サーバーレスアプリケーション開発におけるエラーハンドリング ~ ワークフローパターン前編 ~
2024-01-04 | Author : 大磯 直人

はじめに
今回はワークフローにおけるエラーハンドリングを AWS で実現する際に、抑えておくべきポイントについて紹介します。
今回取り扱うワークフローは、ワークフロー全体で各々のステートが相互に整合性及び一貫性を持つ必要があるもの (ステート分散ワークフロー) と、大規模なデータ処理を行うものと 2 つになります。前編、後編に分けて、それぞれのパターンに対してのエラーハンドリングの手法についてご紹介します。
ステート分散ワークフローのユースケースでは、Saga パターンと分散トランザクションについてご説明していきます。本シリーズの オープニング記事 でもサーバーレスエラーハンドリングの基礎と絡めてご説明しておりますので、またご覧になられていない方は、そちらからご覧頂けると理解が深まると思います !
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
ユースケース
ワークフローパターンは、条件分岐を含むシーケンシャンルなステップの集合です。それらのハンドリングを一つのプログラムモジュールで実現しようとすると、条件判断や、エラーハンドリング、リトライ、などのビジネスロジック外の本質的ではないコードが多く記述されることになり、また単一のモジュールにすべての処理をまとめると、各々の処理が密結合になるリスクなどもあります。
こういったリスクを排除するために、ワークフローエンジンを利用し、各処理単位で独立したタスクに切り出したプログラムモジュールを組み合わせて、本質的ではないタスク間の連携処理については、ワークフローエンジンの設定や関数を利用することで、ワークフローが抱える複雑性を軽減させたりします。
切り出された各タスクは、本質的なビジネスロジック実行単位で独立していて、細かいプロビジョニングが可能になる点において、ワークフロー処理も、サーバーレスと相性の良いユースケースになります。
パターン特性
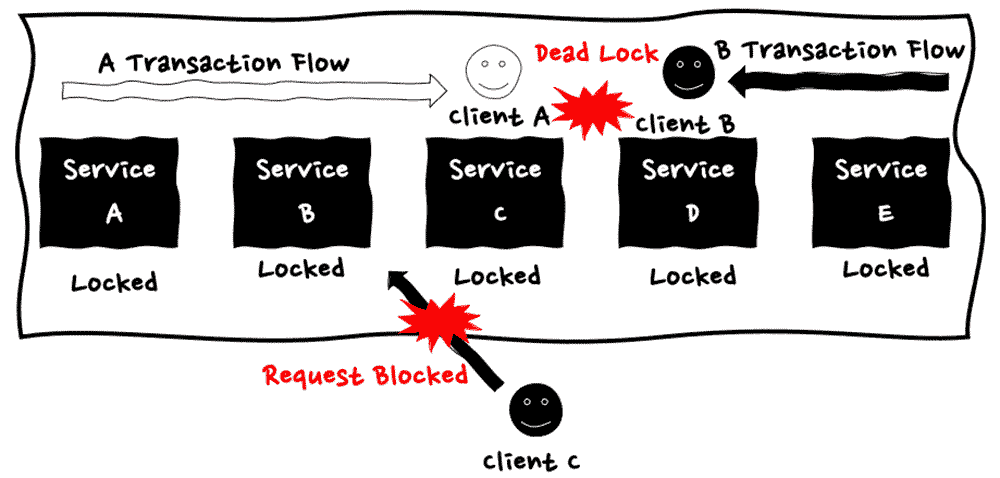
ステート分散ワークフローパターンにおける特性として、分散アプリケーションとステートの管理が挙げられます。
先程述べたように、ステート分散ワークフローパターンでは、緊密な結合を回避するために、処理単位で独立したタスクへの切り出しを行いますが、その事によってタスク間におけるデータベースの操作を行う際に、ACID 特性 の担保が難しくなる問題が発生します。例えば、EC サイトであれば、商品の購入のフローおいて、在庫の確保、ポイント利用の計算、決済の実施、を行うとなると、3 つのサービス間でアトミックにデータの変更をどのように行う必要があるかと思います。こういった問題への対策の一例として、タスクごとに異なるデータベースを参照する場合、2 フェーズ コミットなどの利用を行い、タスク間のデータ連携及びタスク間で共有されるデータの論理的な一貫性の維持を実現するなどの方法が取られてきました。
しかしシステムへの役割が高度化し、一つのワークフローが長時間実行されるようになった際に、この図のように、トランザクションの存続期間が長くなることで、一つの実行フローが複数のサービスのデータベースをロックしてしまい、他の処理をブロックしてしまうような問題や、互いに他のプログラムの終了待ちとなるデッドロックが発生します。
このように独立した複数のタスクを横断する処理フローにおいては、複数タスクを束ねるワークフロー全体として、各タスクが操作するデータ同士の論理的な整合性の担保と、各サービスにおけるロック時間の増大についての課題を抱えています。こういった課題への対応として、分散システムにおけるトランザクション処理におけるパターンの一つとして、Saga パターンがあります。
Saga パターンとは、大規模な分散アプリケーションでのトランザクション処理において、ステートの一貫性を維持しながら並列実行を実現するトランザクション処理手法であり、特にステート分散ワークフロー管理や長い処理の連鎖を必要とする場面で有用です。
Saga パターンはトランザクションの成功または失敗 (エラー) によって、2 つの異なる経路を辿ることができます。
エラーが発生した場合に前のトランザクションステップを元の状態に戻すための逆操作を実行する必要がありますが、その際にタスクをまたがった、トランザクションの管理を行う必要があります。その際にはトランザクションをロールバックする代わりに、補償トランザクションを実行して、正常系の処理を打ち消す処理 (git revert のようなイメージ) を実行することで、もとの状態に戻します。
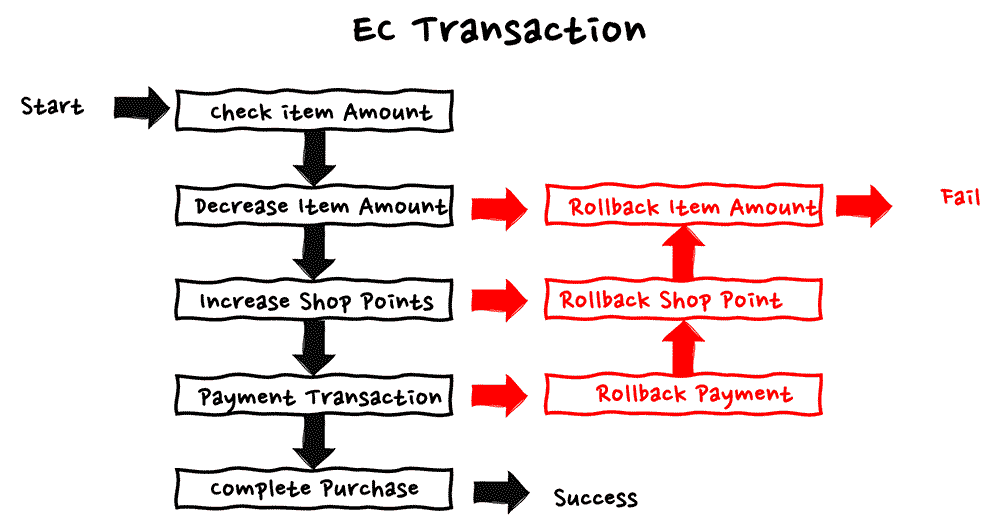
補償トランザクションは、マイクロサービスアーキテクチャや分散システムにおいて、トランザクションが失敗した場合に前の状態に戻す仕組みです。例えば、注文処理と在庫管理処理と、ポイント処理、決済処理と複数の別々のタスクにまたがるワークフローを実施していた際に、決済処理においてエラーが発生した場合、在庫管理処理の復元と、ポイント付与処理の取り消し、注文処理の取り消しを行う必要があるかと思います。
それぞれ単一のローカルトランザクションでの取り消しが出来ない場合おいては、前のステップでの操作を元に戻す処理をタスクとして用意し、正しい順序でそれらのタスクを実行する必要があります。こういった処理が補償トランザ
このような Saga パターンにおいて、順序立てた処理の実行や、エラー発生時の補償トランザクションなどを実行する際の制御のアプローチとして、コレオグラフィー、オーケストレーションがあります。
それぞれが適するユースケースとして、コレオグラフィーはシステム内のコンポーネントが分散していて、自律的に動作する場合に適しており、一方オーケストレーションは中央で制御が必要で、トランザクションの一貫性や特定の実行順序が必要な場合に有用です。
ステート分散ワークフローのように、単一のトランザクションが長期間に亘り、多くのタスクを処理する必要がある場合は、オーケストレーション型のアプローチが適しています。本ブログにおいては、オーケストレーション型のアプローチを利用する際のユースケースについて説明します。
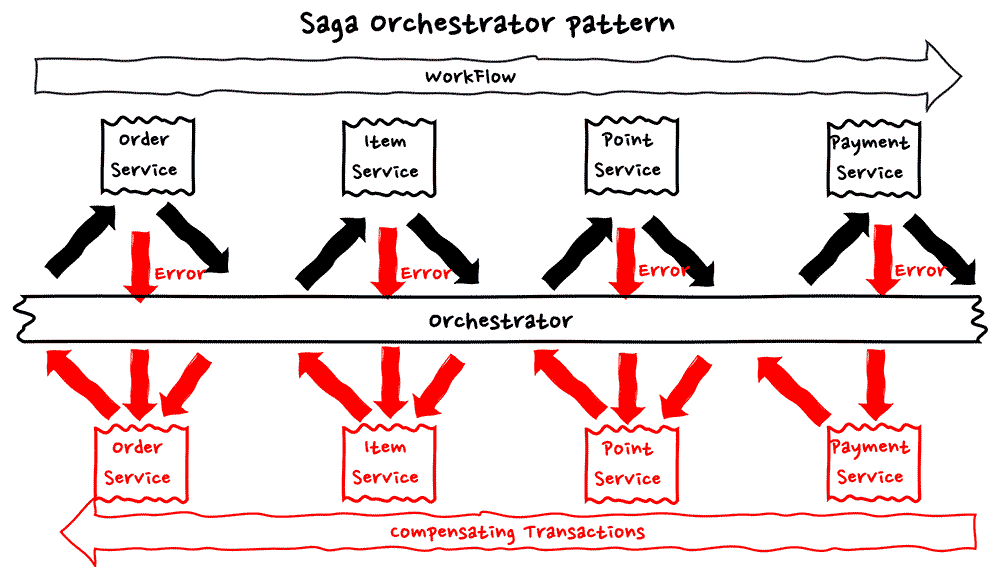
オーケストレーションは、分散システム内のプロセスやサービスの実行を中央で制御するアプローチです。データ形式の依存関係は各サービス間では存在せず、オーケストレーションサービスのみに限定されます。この図にあるように、上段にある正常系のワークフローとして左方向から右方向に進む際に、処理ごとに都度オーケストレーターを介して、処理を進めていきます。
もしなんらかのエラーが発生した際には、オーケストレーターでそれをキャッチし、下段にある補償トランザクションのフローに遷移ます。その後も右方向から左方向に向かって、正常系の処理を打ち消す処理を処理ごとに都度オーケストレーターを介して、処理を進めていく形で、ワークフローとしての処理を完了させます。
Saga オーケストレーション自体についての詳細については、公式の AWS Prescriptive Guidance の Saga・オーケストレーション の項や、 Building a serverless distributed application using a saga orchestration pattern のブログをご参照ください。
オーケストレーターとなる AWS サービス
先程述べたように、オーケストレーション型の Saga パターンを実現するには、特定の実行順序の制御や、条件分岐を中央でワークフロー全体を制御するコンポーネントが必要になります。このような、ワークフローにおける各タスクの制御を実現するサービスとして AWS Step Functions があります。
Step Functions はサーバーレスのワークフロー管理サービスです。 Step Functions を利用することで、管理不要で信頼性の高いワークフローステートマシーンを利用することが可能です。ステートマシーン内では、具体的にワークフローの機能である、条件分岐や、繰り返し、例外処理はもちろん、組み込み関数 による文字列操作やハッシュ化、Base64 化など簡単なデータ操作が可能です。
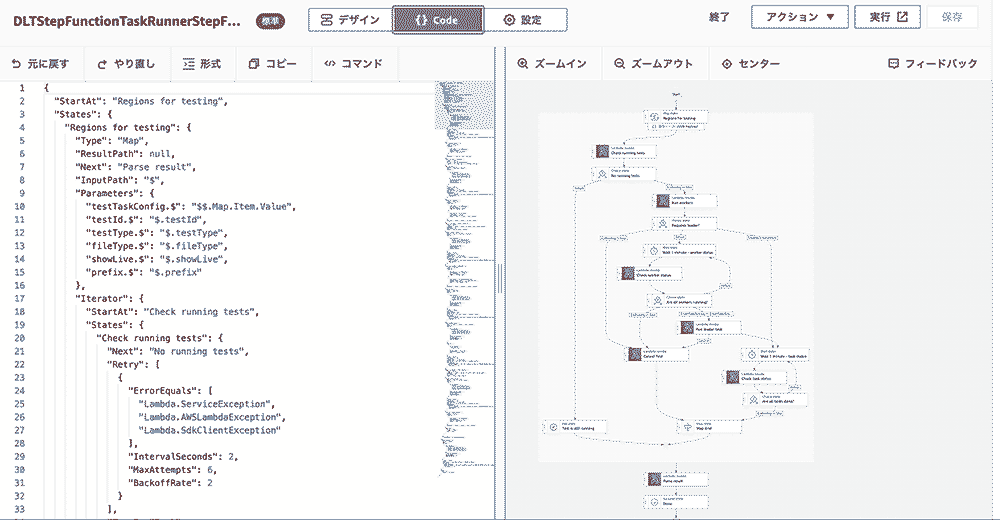
また使いやすさの視点として Workflow Studio を利用することで、GUI で簡単にワークフローの定義が行えることに加えて、Amazon State Language (ASL) と呼ばれる JSON 形式のコード管理も双方向に行う事が可能です。この図ではマネジメントコンソール上から、GUI とコード形式で、WYSIWYG にフローの定義を行えることが確認できます。また、AWS SDK と統合されており、 200 超の AWS のサービスを GUI 上から実行の定義を行なうことができます。
Step Functions は実行タイプとして、標準ワークフローと Express ワークフローの 2 種類があります。標準ワークフローはレスポンスを期待しない非同期のワークフローの際に利用され、複雑性が高く、長時間実行 (最大1年) されるようなワークフローが必要なユースケースで利用されます。一方 Express ワークフローは、ハイトラフィックのイベント処理ワークロードの場合や、クライアントがレスポンスを期待する、同期的なマイクロサービスアーキテクチャを採用したシステムの実行に利用されます。
ステート分散ワークフローでは、長時間の実行を許容する必要があるため、標準ワークフローを用いることが推奨されます。以降は標準ワークフローを対象に説明します。
AWS Step Functions で実現するエラーハンドリング
エラーハンドリングは、サーバーレスワークフロー管理ツールである AWS Step Functions でアプリケーションの信頼性を高める重要な要素です。本記事では、Step Functions を使用してエラーハンドリングを実現する方法を解説します。具体的には、ステートマシンの呼び出し側とステートマシン内でのエラーハンドリング方法に焦点を当てます。
ステートマシンの呼び出し側におけるエラーハンドリング
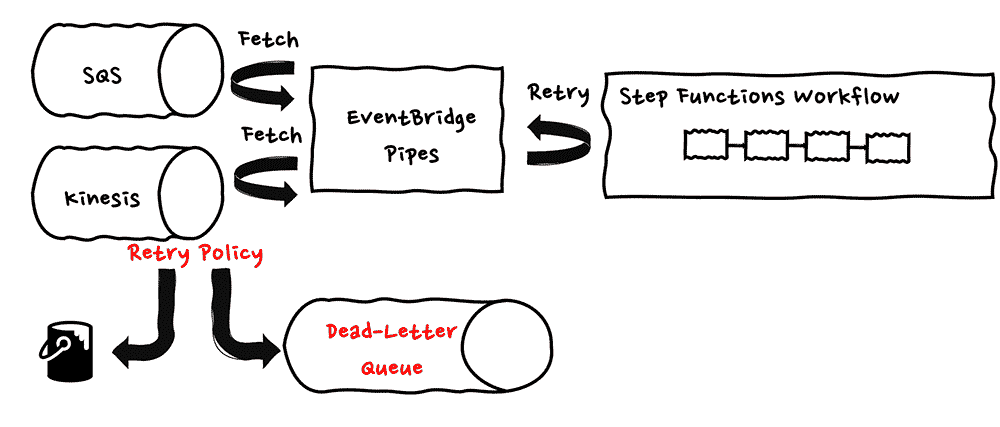
非同期的に起動される標準ワークフローにおける呼び出し時のエラーのハンドリングの特徴として、呼び出しが完了したあとの処理は、非同期である特性上制御できないため、基本的に呼び出し時のみ可能になります。
具体的に行うべきエラーハンドリングとしては、イベント駆動のデータ加工、連携処理パターン のように、非同期呼び出し元によるリトライの実施、またその後のイベントの破棄・退避になります。
Step Functions の標準ワークフローにおける呼び出しの場合は、例として Amazon EventBridge Pipes がワークフローの呼び出し元サービスになることがありますが、EventBridge Pipes の場合は、ソースとなるメッセージストアのリトライポリシーを適用し、サービス側でメッセージ保持期間までリトライを継続し、保持期間経過後、データの破棄・または DLQ へのデータの退避を行います (参考ドキュメント)。こちらの図は、EventBridge Pipes がステートマシンの非同期呼び出し元となる際の、イベントの退避を表す様子です。
ステートマシン内でのエラーハンドリング
ステートマシン内では、Pass ステートおよび Wait ステートを除くすべてのステートで、以下の例を含むランタイムエラーが発生する可能性があります。
-
ステートマシンの定義の問題 (例: Choice 状態に一致するルールがない)。
-
タスクの失敗 (例: AWS Lambda 関数の例外)。
-
一時的な問題 (例: クラウド上のネットワーク障害やサービスの障害)。
Step Functions でワークフローを構築する際に、正常系の処理のフローのみ実装され、エラー処理のタブについては未設定となっているステートマシンになりがちですが、品質の高いワークフローを実現するためには、すべてのエラーが発生する可能性があるすべてのステートにおいて、エラーハンドリングの実装が必要です。ここではステートマシン内でのエラーハンドリングの設定方法と、その際の考慮点について説明します。
ステートマシンにおけるエラーハンドリング機能について

ステートマシン内でのエラーハンドリング手法は主に 2 つで、リトライを行うか、エラーのキャッチを行い、適切なステートへフォールバックするかのどちらかになります。
リトライの詳細な定義や、フォールバック先の設定はコンソール上から可能となっており、ユーザーが最も考慮すべきポイントは、どのエラーにおいて、どちらのハンドリングを行うかという点になります。エラーの種類としては、Step Functions で発生するエラーと、タスク内で発生するエラーの 2 種類になります。どちらのエラーに対しても、文字列による完全一致によるパターンマッチになります。Step Functions で発生するエラーについては、組み込み文字列を定義されており、コンソール上からリスト形式で選択することが可能です。すべて States. プレフィックスが付いています。以下のドキュメントのエラー名一覧もご参照ください。
Step Functions のエラー処理 - AWS Step FunctionsStep Functions のエラー処理 »
タスク内で起きるエラーについてもこちらに直接文字列として登録することでエラーハンドリングを行います。タスクで起きうるエラーについては、予めハンドリング対象として登録してください。
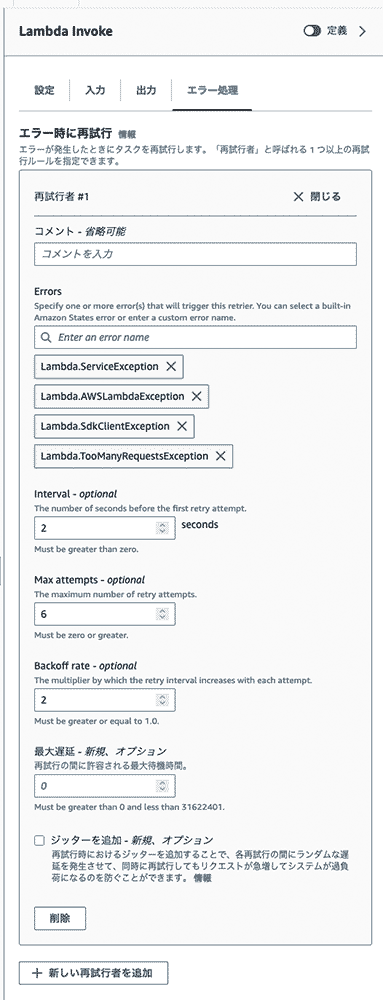
基本的な考え方として、リトライで対応可能なエラーを洗い出し、それ以外のエラーは States.ALL でキャッチするというフローで検討を行うのがシンプルです。リトライの詳細な定義や、フォールバック先の設定方法について説明すると、リトライは、Web API パターン で学習したリトライにおいて検討すべきポイントである回数と間隔についても、エクスポネンシャルバックオフやジッターがコンソール画面上から制御可能となっているため、簡単に設定できます。
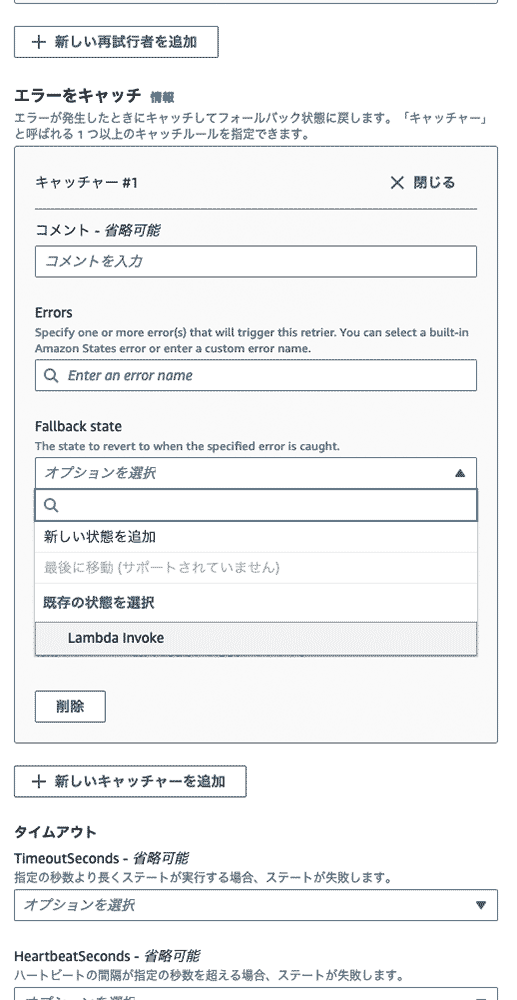
キャッチにおけるフォールバック先のステートの指定もコンソール上から選択可能です。
このように、Step Functions のコンソールで提供されているエラー処理のタブをしっかりと設定するだけで、基本的なエラーハンドリングを実現することができます。
ステート分散ワークフロー内におけるエラーハンドリングの考慮点
ステート分散ワークフローのステートマシン内におけるエラーハンドリングの考慮点の中でも重要なポイントとして、補償トランザクションフローにおけるエラーハンドリングがあります。
ステートマシン内でのエラーハンドリングは、正常フローにおけるエラーハンドリングと補償トランザクションフローにおけるエラーハンドリングと、2 種類のエラーハンドリングを行う必要があります。正常フローにおけるエラーハンドリングは、リトライによる対応か、エラーをキャッチして、異常系のステートフローに遷移し、補償トランザクションを実行するかのどちらかです。この補償トランザクション自体がエラーハンドリングである側面もありながらも、そこでもエラーが発生する可能性も考慮する必要があります。
補償トランザクション内でのエラーは、ロールバック処理が完了しないことを意味するため、システムとしてのデータの不整合につながります。このような例外的なイベントへの対応にも、当然リトライによる解決は試みるものの、それでもリカバリーできない事象の場合は、更にそのためのフローに入るなどということはなく、人的な運用によるカバーが必要になります。そのために異常系フローにおける補償トランザクションのエラーハンドリングは、リトライの実施と、エラーをキャッチして、イベントの退避、及び通知を行います。イベント駆動のデータ加工、連携処理パターン で紹介したように、データの破棄・退避を行うためには、Amazon SQS や Amazon SNS を利用したイベントを退避させるためのステートを設定してください。
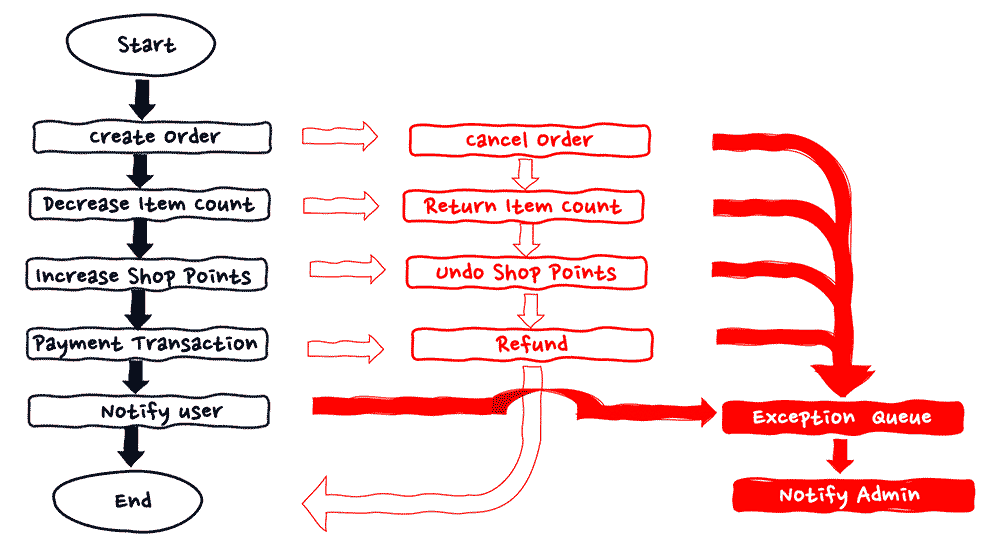
また論理的な整合性を取るためのワークフローデザインの設計を行う際に、ここまでフローが進んだ場合は、人的な対応も含めて成功の処理として扱うなどのケースもユースケースによっては存在します。具体的には、在庫も存在し、ポイントの付与も、決済も成功した。最後のユーザー通知のみ一時的な原因でリトライ期間にうまく行かなかった場合には購入自体は成功とし、人的な対応にてユーザー通知を行うなどのケースです。
この図で示すように、エラーとなった場合は全てにおいて、ロールバックのフローに入れなければ行けないというわけではなく、ビジネスにおける論理的な整合性を担保するために、ロールバックを行わないフローについても、フローのデザインの際に検討をすることを推奨します。
まとめ
今回はステート分散ワークフローのユースケースにおけるエラーハンドリングについてご紹介しました。
ステート分散ワークフローパターンのサーバーレスアプリケーションの特性として、分散アプリケーション化することによって、可用性を担保しつつデータの論理的な一貫性を担保させることが難しくなる問題がありました。こういった問題に対し、ステートの一貫性を維持しながら並列実行を実現する Saga パターンを紹介しました。中でも、単一のトランザクションが複雑で、長期間に亘り多くのタスクを処理を行うワークフローに適しているオーケストレーション型のアプローチを利用する際のユースケースについて説明しました。
オーケストレーション型の Saga パターンの実装において、ワークフロー全体を制御する AWS のサービスとして、 Step Functions があります。Step Functions で実現するエラーハンドリング手法として大きく、Step Functions の呼び出し側と Step Functions 内でのエラーハンドリングの 2 つが有りました。
呼び出し側のエラーハンドリングについても、非同期的に起動される標準ワークフローにおける呼び出し時のエラーのハンドリングについては、非同期呼び出し元によるリトライの実施、またその後のイベントの破棄・退避を行う必要がありました。
Step Functions 内でのエラーハンドリングの場合は、リトライを行うか、エラーのキャッチを行い、適切なステートへの遷移するかのどちらかになります。正常フローにおけるエラーキャッチ後の遷移先の処理は、補償トランザクションのフローへの遷移、補償トランザクションの場合は、SNS や SQS を利用して、イベントの退避、及び通知を行います。またビジネスにおける論理的な整合性を担保するために、ロールバックを行わないフローの有無についても、フローのデザインの際に検討することを推奨します。
Step Functions は、今回紹介したような複数のタスク (業務機能) を横断してステート管理をするようなワークフロー用途だけではなく、大規模データ処理のフロー管理でも使われることがあります。次回はそのようなユースケースにおけるサーバーレスアプリケーションのエラーハンドリングについてご紹介します。
サーバーレス学習のための関連資料
筆者プロフィール
大磯 直人
アマゾン ウェブ サービス ジャパン合同会社
ソリューションアーキテクト
インターネット・Web サービスを提供されるお客様に対して技術支援を行っています。好きな食べ物は 肉・寿司・ラーメン です。空き時間は永遠に YouTube を見ています。好きな AWS サービスは AWS StepFunctions です。
