Amazon SageMaker Studio で機械学習の最初の一歩を踏み出そう
Author : 秦 将之

はじめに
こんにちは、ソリューションアーキテクトの秦です。
AWS では、日々業務を通して機械学習を取り扱っている、またはこれから学習をはじめる人向けに、機械学習モデルの開発・学習・推論といったワークフローを効率化するサービスとして Amazon SageMaker を提供しています。
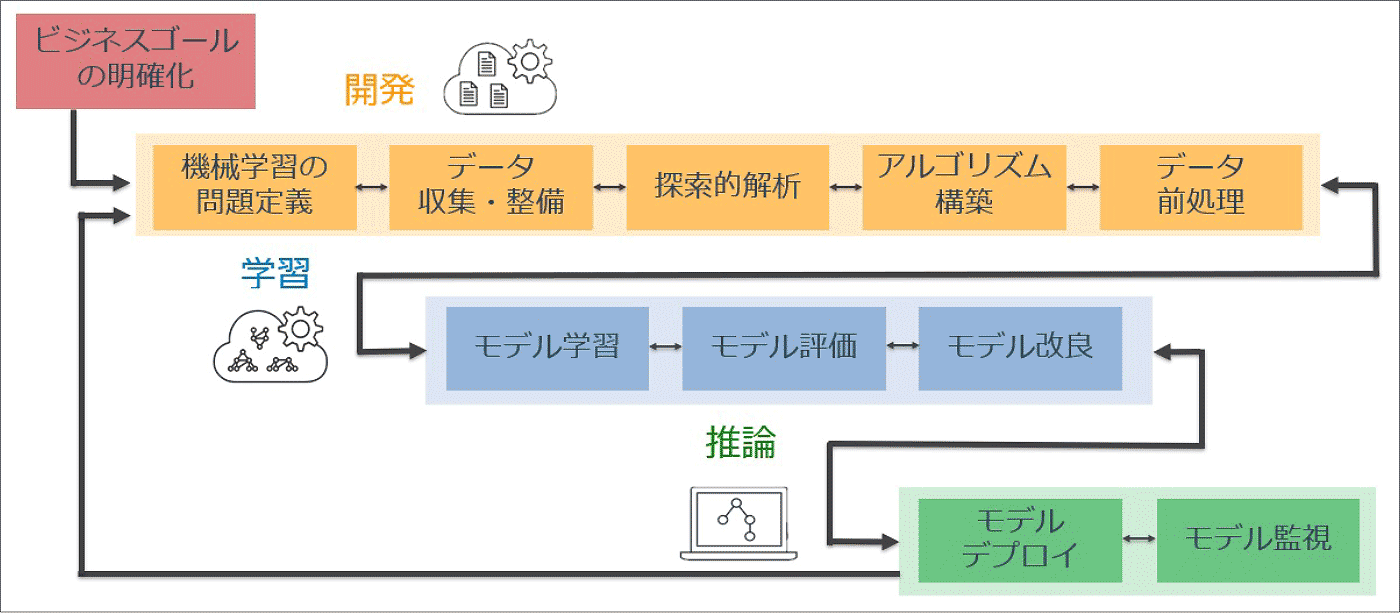
Amazon SageMaker では様々な機械学習のシーンにおいて役立つ多くの機能があり、今回紹介する Amazon SageMaker の一機能である Amazon SageMaker Studio は、機械学習における開発・学習・推論の一連のワークフローに加え、MLOps をサポートする統合開発環境を提供します。
特に学習モデル開発において、モデル評価・改良のプロセスは非常に重要で、試行錯誤しながら学習モデルの精度を高めていく必要がありますが、Amazon SageMaker Studio を利用すれば学習モデル開発のプロセスを可視化でき、改善プロセスを楽に行うことができます。
今回は、Amazon SageMaker Studio がどのように機械学習ワークフローを効率化するか、一連の流れについてご紹介していきます。
builders.flash メールメンバー登録
1. Amazon SageMaker のアーキテクチャについて
アーキテクチャ
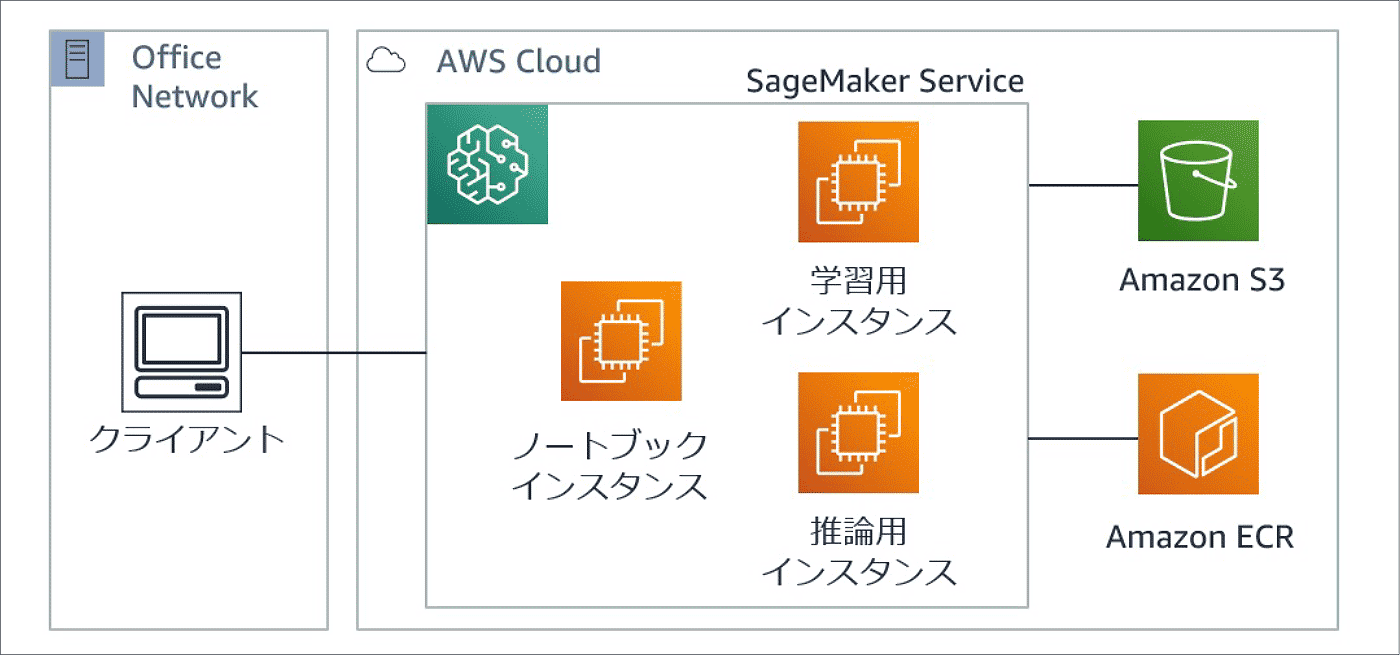
- ノートブックインスタンス : 機械学習コードを開発する環境
- 学習用インスタンス : 作成した機械学習コードの学習環境
- 推論用インスタンス : 機械学習モデルのデプロイおよび推論環境
次章以降で実際に Amazon SageMaker Studio を使った Studio ノートブックインスタンスでの、機械学習コードの実行、機械学習モデルの作成、推論環境のデプロイと順を追ってやってみます。
2. Studio ノートブックインスタンスの立ち上げ
手順
まずは、Studio ノートブックインスタンス環境を立ち上げていきましょう。Amazon SageMaker Studio では実行するノートブック毎にインスタンスを選ぶことができ、それを Studio ノートブック のインスタンスと呼びます。AWS のコンソール画面から Amazon SageMaker のダッシュボードを開き Amazon SageMaker の「 今すぐ始める 」から SageMaker Studio をクリックしてください、必要な設定を入れて数分待つと Jupyter ノートブック環境が起動します。
開始方法については、 こちら にも詳細がありますので 1-12 までを実践してみてください。
起動が完了するとこちらのような Amazon SageMaker Studio の画面が立ち上がります。

もし学習コードのリポジトリに Git をご利用であれば、上記の Amazon SageMaker Studio 画面内で「 FIle 」タブ→「 New 」→「 Terminal 」を選択すると Terminal 起動ができますので、git clone でお手持ちのソースコードの持ち込みができます。今回は AWS Samples からBERT (Bidirectional Encoder Representations from Transformers) という自然言語処理モデルの学習コードを clone しましょう。
以降では、本学習コードを用いて、文書分類タスクでしばしば用いられる DBpedia データセットから文書分類用学習モデルを作成し、input したテキストがどのような話題についてのものか (Company, EducationalInstitution, Artist, Athlete, OfficeHolder・・・といった) 14 の Classに 分類する推論用エンドポイントを作成していきます。今回は説明用に一部コードを変更していますが、そのまま実行いただいても問題なく動作します。

一度、git clone が完了すると Studio ノートブックインスタンス上で学習コードを実行することが可能です。画面左側のファイルエクスプローラから BertTextClassification.ipynb をダブルクリックしてサンプルノートブックを開いてください。

ノートブックの実行環境を選択するプロンプトが開いたら、今回は「 Python3 (Data Science) 」カーネルを選択し、「 Select 」 をクリックしてください。

今回利用するカーネルには、あらかじめ SageMaker の Python SDK や、Pandas、Numpy、matplotlib といったデータサイエンスでよく用いられるパッケージがインストールされています。その他、必要なパッケージはユーザーが自由にカスタマイズしてインストールすることが可能です。カーネルが立ちあがるとノートブックの上部に起動しているカーネルとインスタンスの CPU/GPU、メモリが表示されます。

また、赤く囲った部分をクリックしていただくと、選択できるインスタンスタイプ一覧が表示されます。デフォルトは推奨のもの (ml.t3.medium) が設定されていますので、インスタンスタイプを変更したい場合はこちらからご選択ください。ちなみに、今回は GPU インスタンスである ml.g4dn.xlarge を選択しています。
※その他、利用可能なカーネルの詳細は、 こちら をご参照ください。

なお、Studio ノートブックインスタンスにおいては、学習データの前処理や、SageMaker SDK を利用した持ち込み学習コードのトレーニングジョブを実行します。必要なパッケージインストールと前処理ができたら、トレーニングジョブの前準備として Estimator クラスを定義する必要があります。(見やすくするため git の学習コードからパラメータの記載を一部変更しています。)
変更前
estimator = PyTorch(
entry_point='main.py',
source_dir = 'src',
role=role,
framework_version ="1.4.0",
py_version='py3',
instance_count=1, instance_type=instance_type,
hyperparameters = hp,
output_path=s3_output_path,
metric_definitions=metric_definitions,
volume_size=30,
code_location=s3_code_path,
debugger_hook_config=False,
base_job_name =base_name,
use_spot_instances = use_spot,
max_run = train_max_run_secs,
max_wait = max_wait_time_secs,
checkpoint_s3_uri=s3_checkpoint,
checkpoint_local_path=sm_localcheckpoint_dir)変更後
hpo_estimator = PyTorch(entry_point ='main.py',
source_dir = 'src',
role = role,
framework_version = "1.4.0",
py_version ='py3',
instance_count = 1,
instance_type = "ml.p3.xlarge",
output_path = s3_output_path,
debugger_hook_config = False,
use_spot_instances = False,
hyperparameters = {
"epochs" : 10,
#検索対象のハイパーパラメータを除外
#"lr":0.00001,
#"batch" : 32,
"trainfile" :s3_uri_train.split("/")[-1],
"valfile" : s3_uri_val.split("/")[-1],
"classfile":s3_uri_classes.split("/")[-1],
},
metric_definitions = [
{"Name": "TrainLoss","Regex": "###score: train_loss### (\d*[.]?\d*)"},
{"Name": "ValidationLoss","Regex": "###score: val_loss### (\d*[.]?\d*)"},
{"Name": "TrainScore","Regex": "###score: train_score### (\d*[.]?\d*)"},
{"Name": "ValidationScore","Regex": "###score: val_score### (\d*[.]?\d*)"}
],)この Estimator クラスでは、マネージドな PyTorch コンテナを呼び出し、コンテナ内で実行する持ち込み学習コードの指定、学習用インスタンスのタイプ指定、スポットインスタンスの利用設定、ハイパーパラメータ、監視メトリクスなどの定義ができます。
※Estimator クラスで指定できるパラメータの詳細は こちら をご参照ください。
学習コード側で必要な改修は、この Estimator で定義したハイパーパラメータを引数として受け渡すのみで、そのまま動かすことが可能です。Estimator を定義したら学習に必要な引数を fit 関数に渡してあげて実行すると学習が開始します。
estimator.fit(inputs)3. トレーニングの実行
解説
学習用インスタンスのタイプは、先ほど Estimator クラスで指定すると記載しましたが、CPU 以外にも GPU を利用可能なインスタンスも用意されています。そちらを利用した学習も可能で、学習コードが並列実行に対応していれば並列実行数も指定できます。
また、コストの観点では、学習が完了したら自動的に学習用インスタンスが終了するため、学習用インスタンスの起動時間のみに対してコストがかかります。また学習用インスタンスにスポットインスタンスを利用することで、最大 90% のコストを削減することができます。仮にスポットインスタンスが中断してしまったとしても checkpoint ファイルを作成し途中から学習を継続することができるような仕組みになっています。
オンプレで学習を実行する場合は、利用有無に関わらずハード購入費や保守費用が必要となりますが、クラウドを使うと従量課金となり、GPU などのリソースを必要な時に必要な分利用することができます。このようなリソーㇲの柔軟性は学習を効率化するクラウドのメリットの一つです。
学習が完了すると、学習モデルは S3 に出力され、マネジメントコンソールから学習結果を確認できます。コンソールからは、入力データ、メトリクスのモニタリング結果、ハイパーパラメータ、S3 モデルアーティファクトなどが参照できます。

また、Estimator クラス+学習コードで定義した Loss などのメトリクスを CloudWatch からも確認できるようになっています。


このように学習結果を可視化することで、例えばハイパーパラメータと Loss の推移を見ながら学習モデルチューニングやモデル評価に役立てたり、複数人で開発を行っている場合は共通ダッシュボードとして出力結果を見ながらディスカッションするといったことも実施しやすくなっています。
なお、今回の学習コードは git からの持ち込みでしたが、Docker イメージがある場合はイメージをそのまま持ち込むこともできます。学習コードの作成ハードルが高い場合は、あらかじめ Amazon SageMaker で用意したビルトインアルゴリズムを利用することもできますし、Amazon SageMaker の機能である Amazon SageMaker JumpStart から、あらかじめ用意された画像認識や自然言語処理を含む多くのトレーニング済モデルをファインチューニングして即座にデプロイするといったことも可能です。
4. 学習モデルのデプロイ
解説
学習完了後、インスタンスサイズを指定して deploy 関数を実行すると、入力データに対して推論結果を返す推論エンドポイントを作成します。下記のように、deploy 関数実行時には推論用コードと推論環境を設定することもでき、推論用のインスタンスタイプと起動数を指定します。推論実行数の増加などに対して柔軟な推論環境を簡単に作成することができます。
model = PyTorchModel(model_data=model_uri,
role=role,
py_version = "py3",
framework_version='1.4.0',
entry_point='serve.py',
source_dir='src')
predictor = model.deploy(initial_instance_count=1, instance_type='ml.p3.2xlarge')
この推論エンドポイントはリアルタイム推論用として常時立ち上げておくこともできますし、非同期バッチ実行用として特定の時間に立ち上げ、処理が終わると自動的にインスタンスを終了させることも可能で、どのような推論を行いたいかによって選択できます。
今回はリアルタイム推論用エンドポイントを立ち上げましたので、実際に学習した BERT モデルにテキストを投げてみて文書分類を実施してみます。
predictor.serializer = TextSerDes()
predictor.deserializer = TextSerDes()
data = ["Enable more people to innovate with ML through a choice of tools—integrated development environments\
for data scientists and no-code visual interfaces for business analysts."]
response = predictor.predict(data, initial_args={ "Accept":"text/json", "ContentType" : "text/csv" }
)
response
結果は下記のようになりました。入力したテキストは Company に関する文章という分類結果となっています。
[{'Company': 0.39544713497161865}]5. 推論用エンドポイントの削除
手順
推論用エンドポイントを立ち上げたままにしておくと料金が発生するため、最後に忘れずに、推論エンドポイントを削除しておきましょう。
predictor.delete_endpoint()以上が、Amazon SageMaker Studio で学習ワークフローを実行する一連の流れとなります。
6. より便利な利用方法~ハイパーパラメータの調整ジョブ~
手順
最後に Amazon SageMaker Studio の便利な機能として、ハイパーパラメータの調整ジョブをご紹介させていただきます。こちらの機能を利用するとベイズ最適化によりハイパーパラメータ探索を楽に行うことができます。
やり方はとても簡単です。まずは、パラメータ探索対象のハイパーパラメータを除外した Estimator クラスを作成しておきます。(今回の対象は学習率 lr とバッチサイズ batch-size です)
hpo_estimator = PyTorch(entry_point ='main.py',
source_dir = 'src',
role = role,
framework_version = "1.4.0",
py_version ='py3',
instance_count = 1,
instance_type = "ml.p3.xlarge",
output_path = s3_output_path,
debugger_hook_config = False,
use_spot_instances = False,
hyperparameters = {
"epochs" : 10,
#検索対象のハイパーパラメータを除外
#"lr":0.00001,
#"batch" : 32,
"trainfile" :s3_uri_train.split("/")[-1],
"valfile" : s3_uri_val.split("/")[-1],
"classfile":s3_uri_classes.split("/")[-1],
},
metric_definitions = [
{"Name": "TrainLoss","Regex": "###score: train_loss### (\d*[.]?\d*)"},
{"Name": "ValidationLoss","Regex": "###score: val_loss### (\d*[.]?\d*)"},
{"Name": "TrainScore","Regex": "###score: train_score### (\d*[.]?\d*)"},
{"Name": "ValidationScore","Regex": "###score: val_score### (\d*[.]?\d*)"}
],)
パラメータ探索範囲を下記のように設定した辞書を作成します。
hyperparameter_ranges = {'lr': ContinuousParameter(0.001, 0.1),'batch': CategoricalParameter([4,8])}対象とするメトリクスを設定し、今回は Train Loss を最小にするハイパーパラメータを探索するようにしました。HyperparameterTuner クラスに必要なパラメータを設定し、fit 関数で指定回数分学習を実行していきます。
objective_metric_name = 'TrainLoss'
objective_type = 'Minimize'
metric_definitions = [{'Name': 'TrainLoss','Regex': '###score: train_loss### (\d*[.]?\d*)'}]
tuner = HyperparameterTuner(hpo_estimator,
objective_metric_name,
hyperparameter_ranges,
metric_definitions,
max_jobs=4,
max_parallel_jobs=2,
objective_type=objective_type)
tuner.fit(inputs, wait=False)
tuner.wait()
Loss の最小値と最終的に最適と判断されたハイパーパラメータはマネメジメントコンソール上から確認できます。

学習モデルが作成されたらデプロイは先ほどと同じように deploy 関数を使って実行できます。
hpo_model_uri = os.path.join(s3_best_training_output_path, "model.tar.gz")
hpo_model = PyTorchModel(model_data=hpo_model_uri,
role=role,
py_version = "py3",
framework_version='1.4.0',
entry_point='serve.py',
source_dir='src')
predictor = hpo_model.deploy(initial_instance_count=1, instance_type='ml.p3.8xlarge')
学習の際にはベースモデルを作成したりハイパーパラメータを決定するとこは、重要なタスクであり重労働になります、このような Amazon SageMaker の仕組みを利用することで効率的に作業を行うことができるようになっていますので、是非活用してみてください。
最後は忘れずに推論用エンドポイントを削除しておきましょう。
predictor.delete_endpoint()7. Amazon SageMaker Studio メリット
まとめ
今回は、Amazon SageMaker Studio で機械学習ワークフローを効率化するポイントを解説してきました。
Amazon SageMaker Studio はブラウザからすぐに起動でき、今お使いの学習コードに軽微な改修を加えるだけで利用を開始できます。
また、学習・推論実行環境は GPU など AWS の幅広いインスタンスリソースをご選択いただけ、スポットインスタンスも活用いただくことでコストを抑えて学習を行えます。学習管理機能も充実しており Loss の管理やチューニングなども柔軟です。
さらに、実際の開発の現場では、チームを組んで複数のロールで機械学習ワークロードを管理されることも多いかと思います。そういった点では Amazon SageMaker はアーキテクチャが分離できているので、各ユーザのロールが作業しやすくなっています。複数人で機械学習モデルを開発しているような場合は S3 にデータと学習モデルを配置できるので、他の開発者と共有しやすいといったこともポイントです。
今回は、Amazon SageMaker Studio をご紹介させていただきましたが、AWS ではそれ以外にも機械学習ワークロードを効率化する多くの機能を提供しています、是非一度目を通してみてください。各機能の詳細は こちら 。
Amazon SageMaker の機能をうまく活用してクラウドネイティブで快適な機械学習ワークロードを実現していきましょう !
筆者プロフィール
秦 将之
アマゾン ウェブ サービス ジャパン合同会社
ソリューションアーキテクト
普段はソリューションアーキテクトとして製造業界のお客様の技術支援を担当しています。好きなサービスは Amazon SageMaker。趣味はジム通いと歌うこと。

Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages