Artificial Intelligence
Category: Compute
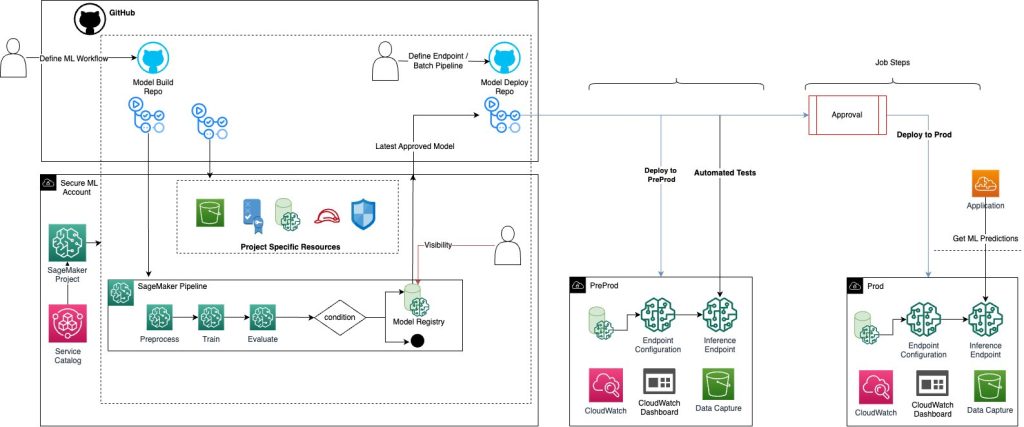
Implement a secure MLOps platform based on Terraform and GitHub
Machine learning operations (MLOps) is the combination of people, processes, and technology to productionize ML use cases efficiently. To achieve this, enterprise customers must develop MLOps platforms to support reproducibility, robustness, and end-to-end observability of the ML use case’s lifecycle. Those platforms are based on a multi-account setup by adopting strict security constraints, development best […]

Implement automated monitoring for Amazon Bedrock batch inference
In this post, we demonstrated how a financial services company can use an FM to process large volumes of customer records and get specific data-driven product recommendations. We also showed how to implement an automated monitoring solution for Amazon Bedrock batch inference jobs. By using EventBridge, Lambda, and DynamoDB, you can gain real-time visibility into batch processing operations, so you can efficiently generate personalized product recommendations based on customer credit data.
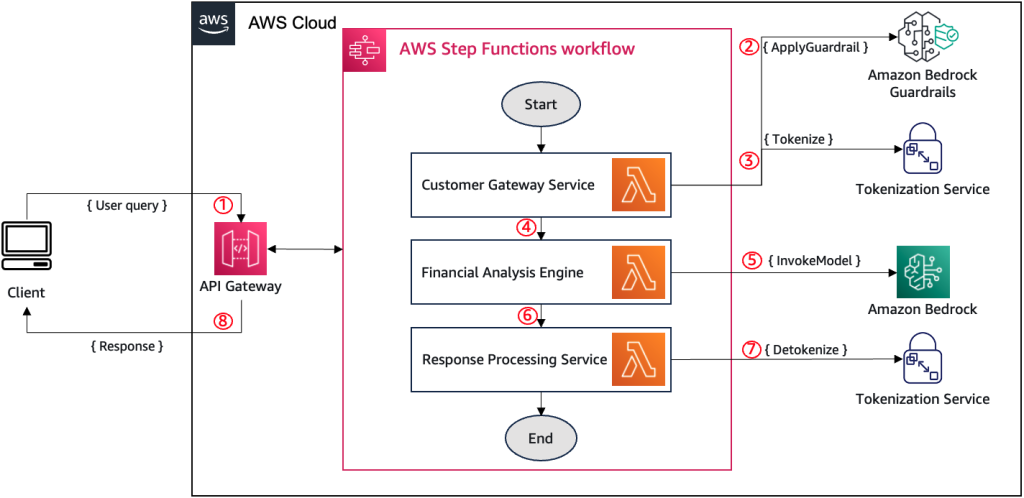
Integrate tokenization with Amazon Bedrock Guardrails for secure data handling
In this post, we show you how to integrate Amazon Bedrock Guardrails with third-party tokenization services to protect sensitive data while maintaining data reversibility. By combining these technologies, organizations can implement stronger privacy controls while preserving the functionality of their generative AI applications and related systems.
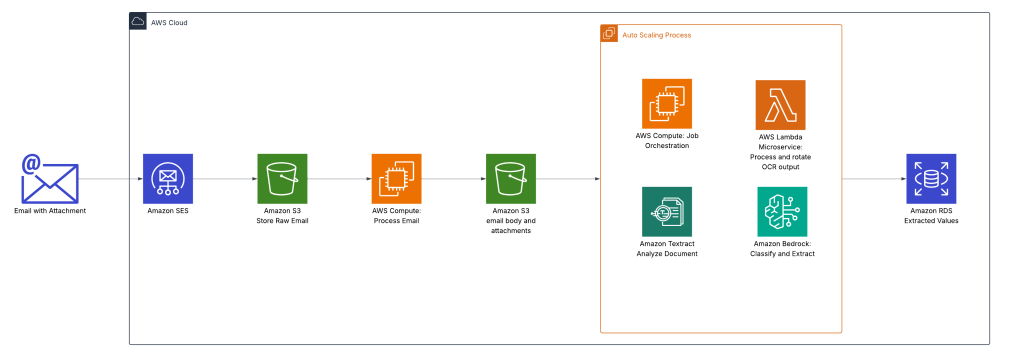
Oldcastle accelerates document processing with Amazon Bedrock
This post explores how Oldcastle partnered with AWS to transform their document processing workflow using Amazon Bedrock with Amazon Textract. We discuss how Oldcastle overcame the limitations of their previous OCR solution to automate the processing of hundreds of thousands of POD documents each month, dramatically improving accuracy while reducing manual effort.
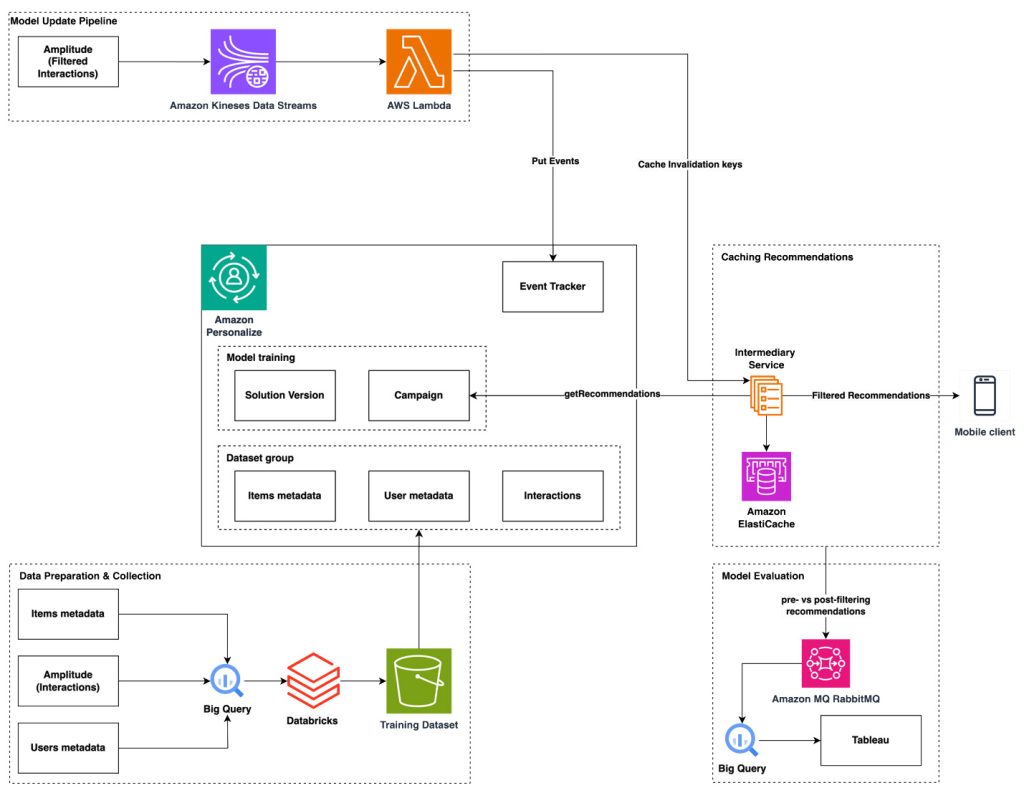
The power of AI in driving personalized product discovery at Snoonu
In this post, we share how Snoonu, a leading ecommerce platform in the Middle East, transformed their product discovery experience using AI-powered personalization. In this post, we share how Snoonu, a leading ecommerce platform in the Middle East, transformed their product discovery experience using AI-powered personalization.

Amazon SageMaker HyperPod enhances ML infrastructure with scalability and customizability
In this post, we introduced three features in SageMaker HyperPod that enhance scalability and customizability for ML infrastructure. Continuous provisioning offers flexible resource provisioning to help you start training and deploying your models faster and manage your cluster more efficiently. With custom AMIs, you can align your ML environments with organizational security standards and software requirements.

Build a scalable containerized web application on AWS using the MERN stack with Amazon Q Developer – Part 1
In a traditional SDLC, a lot of time is spent in the different phases researching approaches that can deliver on requirements: iterating over design changes, writing, testing and reviewing code, and configuring infrastructure. In this post, you learned about the experience and saw productivity gains you can realize by using Amazon Q Developer as a coding assistant to build a scalable MERN stack web application on AWS.
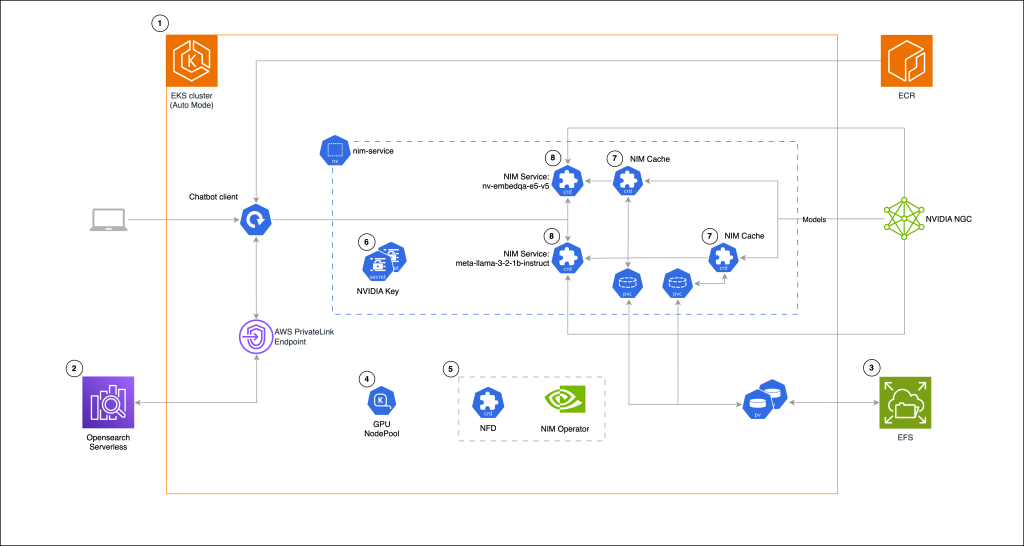
Building a RAG chat-based assistant on Amazon EKS Auto Mode and NVIDIA NIMs
In this post, we demonstrate the implementation of a practical RAG chat-based assistant using a comprehensive stack of modern technologies. The solution uses NVIDIA NIMs for both LLM inference and text embedding services, with the NIM Operator handling their deployment and management. The architecture incorporates Amazon OpenSearch Serverless to store and query high-dimensional vector embeddings for similarity search.

How Amazon scaled Rufus by building multi-node inference using AWS Trainium chips and vLLM
In this post, Amazon shares how they developed a multi-node inference solution for Rufus, their generative AI shopping assistant, using Amazon Trainium chips and vLLM to serve large language models at scale. The solution combines a leader/follower orchestration model, hybrid parallelism strategies, and a multi-node inference unit abstraction layer built on Amazon ECS to deploy models across multiple nodes while maintaining high performance and reliability.

Containerize legacy Spring Boot application using Amazon Q Developer CLI and MCP server
In this post, you’ll learn how you can use Amazon Q Developer command line interface (CLI) with Model Context Protocol (MCP) servers integration to modernize a legacy Java Spring Boot application running on premises and then migrate it to Amazon Web Services (AWS) by deploying it on Amazon Elastic Kubernetes Service (Amazon EKS).