サーバーレスアプリケーション開発におけるエラーハンドリング ~ ワークフローパターン後編 ~
2024-02-01 | Author : 大磯 直人

はじめに
本編ではワークフローにおけるエラーハンドリングを AWS で実現する際に、抑えておくべきポイントについて紹介します。
ワークフローは、ワークフロー全体で各々のステートが相互に整合性及び一貫性を持つ必要があるもの (ステート分散ワークフロー) と、大規模なデータ処理を行うものと 2 つがあります。ワークフローパターンを前編、後編に分けて、それぞれのパターンに対してのエラーハンドリングの手法について紹介します。
今回は後編としてワークフローパターンとしての大規模データ処理のユースケースにフォーカスを当てて、AWS Step Functions の Distributed Map 利用時におけるエラーハンドリングについて説明していきます。本シリーズの オープニング記事 でもサーバーレスエラーハンドリングの基礎と絡めて説明しておりますので、またご覧になられていない方は、そちらからご覧頂けると理解が深まると思います !
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
ユースケース
前編 に引き続き、条件分岐を含む実行単位の長いシーケンシャンルなステップの集合であるワークフローが今回もテーマになります。ただし前回と異なる点として、大規模データ処理用途でのワークフローとしてのケースについて紹介します。
おそらく皆様が聞き馴染みがある言葉としては、バッチ処理と言われる一括大規模データ処理に当たるものが今回のテーマの対象になり、分析用途などの大量データ、大規模処理、高負荷計算といったキーワードで語られるユースケースがそれに当たります。
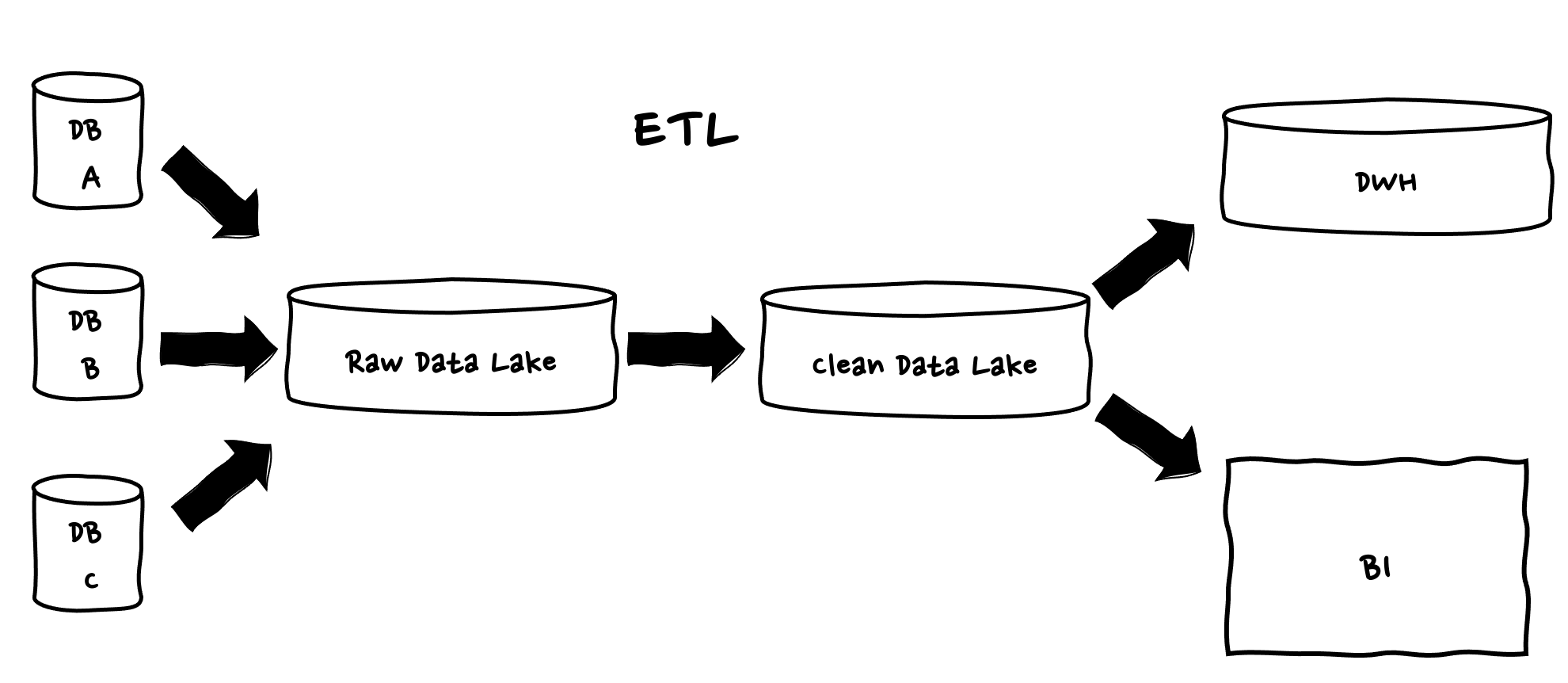
具体例を上げると、複数の販売チャネルで販売を行っている小売店での、販売経路ごと (例:ネット、モバイル、電話、FAX) の注文データを日次や週次で集めて、データのクレンジングを行い、集計し、DWH にローディングする、BI ツールで分析するなどのフローなどが考えられます。
大規模データ処理は、その回ごとに処理をするべきデータ量が変動するため、必要なリソース量が異なることに加え、基本的に 1 日に 1 回などの頻度での実行のため、動いていない期間が多いことから、リソース量の制御の柔軟性とそれに応じたコスト発生である課金体系というメリットを強く受けられるサーバーレスに適したユースケースになります。
パターン特性
先程述べた通り大規模データ処理は、大量データ、並列分散処理、高負荷計算をするようなワークフローです。 ワークフローパターン前編 で紹介したステート分散ワークフローパターンとの違いとしては、ステートレスであること、マシンリソースや実行時間を大量に必要とすることが挙げられます。
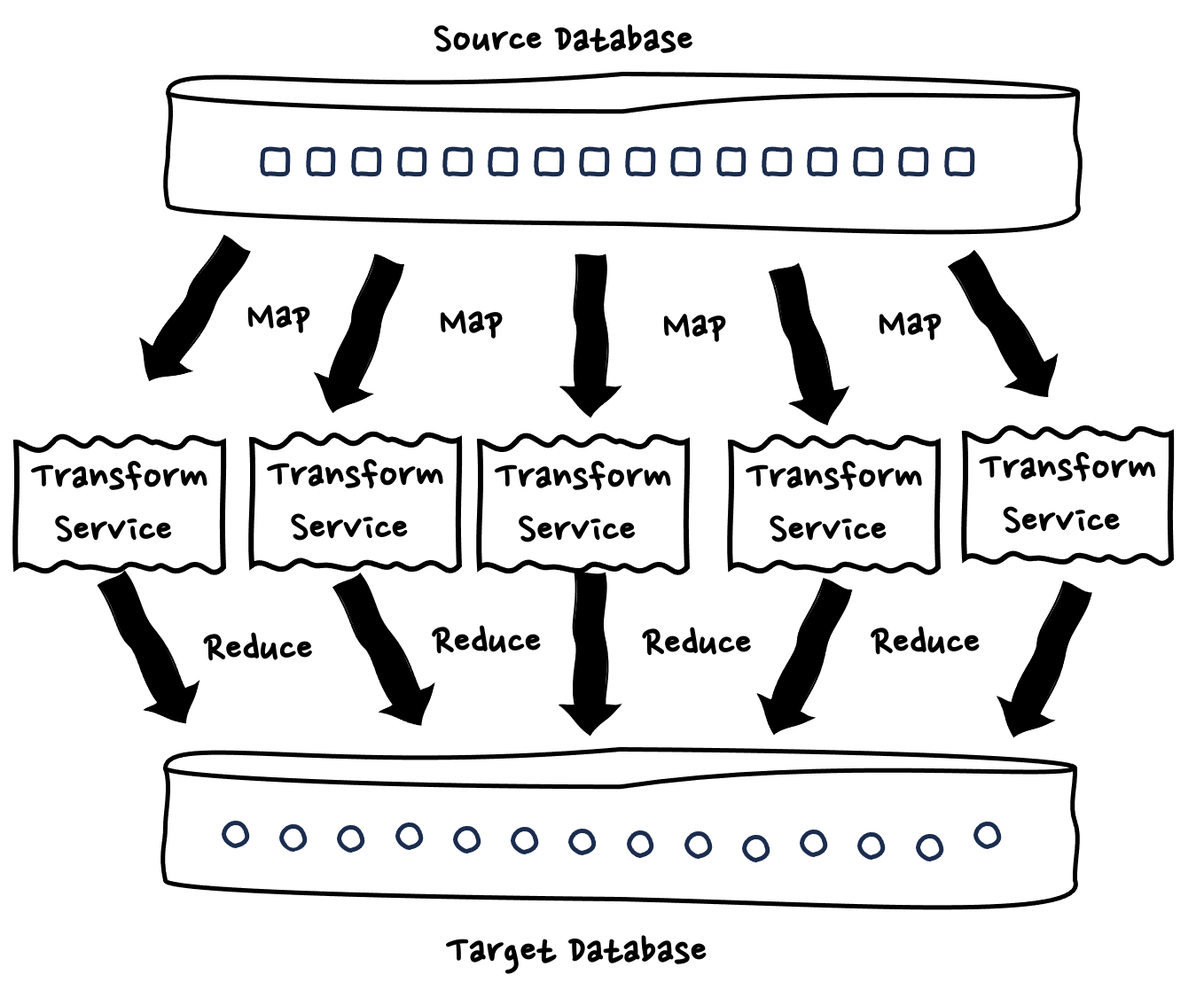
大規模データ処理のケースではいわゆる MapReduce のような手法で、データを並列処理されるものが多くあります。MapReduce は、大量のデータを分割して、それぞれのマシンに振り分けを行い、定められた処理を実行し、結果を一箇所に集約する処理で、多くのケースではマシンを複数台立てることで、コストを掛けながら処理完了までの時間を短縮させるトレードオフの意思決定を行います。つまり大量のコンピュティングリソースまたは、長期間の処理時間が必要になります。このような大規模データ処理におけるエラーハンドリングで考慮すべきポイントは 2 つあります。
1 つ目は、並列分散処理において必要な結果を得るための許容できるエラー率を定めることです。並列分散処理の中で1 つでもエラーが出るたびに処理を中断させて修正を行っていると、せっかくコストを掛けて並列実行を行っているにも関わらず、最終的な結果が出るまでの期間が後ろ倒しになってしまいます。
とはいえ、設定やコードの修正が必要なエラーやインフラの一時的な障害によって大量のエラーが出ていて、明らかに意味のない処理をしている場合に最後まで処理を実行すると、不要なコンピューティングコストを支払うことになります。これらのトレードオフを考慮し、必要な結果を得るための許容できるエラー率を定めることが重要です。
2 つ目は再開時に重複する処理を極力行わないことで、無駄なコスト及び時間を圧縮することになります。先程述べたように、エラーとして処理を中断させるさせた際に、その原因が一時的なものであり、リトライによってカバーできるものであれば、再実行することで回復出来ます。従来のエラーハンドリングで頻繁に出ていたリトライは、大規模データ処理においても当然有効で、計算結果としては正しい結果が得られます。しかしながら、一回あたりの所要時間またはコストが膨大に必要とされる大規模分析においては、安易なワークロード全体としてのリトライを実施するのはビジネス観点で許容できないシーンが多いです。
例えば 1 億件のデータ処理において、大部分が成功していたり分散処理自体は完了しているのにも関わらず、エラーによるワークフロー全体をリトライし、再度 1 億件全件のデータ処理が行われるのは合理的とは言えません。そのため、失敗した箇所からの再開や、また分散処理内におけるエラーの場合は失敗したデータのみのリトライ制御を行うことがポイントとなります。
まとめると大規模データ処理におけるエラーハンドリングで重要なことは、システム要件に応じて、許容できるエラー率や数のしきい値を定めることと、エラーが発生した際にも、失敗した箇所から処理を再開し、それまでの処理結果を活用することとなります。
オーケストレーターとなる AWS サービス
今回のケースにおいてもワークフローサービスである AWS Step Functions が活躍します。AWS Step Functions 自体の説明については ワークフローパターン前編の[オーケストレーターとなる AWS サービス] に任せます。
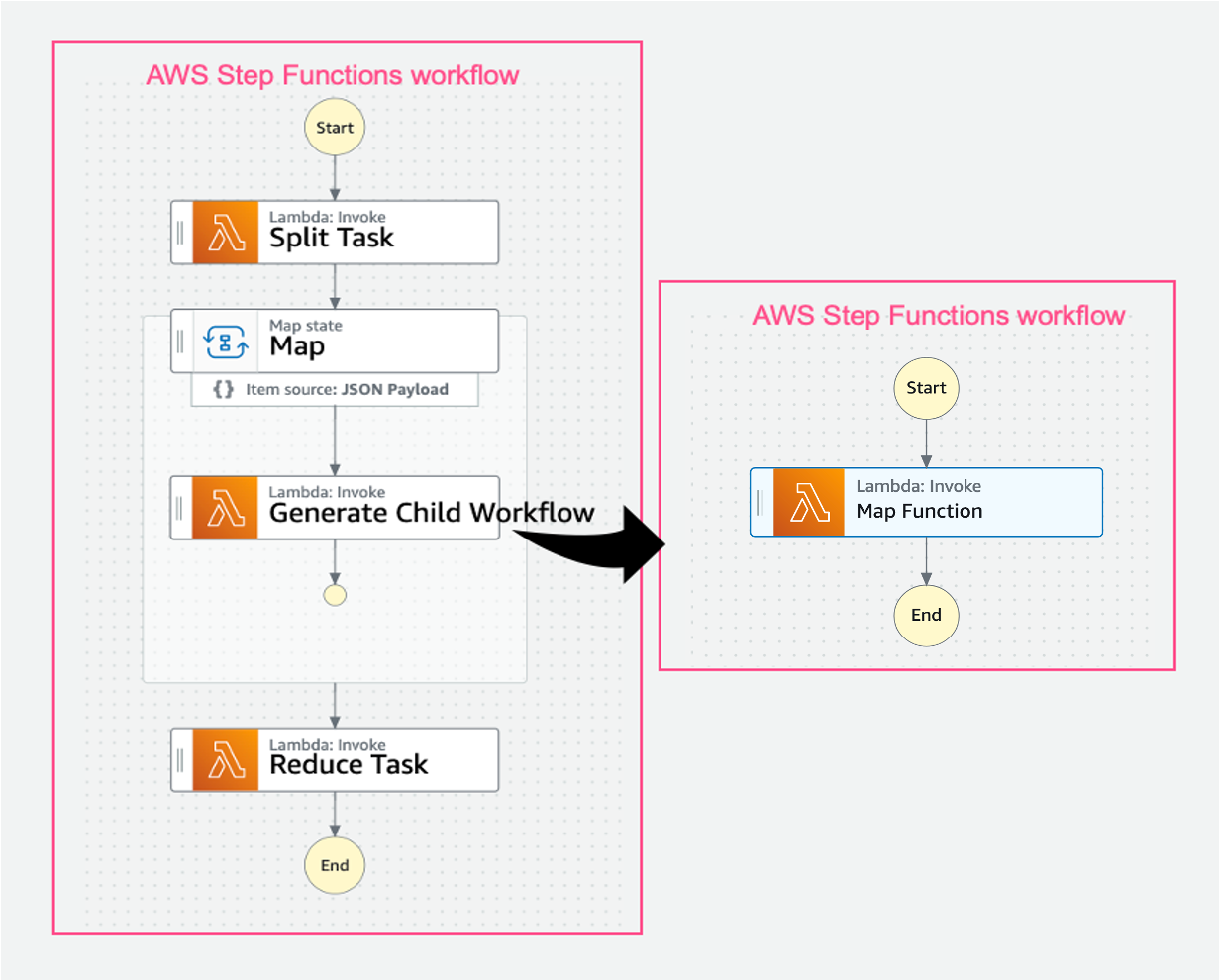
前回は Step Functions の 基本機能について説明しましたが、Step Functions には大規模データ処理を行うための機能である Distributed Map があります。Distributed Mapは、Amazon S3 にあるデータなどを対象に、最大 1 万並列で子ワークフローを生成・実行することができる機能になります。この機能によって、大規模並列実行ができるようなったことはもちろん、そのためのデータ分割及びデータ集約の処理についてもサービス側で行われ、 マネージドで S3 からの取得・分割、 S3 への保存が実行されます。
具体的に説明すると、従来は以下の図のように、データ分割のためのプログラムを自前で用意し、1 万並列の子ワークフローの生成を自前で実施し、結果の集約のためのプログラムを自前で用意する必要がありました。
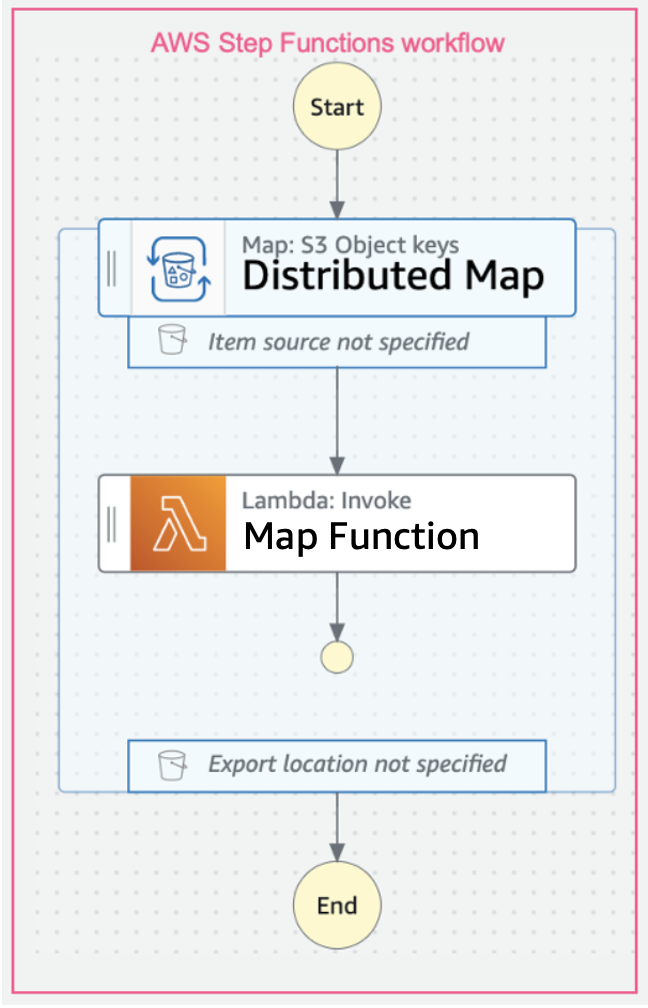
Distributed Map を使うと、以下の図のように、本来やりたかった子ワークフロー内のビジネスロジックのみの記述で 分散並列処理 を実現することが出来ます。
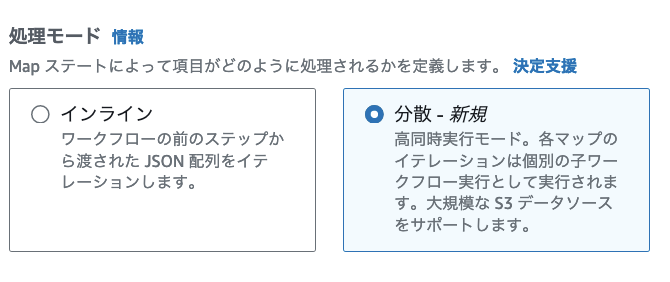
このように、大規模データ処理を行うとなると Hadoop や Spark の利用が必要となり、専用の文法を身につける必要がありましたが、アドホックに比較的簡易な分散処理を行いたいだけのためだけに、Hadoop や Sparkを 学ぶのは Too Much なケースにおいては、Distributed Map を用いることで容易に簡易的な大規模データ処理を行えます。
Distributed Mode の利用方法としては、Map State で Processing mode を Distributed にするだけです。
AWS Step Functions で実現するエラーハンドリング
先程述べた 大規模データ処理ワークフロー のユースケースにおいても、ワークフローにおける基本的なエラーハンドリングが有効であり、 ワークフローパターン前編の[ステートマシン呼び出し側でのエラーハンドリング] であるイベントの退避と [ステートマシン内でのエラーハンドリング] であるリトライ or キャッチ を参照の上、実装することを推奨します。上記のワークフローにおける基本的なエラーハンドリングを前提とし、以下では 大規模データ処理ワークフローに固有のエラーハンドリングについて紹介していきます。
冒頭のパターン特性でも申し上げた通り、大規模データ処理におけるエラーハンドリングで考慮すべきポイントは、許容できるエラー率を定めることと、重複する処理を極力行わないことです。これらを Step Functions で実現する方法を紹介します。
今回サンプルで利用するステートマシーンの設定は以下のとおりです。
- 親ワークフローは Standard Mode での実行
- 子ワークフローは (実行履歴の保持数とコストメリットを考慮し) Express Mode での実行
- 同時実行制限は 1,000 (AWS Lambda のデフォルト Quota 数)
- バッチサイズ 2
分散処理の許容できるエラーしきい値を定めるエラーハンドリング
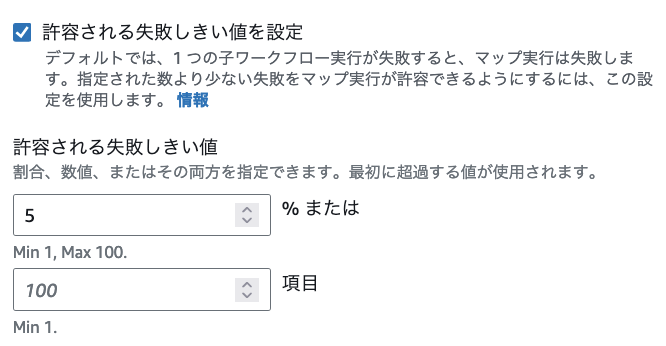
分散処理の中でエラー比率を管理して、必要に応じた処理の中断をするのはオーケストレーターである Step Functions が持つ機能で実現可能です。設定についてもコンソール上の Workflow Studio から可能となっており、ユーザーが決めることは、以下の図のように比率またはエラーアイテム数に応じた分散処理全体としてのエラーのしきい値を定めるだけです。以下の画像は 5% を許容できるエラーのしきい値としています。
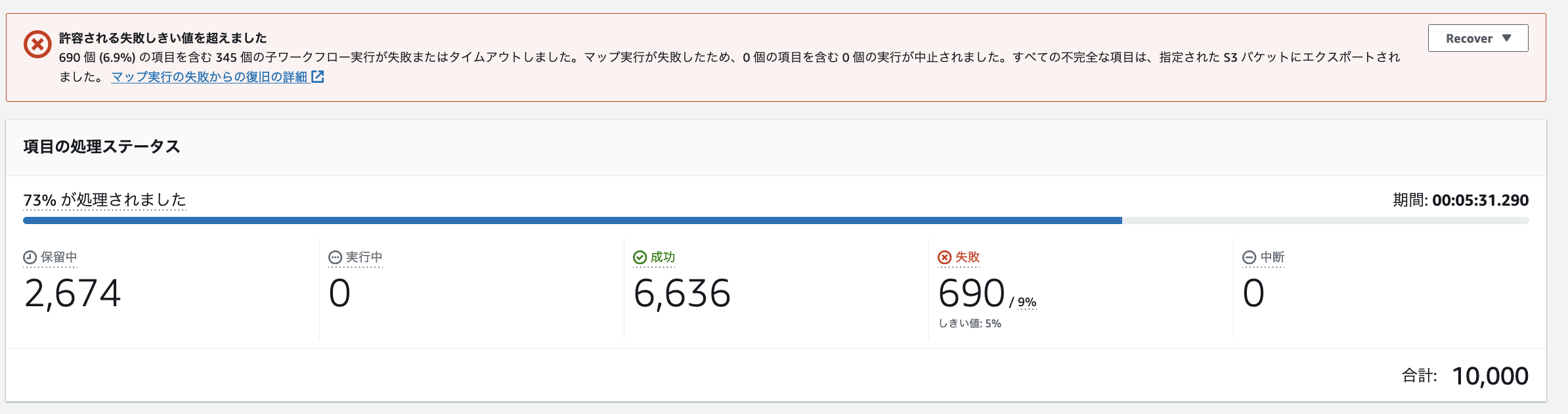
しきい値超えたエラーが発生した場合
上記の 5% のしきい値の設定を行った上で、しきい値超えたエラーが発生した際には、以下のように途中で実行が中断されます。
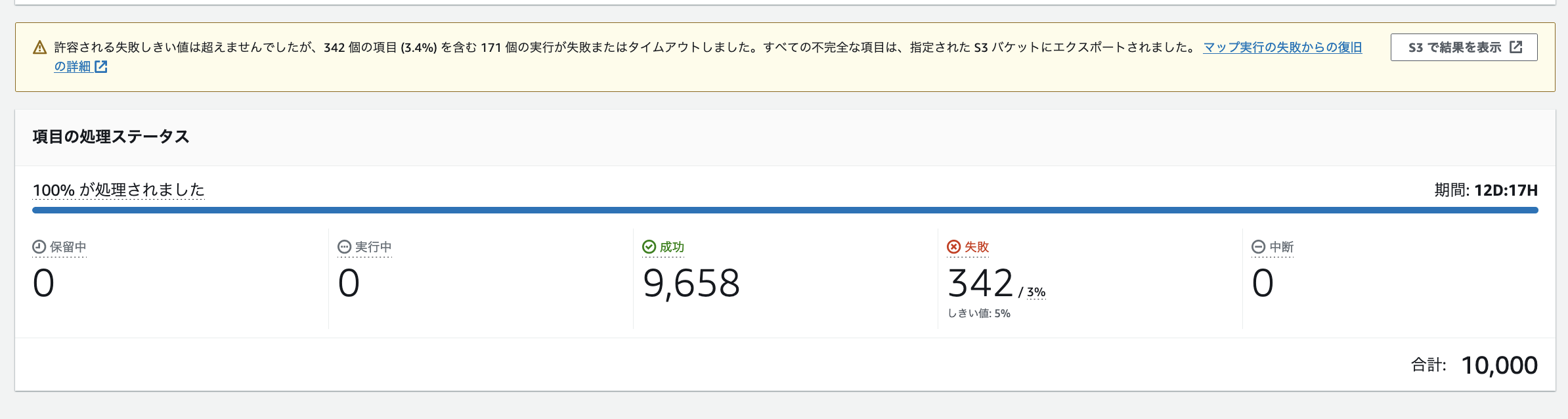
しきい値内に収まった場合
一方しきい値内に収まったときは、そのまま成功のフローとして処理が進みます。
リドライブによる失敗した箇所から処理を再開するエラーハンドリング
Step Functions は Web API パターン で紹介したワークフロー全体のリトライとは別に、失敗した箇所から再開する「リドライブ」と呼ぶ機能があります。通常のリトライであれば、ワークフロー全体を先頭から再度実行する挙動になりますが、リドライブ を利用することで、失敗した箇所から実行を再開することが可能です。
これによって分散処理や外部 API 呼び出しなど再実行を避けたい処理が含まれるワークフローにおいて、再実行を避けたいステップが完了した後に、一時的なエラーによってワークフロー全体としての処理が失敗してしまった場合でも、それらの処理を再実行する必要なく、完了した後のエラーが発生した箇所から再開することが可能です。
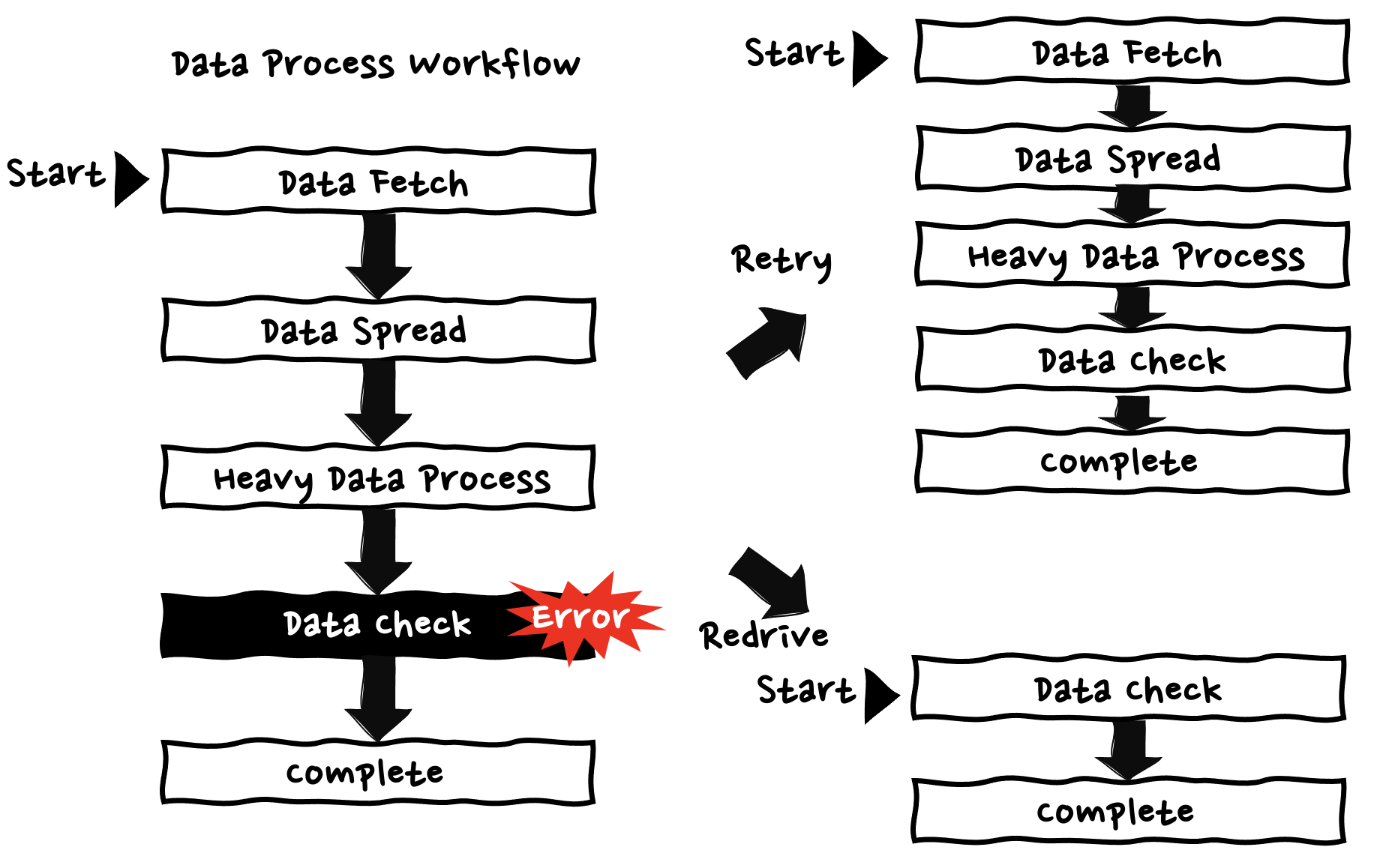
リドライブの実行方法
また Distributed Map 内で、エラーのしきい値超えて処理が中断された場合におけるリドライブは、失敗した子ワークフローと未実行のワークフローのみが再実行の対象になり、それまでの成功処理結果はそのまま活用することが可能です。リドライブの実行方法は、実行後エラー終了したワークフローの結果画面から以下の画像のように行います。
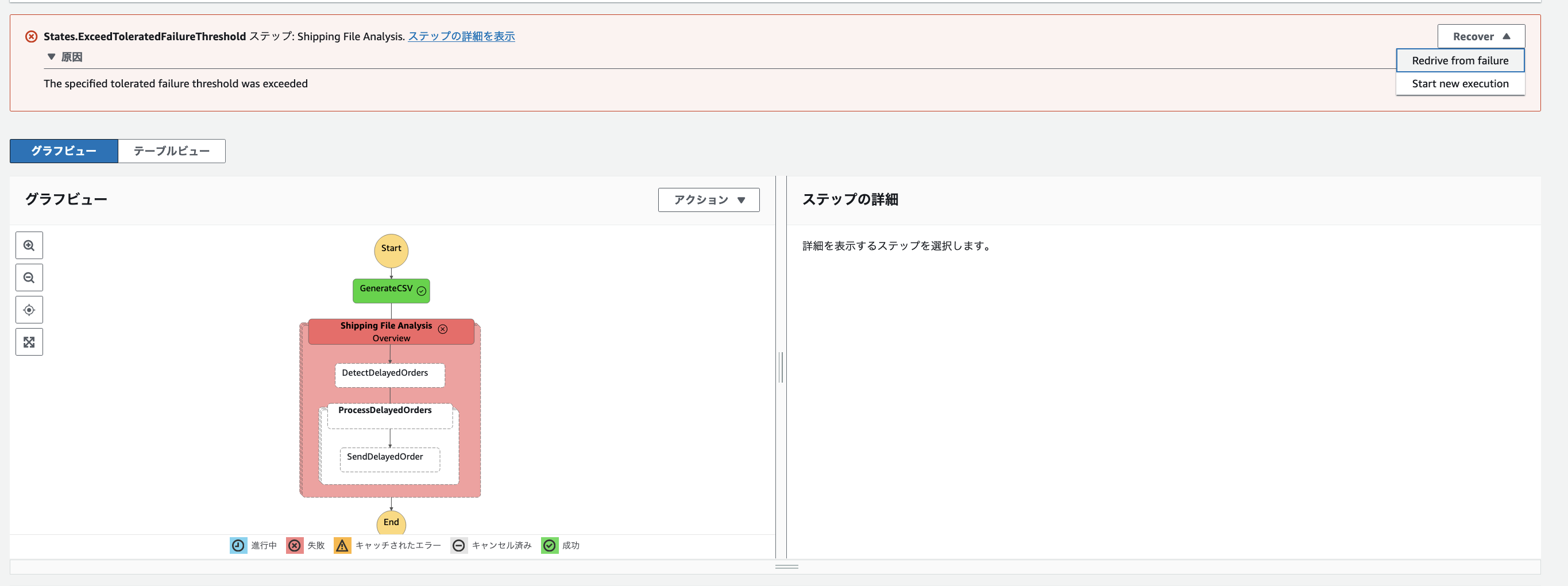
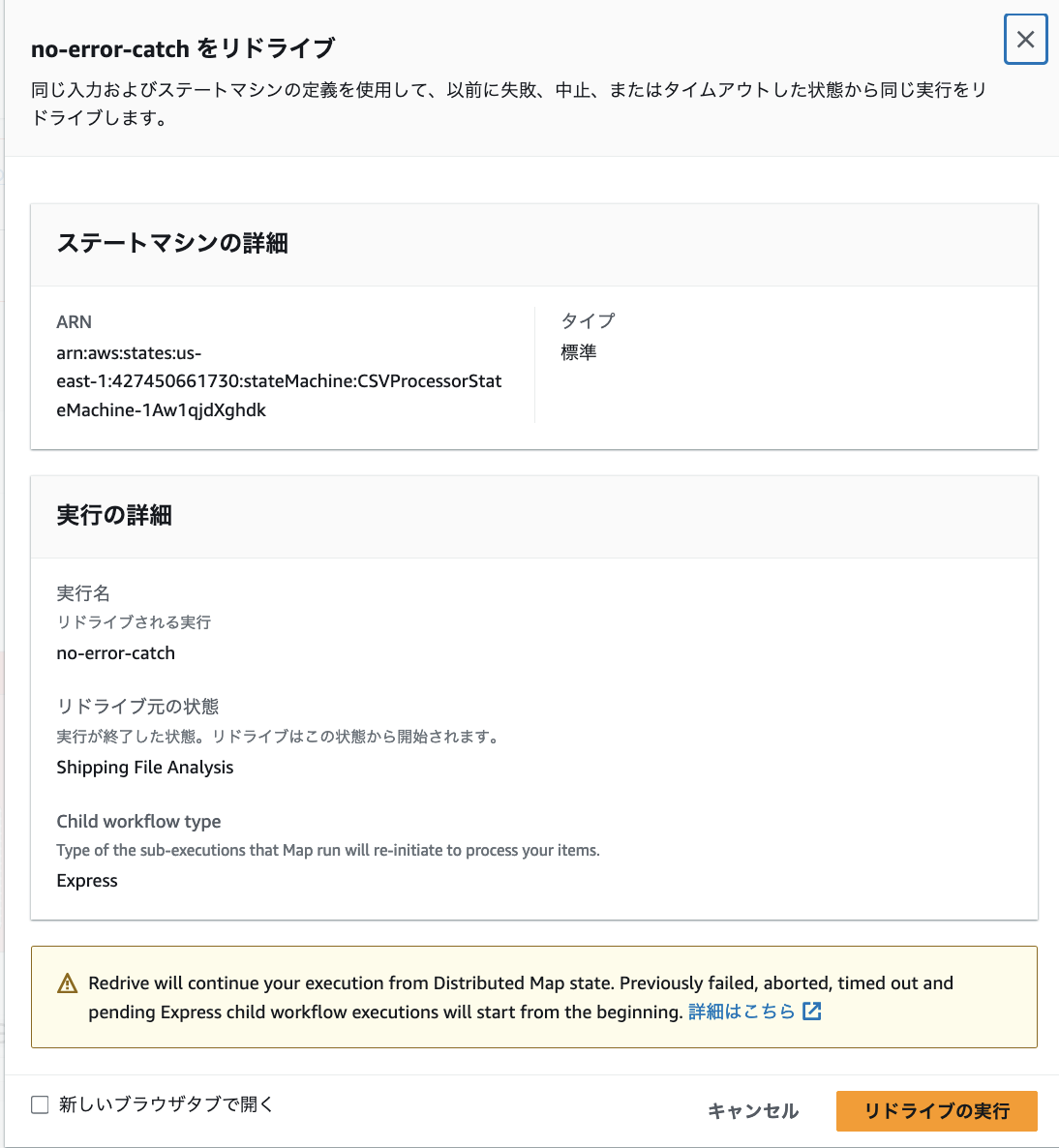
検証
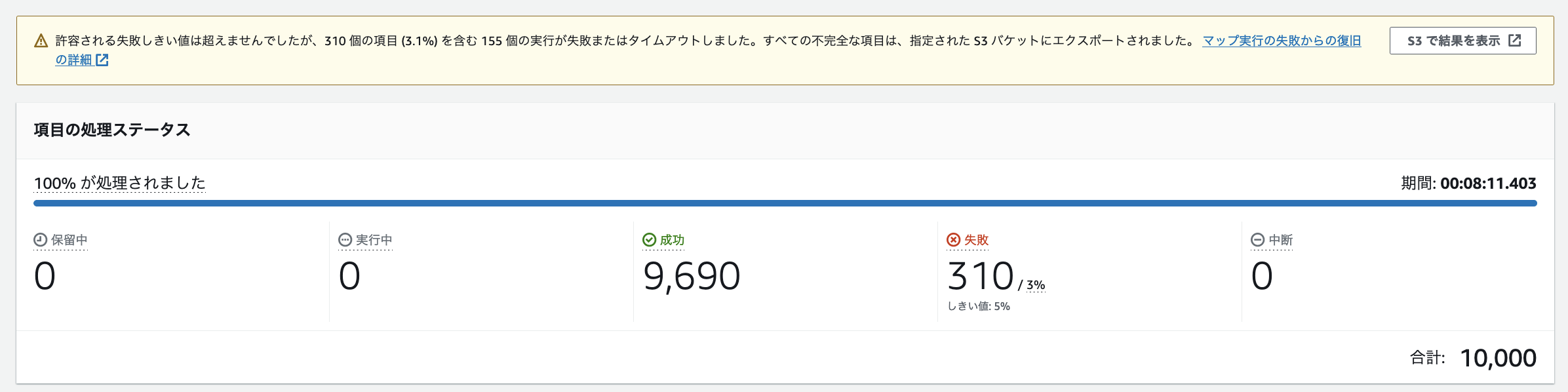
参考として、以下の許容可能なエラーのしきい値である 5% を超えて、失敗となったワークフローにて検証を行います。画像は、692 個のデータがエラーとなり、2,710 個のデータが未処理である結果を表しています。こちらのワークフローに対してリドライブを実行したのが次の画像です。
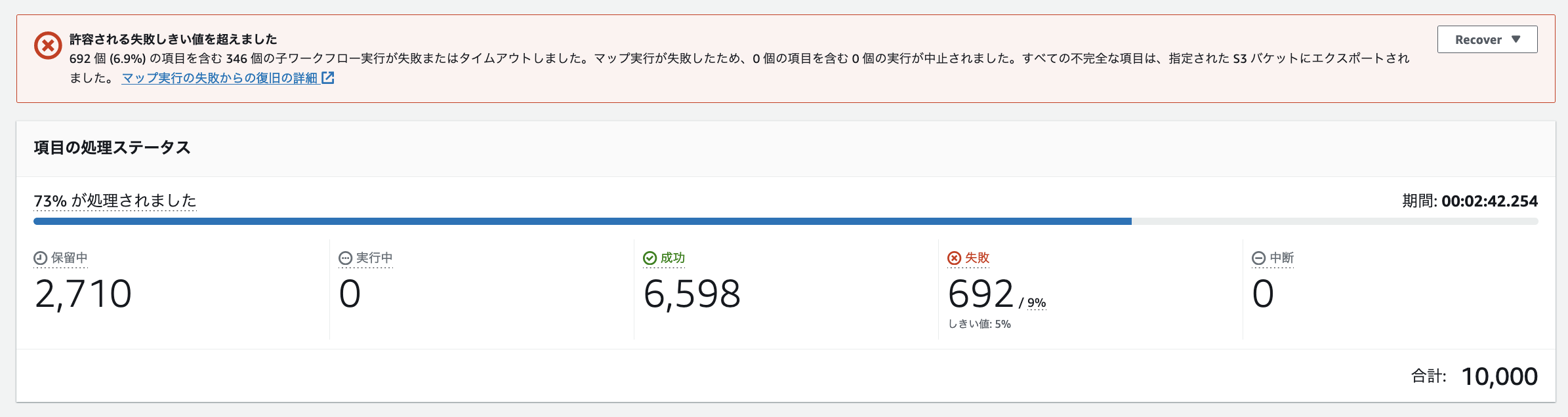
検証結果
エラーとなった 692 個のデータと、未処理の 2,710 個のデータを対象に再度処理が実行され、エラーとなったワークフローのデータ数が 310 個であり、許容可能なエラーのしきい値である 5% を下回ったため、成功として処理されています。
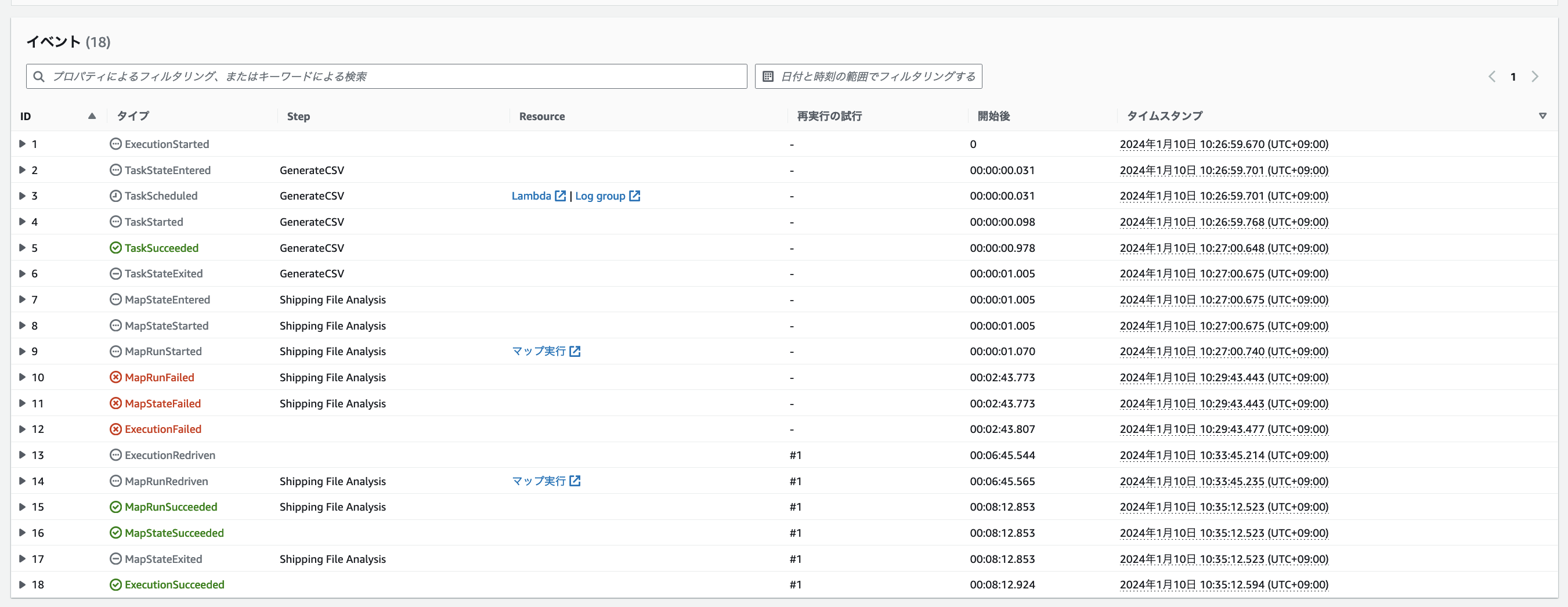
実行履歴
以下の画像がワークフローとしての実行履歴です。
このようにリドライブは、ワークフロー全体の観点から見て、失敗した箇所からの再開や、また分散処理内におけるエラーの場合は失敗したデータのみのリトライ制御を行うことで、失敗時点までのフロー処理の結果を活用することができるようになり、効率的なリトライを用意に実現することができます。
まとめ
今回は大規模データ処理のユースケースにおけるエラーハンドリングについて紹介しました。Step Functions の Distributed Map を利用すると、大規模データ処理がドラッグ & ドロップと Lambda などの従来のプログラミングモデルで実現出来ます。
大規模データ処理ワークフローパターンの特性として、一回あたりの所要時間またはコストが膨大に必要になります。このような大規模データ処理におけるエラーハンドリングで重要なことは、必要な結果を得るための十分なデータ量を見極めることと、リトライの際に重複する処理を極力行わないことになります。これらについては、Distributed Map を利用いただくことで許容できるエラー率 または 数をコンソール上から指定することと、リドライブを行うことで、簡単に実現できる大規模データ処理をより堅牢なものにすることが可能です。
最後に
以上で全 6 回にわたるサーバーレスアプリケーション開発におけるエラーハンドリング シリーズ終了になります。
今回のシリーズを通じて伝えたかったことは、サーバーレスサービスが活用される頻出ユースケースにおける、エラーハンドリングパターンの紹介と、AWS のサーバーレスサービスを利用することで、エラーハンドリングのベストプラクティスの実装が AWS サービスにオフロード出来ることでした。
サーバーレスサービスを利用することで、本来自前でアプリケーションコードとして実装する必要がある機能を、サーバーレスサービスに行わせることができます。そのため開発者がサーバーレスーサービスを利用すると、本質的なアプリケーションロジックに集中するだけで、従来どおりインフラレベルの高可用性はもちろん、システム整合性の観点においても品質の高いアプリケーションをリリースできることができます。
本シリーズを通してお読みいただくことで、この点について理解頂き、今まで以上にサーバーレスの強力さを感じていただけると非常に嬉しく思います。お読み頂いた皆様、お時間を頂きありがとうございました。
サーバーレス学習のための関連資料
筆者プロフィール
大磯 直人
アマゾン ウェブ サービス ジャパン合同会社
ソリューションアーキテクト
インターネット・Web サービスを提供されるお客様に対して技術支援を行っています。好きな食べ物は 肉・寿司・ラーメン です。空き時間は永遠に YouTube を見ています。好きな AWS サービスは AWS StepFunctions です。

Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages