What is Data Labeling?
What is data labeling?
In machine learning, data labeling is the process of identifying raw data (images, text files, videos, etc.) and adding one or more meaningful and informative labels to provide context so that a machine learning model can learn from it. For example, labels might indicate whether a photo contains a bird or car, which words were uttered in an audio recording, or if an x-ray contains a tumor. Data labeling is required for a variety of use cases including computer vision, natural language processing, and speech recognition.
How does data labeling work?
Today, most practical machine learning models utilize supervised learning, which applies an algorithm to map one input to one output. For supervised learning to work, you need a labeled set of data that the model can learn from to make correct decisions. Data labeling typically starts by asking humans to make judgments about a given piece of unlabeled data. For example, labelers may be asked to tag all the images in a dataset where “does the photo contain a bird” is true. The tagging can be as rough as a simple yes/no or as granular as identifying the specific pixels in the image associated with the bird. The machine learning model uses human-provided labels to learn the underlying patterns in a process called "model training." The result is a trained model that can be used to make predictions on new data.
In machine learning, a properly labeled dataset that you use as the objective standard to train and assess a given model is often called “ground truth.” The accuracy of your trained model will depend on the accuracy of your ground truth, so spending the time and resources to ensure highly accurate data labeling is essential.
What are some common types of data labeling?
Computer Vision
When building a computer vision system, you first need to label images, pixels, or key points, or create a border that fully encloses a digital image, known as a bounding box, to generate your training dataset. For example, you can classify images by quality type (like product vs. lifestyle images) or content (what’s actually in the image itself), or you can segment an image at the pixel level. You can then use this training data to build a computer vision model that can be used to automatically categorize images, detect the location of objects, identify key points in an image, or segment an image.
Natural Language Processing
Natural language processing requires you to first manually identify important sections of text or tag the text with specific labels to generate your training dataset. For example, you may want to identify the sentiment or intent of a text blurb, identify parts of speech, classify proper nouns like places and people, and identify text in images, PDFs, or other files. To do this, you can draw bounding boxes around text and then manually transcribe the text in your training dataset. Natural language processing models are used for sentiment analysis, entity name recognition, and optical character recognition.
Audio Processing
Audio processing converts all kinds of sounds such as speech, wildlife noises (barks, whistles, or chirps), and building sounds (breaking glass, scans, or alarms) into a structured format so it can be used in machine learning. Audio processing often requires you to first manually transcribe it into written text. From there, you can uncover deeper information about the audio by adding tags and categorizing the audio. This categorized audio becomes your training dataset.
What are some best practices for data labeling?
There are many techniques to improve the efficiency and accuracy of data labeling. Some of these techniques include:
- Intuitive and streamlined task interfaces to help minimize cognitive load and context switching for human labelers.
- Labeler consensus to help counteract the error/bias of individual annotators. Labeler consensus involves sending each dataset object to multiple annotators and then consolidating their responses (called “annotations”) into a single label.
- Label auditing to verify the accuracy of labels and update them as necessary.
- Active learning to make data labeling more efficient by using machine learning to identify the most useful data to be labeled by humans.
How can data labeling be done efficiently?
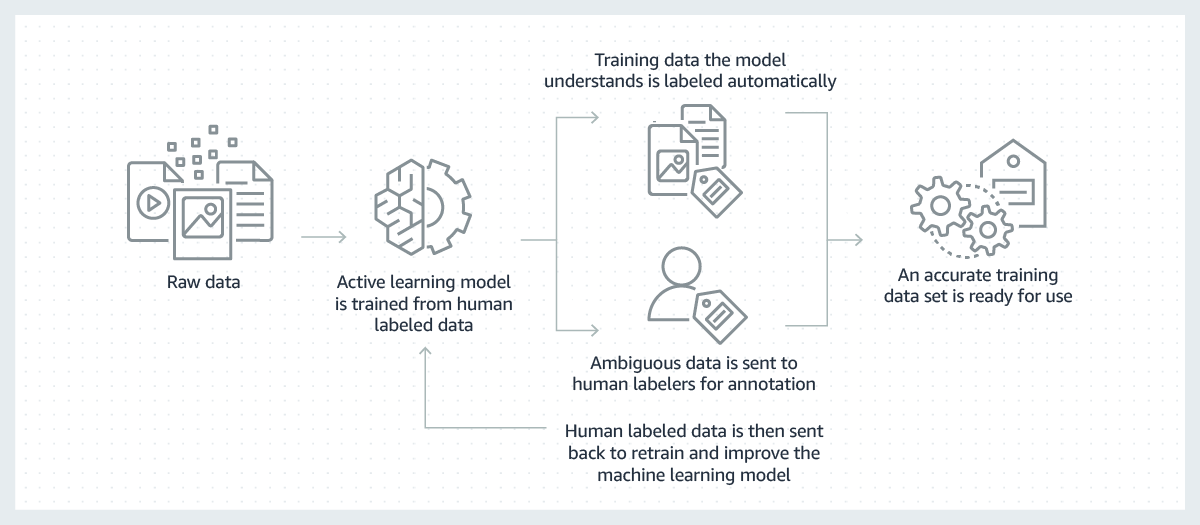
Successful machine learning models are built on the shoulders of large volumes of high-quality training data. But, the process to create the training data necessary to build these models is often expensive, complicated, and time-consuming. The majority of models created today require a human to manually label data in a way that allows the model to learn how to make correct decisions. To overcome this challenge, labeling can be made more efficient by using a machine learning model to label data automatically.
In this process, a machine learning model for labeling data is first trained on a subset of your raw data that has been labeled by humans. Where the labeling model has high confidence in its results based on what it has learned so far, it will automatically apply labels to the raw data. Where the labeling model has lower confidence in its results, it will pass the data to humans to do the labeling. The human-generated labels are then provided back to the labeling model for it to learn from and improve its ability to automatically label the next set of raw data. Over time, the model can label more and more data automatically and substantially speed up the creation of training datasets.
How can AWS support your data labeling requirements?
Amazon SageMaker Ground Truth significantly reduces the time and effort required to create datasets for training. SageMaker Ground Truth offers access to public and private human labelers and provides them with built-in workflows and interfaces for common labeling tasks. It's easy to get started with SageMaker Ground Truth. The Getting Started tutorial can be used to create your first labeling job in minutes.
Get started with Data Labeling on AWS by creating an account today.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages