Amazon Redshift データ共有
データをコピーすることなく、ウェアハウス間でデータを安全に共有
メリット
-
Amazon Redshift データベースに保存されたらすぐに、複数のウェアハウスでデータを使用できるようにします。1 つのウェアハウスを使用してデータを抽出、変換、ロード (ETL) すると、組織内および複数の AWS リージョン間でデータにアクセスできます。データエンジニアは、ETL 処理でデータを複数の場所に取り込む複数のパイプラインを構築して維持する必要はありません。
-
さまざまなサイズ (ノードまたは RPU)、タイプ (プロビジョンド vs サーバーレス)、料金プラン (オンデマンド vs リザーブドインスタンス) など、さまざまなコンピューティングでデータにアクセスできます。チーム、アプリケーション、またはワークロードのコストパフォーマンスのニーズに基づいてウェアハウスを選択してください。チームごとの使用状況の追跡とモニタリング、コスト管理、透明性の向上
-
チームがデータをある場所から別の場所に移動またはコピーする必要がないため、データサイロやデータの重複を排除できます。チームはソースの時点でライブデータに基づいて共同作業を行い、データに基づいて迅速に行動できます。アクセスは AWS Lake Formation によって一元管理されるため、きめ細かなアクセスコントロールが可能です。
-
手動のライセンス処理やウェアハウスへの ETL オペレーションを行う手間をかけずに、サードパーティープロバイダーのデータに安全かつ簡単にアクセスできます。Amazon Redshift から AWS データエクスチェンジのデータセットにサブスクライブするだけです。データプロバイダーは、わずか数クリックでデータを顧客のウェアハウスで利用できるようにすることで、データを収益化し、顧客に価値を提供できます。
Amazon Redshift データ共有
Amazon Redshift データ共有により、データを移動またはコピーすることなく、組織内、AWS リージョン、さらにはサードパーティプロバイダー間でデータを共有できます。複数のデータウェアハウスを使用して同じ Redshift データベースから読み取りと書き込みを行うことで、Amazon Redshift が提供する使いやすさ、パフォーマンス、コスト上のメリットを、マルチウェアハウスのデータメッシュアーキテクチャにまで広げることができます。組織内および組織全体で最新のライブデータに即座にアクセスできるため、複数の ETL (抽出、変換、読み込み) パイプラインが不要になり、データに関するコラボレーションが可能になり、洞察を得るまでの時間が短縮されます。さらに、ETL にはタイプ/サイズの異なる複数のウェアハウスを使用できるため、書き込みワークロードのコストパフォーマンスのニーズに基づいてウェアハウスを調整できます。Amazon Redshift のユーザーは、何千ものサードパーティーのデータセットを収容する AWS のマーケットプレイスである AWS Data Exchange との統合により、サードパーティーのデータセットを簡単かつ安全にライセンスして、Redshift データベース内のデータと組み合わせて総合的な分析を行い、新しいデータ収益化の機会を増やすことができます。
ユースケース
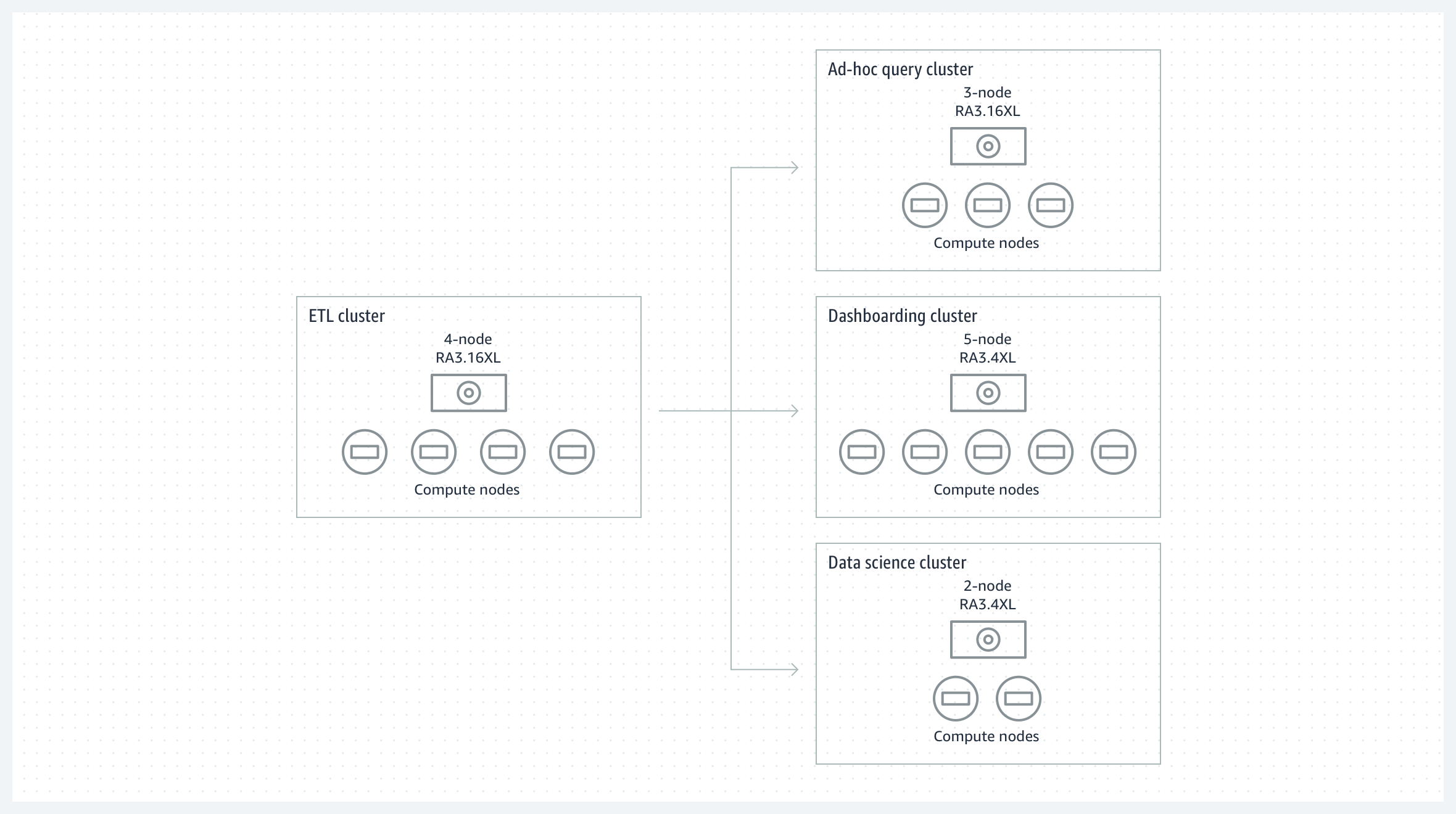
ワークロードの分離と課金可能性
ETL クラスターからのデータをハブスポークアーキテクチャー内の複数の分離された BI および分析クラスターと共有して、読み取りワークロードの分離とオプションでのコストのチャージバックを提供します。それぞれの分析クラスターは、料金パフォーマンスの要件に応じてサイズを設定することができ、新しいワークロードを簡単にオンボーディングできます。
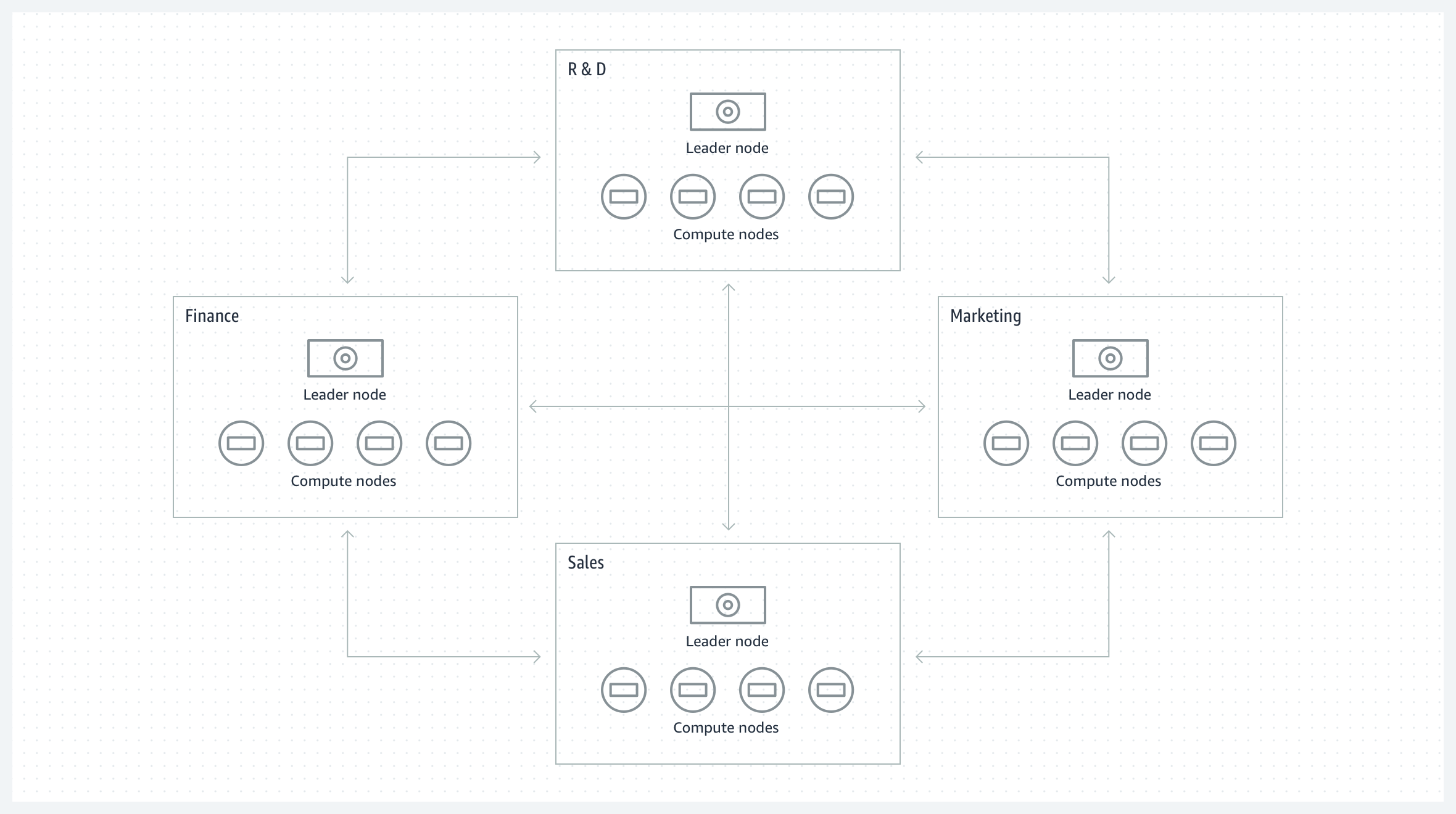
グループ間のコラボレーション
それぞれが個別の Amazo Redshift クラスターを維持する複数のビジネスグループ間でデータを共有し、より広範な分析とデータサイエンスのために連携します。それぞれの Amazon Redshift クラスターは、一部のデータのプロデューサーになることができますが、他のデータセットのコンシューマーになることもできます。
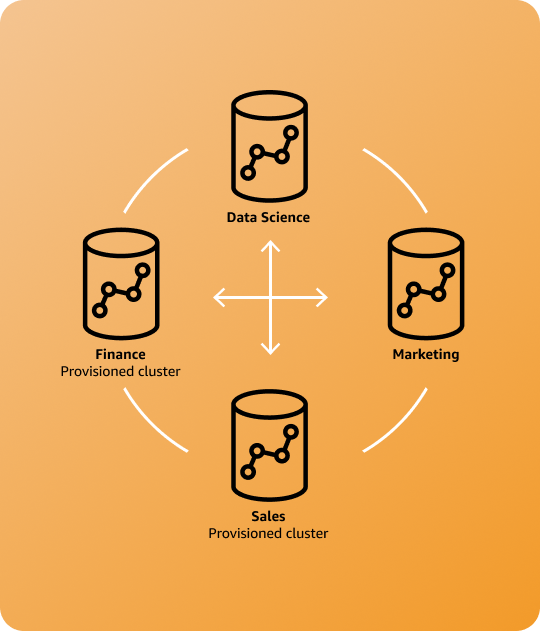
サービスとしてのデータと分析
組織内のさまざまなグループ間で、あるいは組織外の外部関係者と、サービスとしてデータを共有します。

開発の俊敏性
数回クリックするだけで、さまざまな種類やサイズのプロビジョニングされたクラスターやサーバーレスワークグループ間でデータを読み書きできます。
