





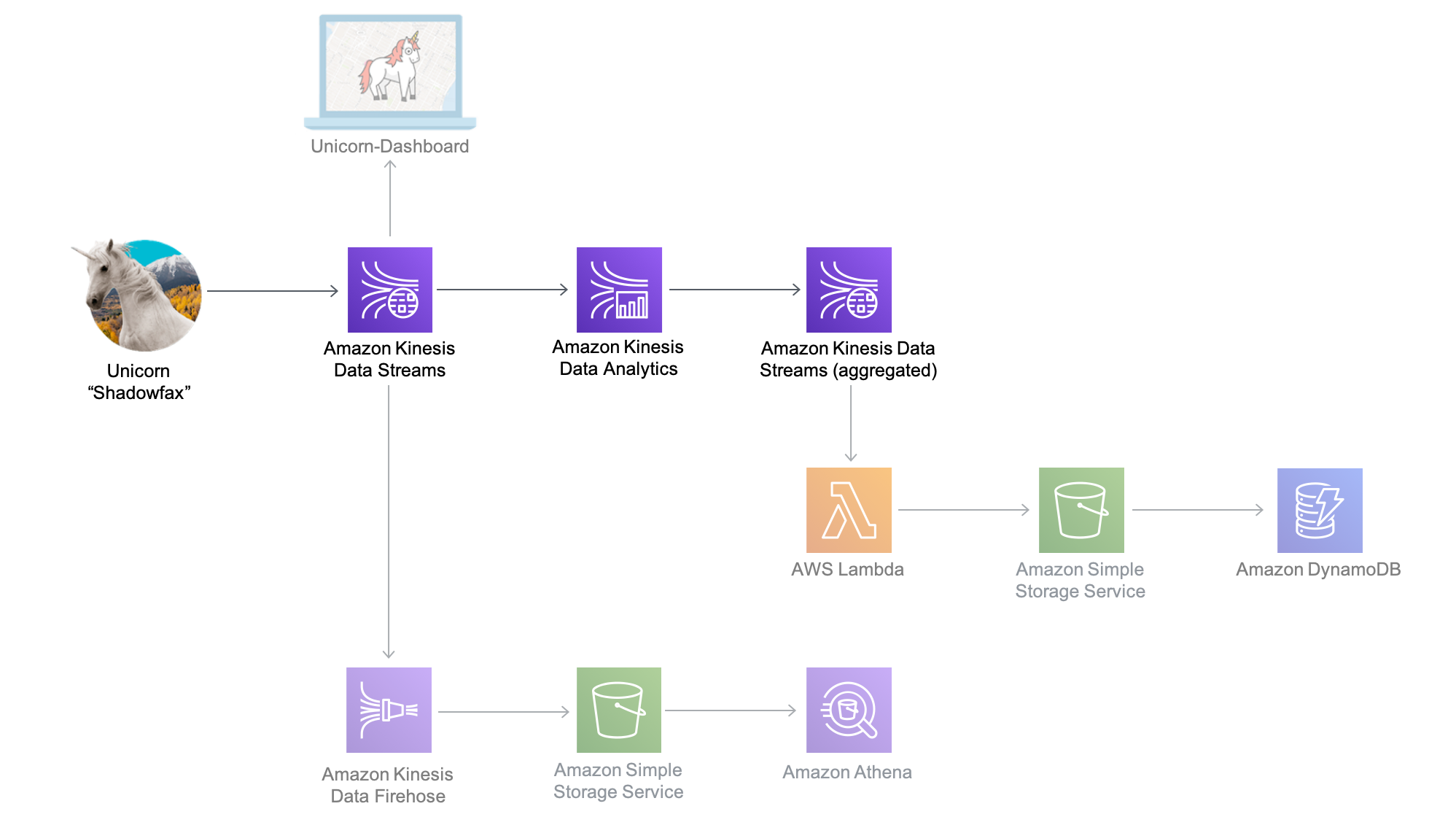
このモジュールでは、ユニコーンフリートのセンサーデータをリアルタイムで集約する Amazon Kinesis Data Analytics アプリケーションを作成します。このアプリケーションは Amazon Kinesis ストリームからデータを読み取り、その時点で Wild Ryde 上にいる各ユニコーンの総移動距離や、ヘルスポイントおよびマジックポイントの最低値および最高値を計算し、集約した統計結果を毎分 Amazon Kinesis ストリームに出力します。
このモジュールのアーキテクチャは、Amazon Kinesis Data Analytics アプリケーション、Amazon Kinesis ストリームのストリーミングソースと出力先、プロデューサーおよびコンシューマーのコマンドライン
Amazon Kinesis Data Analytics アプリケーションは、前のモジュールで作成した Amazon Kinesis ストリーミングソースから取得したデータを処理し、それを 1 分単位で集約します。毎分、アプリケーションではフリート内にいる各ユニコーンについて過去 1 分間の総移動距離や、ヘルスポイントとマジックポイントの最低値および最高値を含むデータが出力されます。こうしたデータポイントは、出力先の Amazon Kinesis ストリームに送信され、システム内の別のコンポーネントによって処理されます。
モジュールの所要時間: 20 分
使用するサービス:
• Amazon Kinesis Data Streams
• Amazon Kinesis Data Analytics
-
ステップ 1.Amazon Kinesis ストリームを作成する
Amazon Kinesis Data Streams コンソールで新しいストリームを作成し、名前には「wildrydes-summary」を入力し、シャードの数は 1 つに設定します。
a.AWS マネジメントコンソールに移動して [サービス] をクリックし、[分析] の [Kinesis] を選択します。
b.初期画面が表示されたら、[今すぐ始める] を選択します。
c.[データストリームの作成] を選択します。
d.[Kinesis ストリーム名] に「wildrydes-summary」、[シャード数] に「1」を入力して [Kinesis ストリームの作成] を選択します。
e.60 秒以内に Kinesis ストリームが ACTIVE になり、リアルタイムストリーミングデータを保存する準備が整います。
-
ステップ 2.Amazon Kinesis Data Analytics アプリケーションを作成する
前のモジュールで構築した wildrydes ストリームを読み取る Amazon Kinesis Data Analytics アプリケーションを作成します。このアプリケーションでは、次の属性を持つ JSON オブジェクトが毎分出力されます。
Name ユニコーンの名前 StatusTime Amazon Kinesis Data Analytics により提供される ROWTIME Distance ユニコーンの総移動距離 MinMagicPoints MagicPoints 属性のデータポイントの 最低値 MaxMagicPoints MagicPoints 属性のデータポイントの 最高値 MinHealthPoints HealthPoints 属性のデータポイントの最低値 MaxHealthPoints HealthPoints 属性のデータポイントの 最高値 a.お使いの Cloud9 環境が開いているタブに切り替えます。
b.プロデューサーを実行して、ストリームへのセンサーデータの出力を開始します。
./producer
アプリケーションの構築中にアクティブにセンサーデータを生成することにより、Amazon Kinesis Data Analytics によってスキーマが自動検出されます。
c.AWS マネジメントコンソールに移動して [サービス] をクリックし、[分析] の [Kinesis] を選択します。
d.[分析アプリケーションの作成] を選択します。
e.[アプリケーション名] に「wildrydes」と入力して、[アプリケーションの作成] を選択します。
f.[Connect streaming data (ストリーミングデータに接続)] を選択します。
g. [Kinesis ストリーム] で [wildrydes] を選択します。
h. 下にスクロールして [Discover schema (スキーマの検出)] をクリックし、少し待ってからスキーマが正しく自動検出されたことを確認します。
自動検出されたスキーマに以下の列が含まれていることを確認します。
列 データタイプ Distance DOUBLE HealthPoints INTERGER Latitude DOUBLE Longitude DOUBLE MagicPoints INTEGER Name VARCHAR(16) StatusTime TIMESTAMP i.[保存して続行] を選択します。
j.[Go to SQL editor (SQL エディタを開く)] を選択します。これにより、インタラクティブなクエリセッションが開き、リアルタイムの Amazon Kinesis ストリーム上でクエリを作成できます。
k.[Yes, start application (はい、アプリケーションを開始します)] を選択します。アプリケーションが開始するまでに 30~90 秒かかります。
l.以下の SQL クエリをコピーして SQL エディタに貼り付けます。
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" ( "Name" VARCHAR(16), "StatusTime" TIMESTAMP, "Distance" SMALLINT, "MinMagicPoints" SMALLINT, "MaxMagicPoints" SMALLINT, "MinHealthPoints" SMALLINT, "MaxHealthPoints" SMALLINT ); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM "Name", "ROWTIME", SUM("Distance"), MIN("MagicPoints"), MAX("MagicPoints"), MIN("HealthPoints"), MAX("HealthPoints") FROM "SOURCE_SQL_STREAM_001" GROUP BY FLOOR("SOURCE_SQL_STREAM_001"."ROWTIME" TO MINUTE), "Name";
(クリックして拡大)
m.[Save and run SQL (SQL を保存して実行)] を選択します。毎分、集約データを含んだ新しい列が表示されます。列が表示されるのを待ちます。
n.送信先リンクをクリックします。
o.[Connect to a destination (送信先に接続)] をクリックします。
p. [Kinesis ストリーム] で [wildrydes-summary] を選択します。
q.[In-application stream name (アプリケーション内のストリーム名)] で [DESTINATION_SQL_STREAM] を選択します。
r.[保存して続行] を選択します。

(クリックして拡大)
-
ステップ 3.ストリームからメッセージを読み取る
コマンドラインコンシューマーを使用して Kinesis ストリームのメッセージを表示し、集約データが毎分送信されていることを確認します。
a.お使いの Cloud9 環境が開いているタブに切り替えます。
b.コンシューマーを実行し、ストリームからセンサーデータの読み取りを開始します。
./consumer -stream wildrydes-summary
コンシューマーでは、Kinesis Data Analytics アプリケーションから毎分送信されるメッセージが表示されます。
{ "Name": "Shadowfax", "StatusTime": "2018-03-18 03:20:00.000", "Distance": 362, "MinMagicPoints": 170, "MaxMagicPoints": 172, "MinHealthPoints": 146, "MaxHealthPoints": 149 } -
ステップ 4.プロデューサーを使って実験する
ダッシュボードとコンシューマーを監視しながら、プロデューサーを停止して開始します。さまざまなユニコーン名で複数のプロデューサーを開始します。
a.お使いの Cloud9 環境が開いているタブに切り替えます。
b.Control + C キーを押してプロデューサーを停止し、メッセージの出力が停止したことを確認します。
c.プロデューサーを再度開始し、メッセージの出力が再開されたことを確認します。
d.[+] ボタンを押し、[New Terminal (新しいターミナル)] をクリックして新しいターミナルのタブを開きます。
e.新しいタブでプロデューサーの別のインスタンスを作成します。特定のユニコーン名を入力すると、コンシューマーの出力に
両方 のユニコーンのデータポイントが表示されます。./producer -name Bucephalus
f. 複数のユニコーンが出力されていることを確認します。
{ "Name": "Shadowfax", "StatusTime": "2018-03-18 03:20:00.000", "Distance": 362, "MinMagicPoints": 170, "MaxMagicPoints": 172, "MinHealthPoints": 146, "MaxHealthPoints": 149 } { "Name": "Bucephalus", "StatusTime": "2018-03-18 03:20:00.000", "Distance": 1773, "MinMagicPoints": 140, "MaxMagicPoints": 148, "MinHealthPoints": 132, "MaxHealthPoints": 138 } -
まとめとヒント
🔑Amazon Kinesis Data Analytics を使用すると、SQL を使用してストリーミングデータのクエリやストリーミングアプリケーション全体の構築を行うことができます。これにより、実用的なインサイトを得て、ビジネスやお客様のニーズにすばやく対応することができます。
🔧 このモジュールでは、Kinesis ストリームからユニコーンデータを読み取り、概要列を毎分出力する Kinesis Data Analytics アプリケーションを作成しました。


次のモジュールでは、AWS Lambda を使用して、作成済みの Amazon Kinesis ストリーム