している Lambda 関数専用の Python 用のユーティリティーライブラリで、トレーシングやロギングなど様々な便利なライブラリを提供しています。AWS Lambda Powertools Python のドキュメント や Blog も公開されています。
前回の記事では、DynamoDB に対して同一の値のプライマリキーを含むアイテムデータを Put することで、結果としてべき等性が担保される例を紹介しましたが、AWS Lambda Powertools Python を利用することで、よりスマートにべき等性を実装することができます。AWS Lambda Powertools Python のインストール方法については、ドキュメント をご覧ください。
aws_lambda_powertools.utilities.idempotency
AWS Lambda Powertools Python を利用してべき等性を実装するには、aws_lambda_powertools.utilities.idempotency を利用します。このライブラリを利用するために状態を保存しておくストアが必要です。現在のバージョンでは、ストアとして Amazon DynamoDB をサポートしています。この目的のために、DynamoDB に以下のテーブルを作成しておく必要があります。以下がサンプルの SAM テンプレートになります。31~44 行目、65~66 行目が、idempotency ライブラリを利用するために必要な DynamoDB テーブルの定義部分と、べき等性を実現したい Lambda 関数に、DynamoDB のテーブルに対するアクセス権限を与える箇所になります。
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: >
idempotency-app
Sample SAM Template for idempotency-app
Globals:
Function:
Timeout: 5
Tracing: Active
Environment:
Variables:
POWERTOOLS_METRICS_NAMESPACE: "idempotency-app"
POWERTOOLS_SERVICE_NAME: "order-app"
Api:
TracingEnabled: true
Resources:
Orders:
Type: AWS::DynamoDB::Table
Properties:
TableName: Orders
AttributeDefinitions:
- AttributeName: order_id
AttributeType: S
KeySchema:
- AttributeName: order_id
KeyType: HASH
BillingMode: PAY_PER_REQUEST
IdempotencyTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: IdempotencyTable
AttributeDefinitions:
- AttributeName: id
AttributeType: S
KeySchema:
- AttributeName: id
KeyType: HASH
TimeToLiveSpecification:
AttributeName: expiration
Enabled: true
BillingMode: PAY_PER_REQUEST
IdempotencyFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: src/
Handler: app.lambda_handler
Runtime: python3.8
Events:
OrderApi:
Type: Api
Properties:
Path: /orders
Method: post
Environment:
Variables:
TABLE_NAME: !Ref Orders
LOG_LEVEL: INFO
Policies:
- DynamoDBCrudPolicy:
TableName: !Ref Orders
- DynamoDBCrudPolicy:
TableName: !Ref IdempotencyTableidempotencyライブラリを利用するSAMテンプレートの例
そして、以下がコード例です。5~9 行目、14 行目が idempotency ライブラリに関連する部分になります。 必要なライブラリをインポートした後は、DynamoDBPersistenceLayer メソッドで上記で作成した DynamoDB のテーブルを状態保存先に指定します。IdempotencyConfig メソッドでは、べき等性を判断するイベントのキー (ここでは body を指定) と、べき等性を判断する期間を指定しています。そしてイベントハンドラ関数に @idempotent デコレーターを指定することによって、キーで指定したイベントの JSON データが指定した期間内に同じ内容であった場合、ハンドラ内の実装を実行することなく、初回に返した戻り値と同じ戻り値を返すようになります。これによって安全にべき等性を実現します。
import json
import os
import boto3
import botocore
from aws_lambda_powertools.utilities.idempotency import (
IdempotencyConfig, DynamoDBPersistenceLayer, idempotent)
persistency_layer = DynamoDBPersistenceLayer(table_name='IdempotencyTable')
config = IdempotencyConfig(event_key_jmespath='body', expires_after_seconds=10*60)
dynamodb = boto3.resource('dynamodb')
tableName = os.getenv('TABLE_NAME', 'Orders')
@idempotent(config=config, persistence_store=persistency_layer)
def lambda_handler(event, context):
body_text = event['body']
logger.info("body_text: " + body_text)
body = json.loads(body_text)
order_id = body['order_id']
customer_id = body['customer_id']
order_count = body['order_count']
logger.info({
"order_id": order_id,
"customer_id": customer_id,
"count": order_count
})
response = create_order(dynamodb, tableName, order_id, customer_id, order_count)
return {
"statusCode": 200,
"body": json.dumps({
"order_id": order_id,
"message": "oder created.",
}),
}
def create_order(dynamodb, tableName, order_id, customer_id, order_count):
...以下省略idempotency ライブラリを利用する Python のコード例
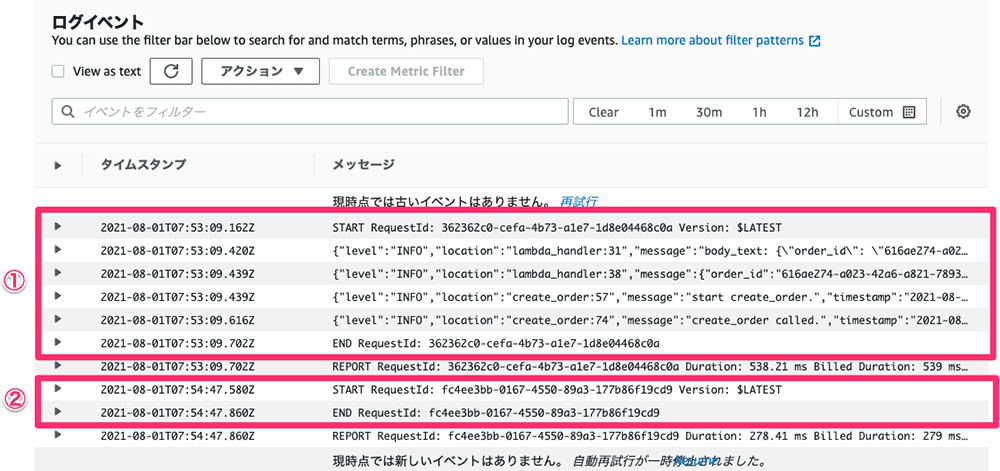
上記の Lambda 関数のコードを実行すると 1 回目の呼び出しでは、こちらの CloudWatch Logs で確認できるように logger.info 関数が実行されてログの出力がされていますが、指定した上記で時間内に再度 Lambda 関数を呼び出すと 2 回目の呼び出しでは、②に示すように Lambda 関数の中のコードは実行されずに終了しています。但し、2 回とも関数は正常に終了し、同じ戻り値を返します。
バッチ処理におけるべき等性
さて、ここからが今回の本題です。
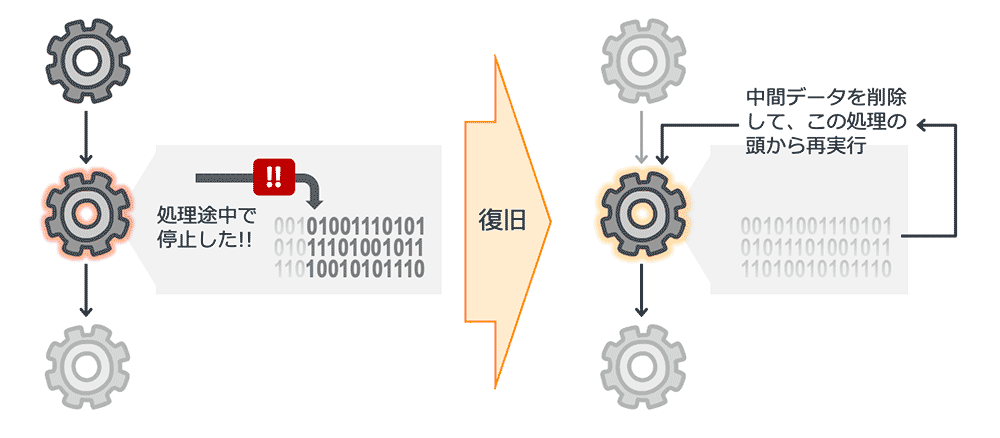
第 4 回の本記事では、複数の処理を繋げて一連の処理とする場合のべき等性について考えます。第 1 回ではデータの加工や集計処理を順番に実施するパイプライン処理を例として取り上げました。ここでは、処理 1 → 処理 2 → 処理 3 ・・・という流れでデータの加工や集計処理が行われる想定ですが、処理 2 の途中まで進んだ状態で何らかの障害が発生し、処理が停止してしまったとした場合について考察しました。第 1 回の記事では、処理 2 の内部で生じる中間データを全削除して、処理 2 の始めから再実行する例を紹介しました。
別の例として、良くあるデータベースへの ETL (Extract Transform Load / 抽出、変換、格納) について考えてみましょう。
CSV (カンマ区切りテキスト) ファイルに数千行のデータが登録されており、先頭から行単位に読み込み、特定の値をコードに置き換えるなど、ある種の変換を行なった上でデータベースに登録する処理を実装するとします。この処理の途中で変換するデータが想定外の値であったなど、何らかの理由で処理が失敗する可能性があります。この時、エラー発生前に処理された行は、正常にデータベースに登録されています。
このような場合、2 つの対応方法があります。1 つは、エラーが発生した行を別のストアにエラー行として保存して、その行をスキップして処理を継続し最後まで処理を行います。終了後、エラーが発生した行を確認してエラーに対応する処理を追加で実装してエラー行をまとめて実行する方法です。
もう一つの方法は、エラーが発生した段階で処理を停止し、ETL 側の処理プログラムを変更して、想定外のデータの場合は特定の値に置き換えて処理を継続できるように修正した上で再度同じ CSV ファイルに対して処理を実行する方法です。この場合、何行目まで処理が成功したかを記録しておいて、その行まで処理をスキップすることで元の CSV ファイルを加工することなく再実行が可能です。この方法のメリットは、エラーのあった特定の行を CSV ファイルから探す必要がなく再度同じファイルを先頭から処理できる点です。これもべき等性の例と言えます。
分散トランザクションに広げて考えてみる
これまで、様々なレイヤーでのべき等性について検討してきました。べき等性について考慮しなければならない理由は、システムに発生した一度の事象 (リクエスト) が何らかの理由で複数回発生する可能性があり、それをシステム的に正しく 1 回の事象として処理して記録する必要があるからでした。
べき等性の概念からは少し離れますが、この考えを少し広めて、複数のデータソースを持つ分散システムにおいて正しい状態を保つとはどういうことかを考えると、あるリクエストに対してすべてが正常に処理され、複数のデータソースが全て正常に更新を完了しているか、または、すべてのデータソースが更新前の状態にロールバックされているかのどちらかの状態でなければならないということになります。
これを実現するためのひとつの方法として、XA 仕様 による分散トランザクション処理の利用があります。トランザクションマネージャ (分散トランザクションコーディネータ) がリソースマネージャ (RDBMS など) を調停し、二層コミットのプロトコルによって分散トランザクションを実行します。
この方法は多くのエンタープライズシステムで採用されていますが、すべてのリソースマネージャがXAインターフェイスをサポートしている必要がある、パフォーマンスが低下するなどの課題もあります。またクラウドが提供するマネージドサービスは、そもそも XA インターフェイスをサポートしていないので利用できないというのもあります。
それではクラウドのマネージドサービスサービスを活用し、サービスごとにデータソースが分けれているマイクロサービスアーキテクチャを採用しているシステムでは、どのようにこの問題を解決すれば良いでしょうか。ここでは、1 つのリクエストに対して複数のサービス間で連携して処理を完成させるようなユースケースを想定しています。
例えば、注文のリクエストに対する、注文の受付処理、支払い処理、在庫の引き当て処理、注文確定のメッセージ送信処理などが個別のサービスとして連携して処理するようなものです。このようなアーキテクチャの場合、サービスが持つデータソースごとにデータをストアしコミットする処理が走るため、XA 仕様の分散トランザクション処理のようなロールバックを行うことは出来ません。そのため、サービス間で連携する処理の途中でエラーが発生した場合、それまでにコミットした状態を元の状態に戻す処理が必要になります。これが補償トランザクションと言われる処理になります。
このような場合に利用されるのが Saga パターンというデザインパターンです。紙面の関係で Saga パターンについて詳細に説明はできませんが、ご興味がある方は AWS DevDay 2020 で私が実施した「分散システムにおける Saga パターンの AWS Step Functions の実装」というセッションをご参照ください。ここでは、上記にあげた例を Saga パターンを利用して AWS Step Functions のワークフローで実装した例を以下に示します。
一番右側のフローが正常に処理が成功する場合で、それ以外は個々のサービスの処理に対して補償トランザクションを実行しています。補償トランザクション自体が失敗した場合は、Amazon SNS で通知だけ行なっています。このような状況が発生した場合は、手作業での介入なども必要になる可能性があることは押さえておく必要があります。
Saga パターンを利用して AWS Step Functions のワークフローで実装した例
まとめ
さて、「サーバーレスが気になる開発者に捧ぐ「べき等性」ことはじめ」と題して 4 回に渡って連載をしてきましたが、いかがだったでしょうか。べき等性の考え方、その重要性とそれぞれのレイヤーごとの対応方法、さらには分散システムにおけるトランザクションにまで考え方を広げました。これらの記事が、AWS を活用して日々システム開発を行なっている皆さんにとって少しでも参考になれば幸いです。
プロフィール
福井 厚
アマゾン ウェブ サービス ジャパン合同会社
シニアソリューションアーキテクト サーバーレススペシャリスト
2015 年からアマゾンウェブサービスジャパンでソリューションアーキテクトとして活動。サーバーレススペシャリストとして日々モダンアプリケーション開発とサーバーレスの活用の技術支援を行なっています。

Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages