亚马逊AWS官方博客
智能安防监控视频中的AI技术集成
摘要
智能IP监控的使用场景十分广泛,也衍生出众多的需求,如云存需求,回放需求,AI图像视频理解层面的需求等等。落地的场景有智慧楼宇,公共场所安防监控,居家室内外监控,智慧门铃,大型活动策划方,面部身份鉴定等等。立足于这些客户场景,本文主要介绍智能IP监控相机中的AI技术集成,在IP监控相机的数据上云之后,可以与众多计算机视觉算法相结合,如人脸检测,人脸检索,人形检测,或其他目标检测,行为分析等。文中阐述三种AI算法集成架构,并阐述各自适用的不同场景。
相关链接
- 智能安防监控视频云存部分博客请参考:利用云上托管服务和AI构建安防视频云存
- 智能安防监控视频中AI算法服务解决方案:智能IP摄像头AI SaaS解决方案 (源代码: https://github.com/aws-samples/amazon-ipc-ai-saas)
三种解决方案架构
在监控图像视频领域可以集成AI算法的方式有很多种,最典型的有两种方式:其一是对视频流就行拆帧调用AI算法来获取图像帧中的一些抽象信息,如图像分类,目标检测,图像分割等等;其二是直接将某一段视频流片段输入给特定的行为识别算法进行推理,如动作分类(action classification)等。不同的算法需求对应的最优实践架构各不相同,下面介绍三种典型的AI推理方案架构:基于亚马逊云科技SageMaker Endpoint的推理架构,基于亚马逊云科技Lambda无服务器的推理架构和基于任务队列的推理架构。
-
- 基于Amazon SageMaker Endpoint的解决方案架构

基于Amazon SageMaker Endpoint的架构适用于高并发大使用量的场景,用户可以将图像数据进行base64编码,并基于HTTP POST请求发送给Amazon SageMaker Endpoint(推理节点),Amazon SageMaker Endpoint将推理结果以JSON形式返回给用户端。在这种架构中,部署机型可根据实际情况选择,并可以自动扩展帮助用户处理高并发量的请求,以ml.g4dn.xlarge机型为例,假设用户处理的算法逻辑为yolo3_darketnet53目标检测,单台设备每秒可以处理20~50个请求(输入图像尺度不同,速度不同,借助于Amazon SageMaker Neo可以进一步优化模型,显著提升推理速度),每台设备每天可以处理170万~430万个请求,费用仅为115元左右(以us-east-1区域为例)。
- 基于AWS Lambda无服务器的解决方案架构

基于AWS Lambda的无服务器架构同样是HTTP POST请求携带图像base64编码数据进行调用,该架构中的Lambda函数一般依赖多种第三方软件包,如gluoncv, opencv, mxnet等,推荐基于ECR 镜像的方式进行加载。该方案具有按量付费,部署简单快捷,轻量级的优点。它适用于访问量比较小的场景,按照AWS Lambda函数4096MB内存计算,假设单次调用耗时1000 毫秒,以北京,宁夏区域为例,每1000次调用费用仅为约0.454元(每1毫秒价格为0.0000004539元)。
-
- 基于任务队列的解决方案架构
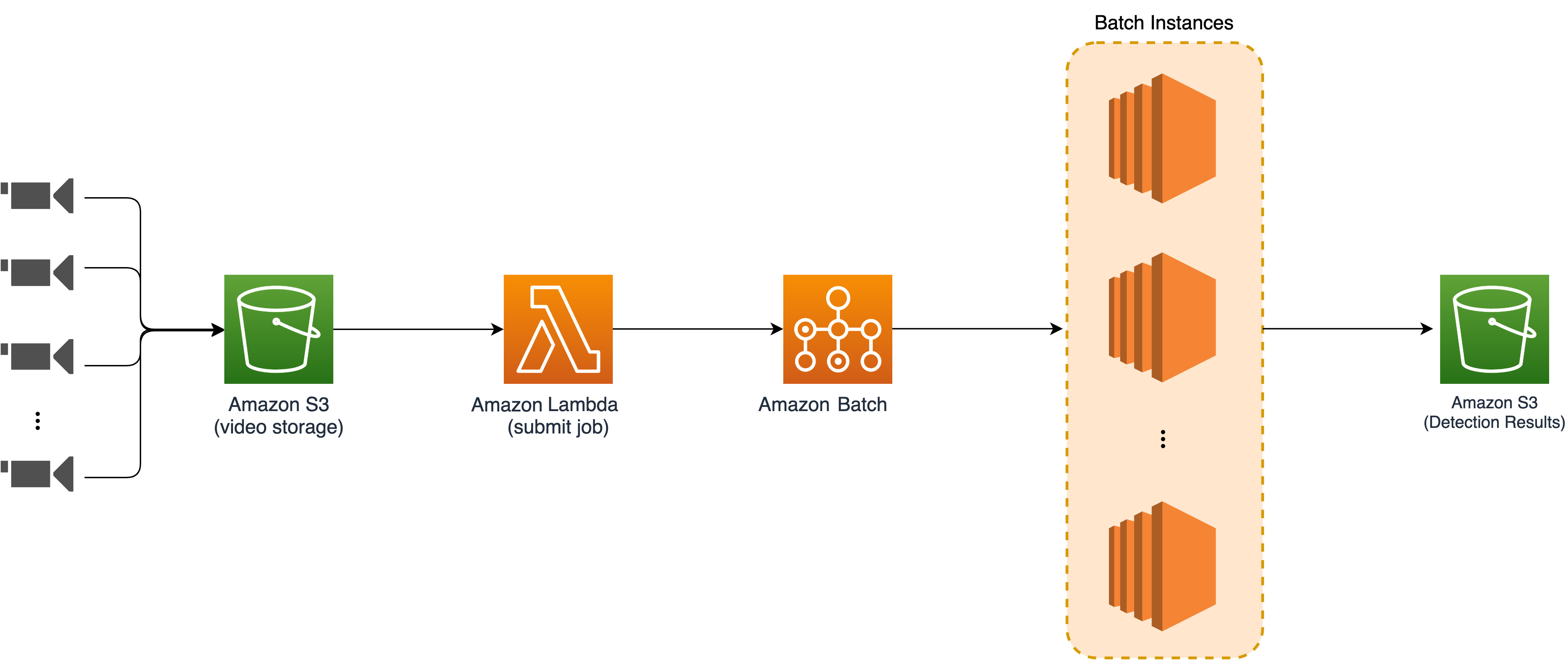
基于任务队列的架构适用于对处理实时性不高的批量处理任务。如定时触发对S3桶中的所有视频片段进行AI识别处理,并将结果进行存储。该架构中所有的监控视频片段在客户端进行切片并上传到云端进行存储,视频片段上传事件会触发AI推理任务,批处理的实例数量可以根据任务的数量进行自动扩展,同时该种架构可结合竞价(Spot)实例进行使用,进一步降低成本。
解决方案快速部署
以第一种解决方案架构(Amazon SageMaker Endpoint)为例,亚马逊云科技大中华区解决方案团队发布了一键部署的CloudFormation模板,第二种和第三种架构可以根据用户的需求进行调整适配。您可以直接基于该模板来进行快速部署和管理。打开亚马逊云科技管理控制台(如果还没登录会先跳转到登录页面,登录后进入模板启动页面)。默认情况下,中国区此模板在北京区域启动,海外区会在us-east-1区域启动。您同时可以使用控制台右上方的区域选择链接,以在其他区域部署该方案。然后单击下面的按钮以启动亚马逊云科技CloudFormation 模板。
中国区部署链接:
海外区部署链接:
部署的时候选择服务类型,包括人脸检测,人形检测和人脸服务。开始部署后等待10-15分钟可以部署完成。
终端用户调用API接口
在解决方案部署完成后,可以基于API Gateway暴露出来的接口URL(国内部署需要进行域名ICP备案和自定义域名,请参考 自定义API Gateway域名)进行请求测试。测试基于Python接口实现,注意该解决方案后推理的URL需要加上inference字段。
人脸检测,人形检测的HTTP POST请求数据字段定义为:
| 字段名称 | 字段数据类型 |
| timestamp | string |
| request_id | int |
| image_base64_enc | string |
人脸比较的HTTP POST请求字段定义为:
| 字段名称 | 字段数据类型 |
| timestamp | string |
| request_id | int |
| source_image | string |
| target_image | string |
人脸检测,人形检测以及人脸比较调用时需要配置部署好的HTTPS调用地址,以及测试图片的本地路径。以人脸比较为例,用户需要配置invoke_url, test_source_image_full_path和test_target_image_full_path三个参数,调用示例代码如下所示(更为详细的部署指南请参考 智能IP摄像头AI SaaS解决方案部署指南):
import base64
import time
import json
import requests
def get_base64_encoding(full_path):
with open(full_path, "rb") as f:
data = f.read()
image_base64_enc = base64.b64encode(data)
image_base64_enc = str(image_base64_enc, 'utf-8')
return image_base64_enc
invoke_url = 'https://example.com/inference'
test_source_image_full_path = 'your_test_1_source.jpg'
test_target_image_full_path = 'your_test_1_target.jpg'
# Step 1: read image and execute base64 encoding
source_image_base64_enc = get_base64_encoding(test_source_image_full_path)
target_image_base64_enc = get_base64_encoding(test_target_image_full_path)
# Step 2: send request to backend
request_body = {
"timestamp": str(time.time()),
"request_id": 123456789,
"source_image": source_image_base64_enc,
"target_image": target_image_base64_enc
}
response = requests.post(invoke_url, data=json.dumps(request_body))
注意人脸比较的输入涉及到两张图片,即源图片(source image)和目标图片(target image),人脸比较首先会检测源图片和目标图片中的所有人脸,然后将源图片中的最大人脸和目标图片中的所有人脸进行逐一比较。人脸比较的输出JSON格式示例如下所示:
{
"SourceImageFace": {
"BoundingBox": [
644.277099609375,
90.42400360107422,
1045.201171875,
629.7315673828125
],
"Confidence": 0.9995160102844238,
"KeyPoints": {
"eyeLeft": [
822.739501953125,
310.3930969238281
],
"eyeRight": [
989.8619995117188,
310.2413330078125
],
"nose": [
943.7721557617188,
422.5981750488281
],
"mouthLeft": [
804.6290893554688,
482.67498779296875
],
"mouthRight": [
964.2872924804688,
482.8955383300781
]
}
},
"FaceMatches": [
{
"Similarity": 0.799949049949646,
"Face": {
"BoundingBox": [
480.2578125,
264.4273986816406,
556.0911865234375,
365.416259765625
],
"Confidence": 0.9978690147399902,
"KeyPoints": {
"eyeLeft": [
496.1192626953125,
304.3525695800781
],
"eyeRight": [
530.375244140625,
305.2247619628906
],
"nose": [
509.9425964355469,
326.3017272949219
],
"mouthLeft": [
497.8830871582031,
339.443115234375
],
"mouthRight": [
527.404541015625,
340.0354919433594
]
}
}
},
{
"Similarity": 0.048441335558891296,
"Face": {
"BoundingBox": [
383.55804443359375,
187.462158203125,
457.1243591308594,
281.0417785644531
],
"Confidence": 0.984475314617157,
"KeyPoints": {
"eyeLeft": [
401.30572509765625,
227.2242431640625
],
"eyeRight": [
433.8825378417969,
220.3402862548828
],
"nose": [
421.2277526855469,
238.453125
],
"mouthLeft": [
409.9819030761719,
256.7333679199219
],
"mouthRight": [
439.6954650878906,
251.2649688720703
]
}
}
}
]
}