亚马逊AWS官方博客
在Amazon Athena 上使用 Partition Projection 与 Glue Partition Indexes 效能比较
背景
在日常的维运工作当中,如何以低成本的方式储存且分析日志,是我们常见的需求。为了满足这样的需求,我们可以将日志储存在S3上,并使用 Amazon Athena 查询常见的日志,例如 Amazon CloudTrail 日志、Amazon CloudFront 日志、Classic Load Balancer 日志、Application Load Balancer 日志、Amazon VPC 流日志和网络负载均衡器日志。但是随着时间的推移,数十万个分区被添加到一个表中,查询操作开始变得缓慢。这是因为Athena 透过 Glue GetPartitions API 用于获取表中的分区,如果表中没有分区索引,则 Glue 加载表的所有分区,需要更多的时间来运行,也造成了Athena 查询资料时间的增加。 Amazon Athena 分区投影相关的功能,透过分区投影中的值做匹配计算,得出位置,减少分区元数据检索方面受到限制的查询的运行时间。随着时间的推移,Glue 也推出了分区索引相关的功能,可以方便客户与其他服务,如EMR、Glue ETL、Redshift Specturm… 等等,做元数据的储存与查询。许多人会有一个疑问是,Athena分区投影 与 Glue分区索引效能再一定的分区数量时的比较,也是这篇部落格会探讨的议题。
Amazon Athena 分区投影
可以在 Athena 中使用分区投影来加快对高度分区表的查询处理,并自动执行分区管理。在分区投影中,分区值和位置是根据配置计算得出的,而不是从存储库(例如 Amazon Glue Data Catalog)中读取出的。由于内存中的操作通常快于远程操作,因此,分区投影可以减少针对高度分区表的查询的运行时间。根据查询和基础数据的具体特征,分区投影可以显着减少在分区元数据检索方面受到限制的查询的运行时间。
Amazon Glue 分区索引
随着时间的推移,数十万个分区被添加到一个表中。GetPartitions API 用于获取表中的分区。API 返回与请求中提供的表达式匹配的分区。如果表中没有分区索引,则 Amazon Glue 加载表的所有分区,然后使用用户在 GetPartitions 请求中提供的查询表达式筛选加载的分区。随着没有索引的表上的分区数量的增加,查询需要更多的时间来运行。借助索引,GetPartitions 查询将尝试获取分区的子集,而不是加载表中的所有分区。
性能比较
测试资料集
为了要验证 Amazon Athena Partition Projection 与 Glue Partition Indexes 效能的比较,我们需要有一个高度分区数量的资料集,在本篇部落格中以 awsglue-datasets 中高度分区数的范例资料(s3://awsglue-datasets/examples/highly-partitioned-table/)为例。该资料集使用 year、month、day、hour做分区,涵盖了1980到2021年,总共359,160个分区(41 year (1980-2021) * 365 day * 24 hours = 359,160)。
Glue 未建立分区检索
当我们使用 Glue 爬网程序用表填充 Glue Data Catalog,并从 Athena 产生该表单的 DDL,我们可以观察到该表单已经定义包含year, month, day, hour 的 PARTITION 资料。
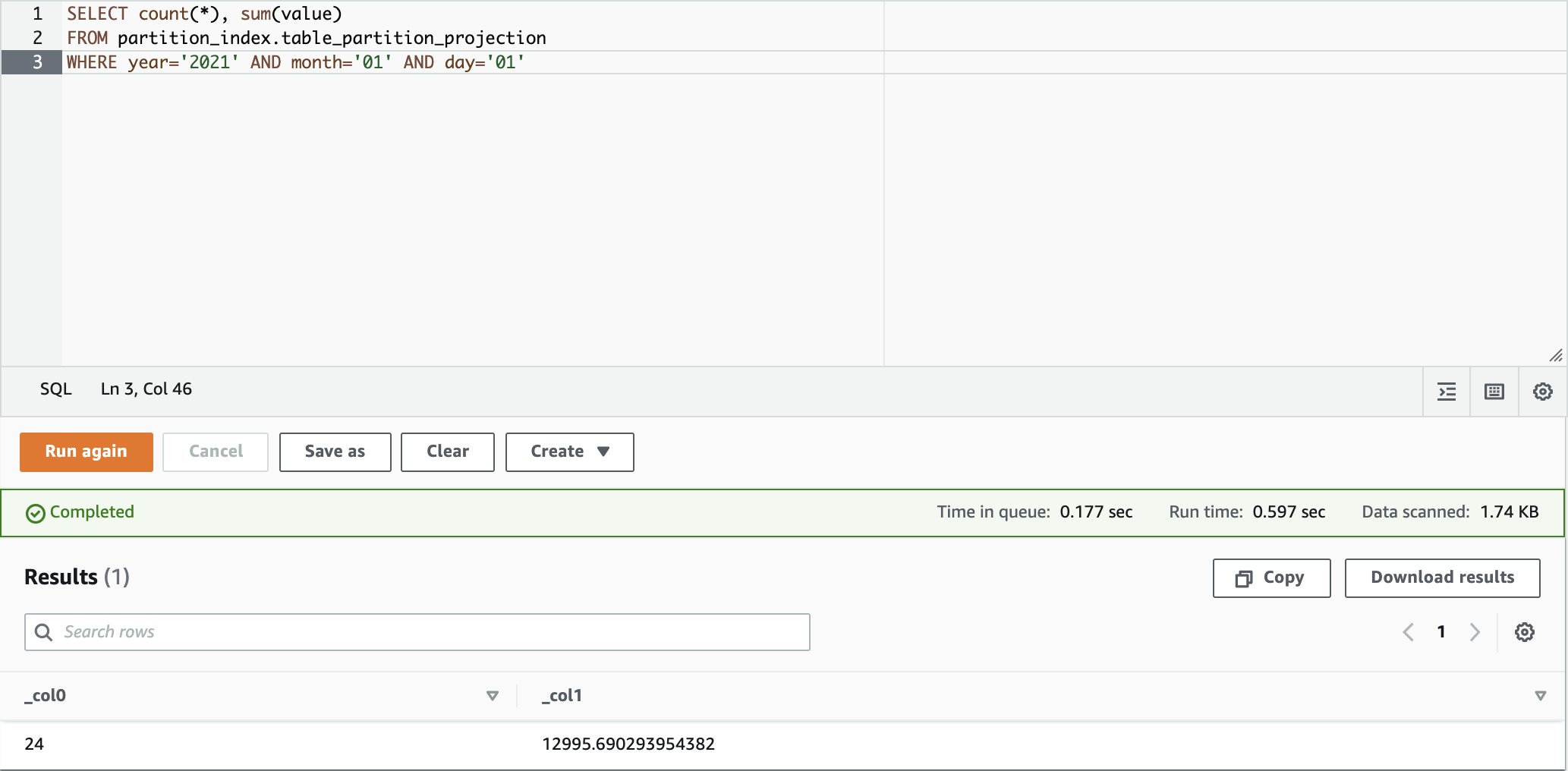
在Athena Console 执行以下SQL语法,我们可以观察到Athena 根据 Partition 资料与分区修剪的机制,只有扫描对应分区的路径下的资料,所以 Data Scanned 为 1.74 KB。但因为 Glue 加载表的所有分区,需要更多的时间来运行,也造成了Athena 查询资料时间的增加,所以总共花了 50 秒来查询资料。

Athena 分区投影
为了要改善 Glue 加载表的所有分区,需要更多的时间来运行的状况,我们可以使用 Athena 分区修剪。在Athena Console 输入下面的 SQL 语法创建表单,并在TBLPROPERTIES 处定义 year, month, day, hour 等我们作为分区栏位的资料型别、范围与长度,让Athena 分区投影利用这些资讯做匹配计算,得出位置。避免因为 Glue 加载表的所有分区,需要更多的时间来运行,所造成的Athena 查询资料时间的增加。
在Athena Console 执行以下SQL语法,我们可以观察到Athena 只有搜寻对应分区的路径下的资料,所以 Data Scanned 同样为 1.74 KB。但因为透过 Athena 分区投影中的值做匹配计算,得出位置,减少分区元数据检索方面受到限制的查询的运行时间为 0.59 秒。
Amazon Glue 分区索引
当我们在Athena 以外的场景如EMR、Glue ETL、Redshift Specturm… 等等,无法使用 Athena 分区检索来优化,Glue 加载表的所有分区,需要更多的时间来运行的问题,在这种情况下我们可以使用 Glue 分区索引来优化。借助索引,GetPartitions 查询将尝试获取分区的子集,而不是加载表中的所有分区。
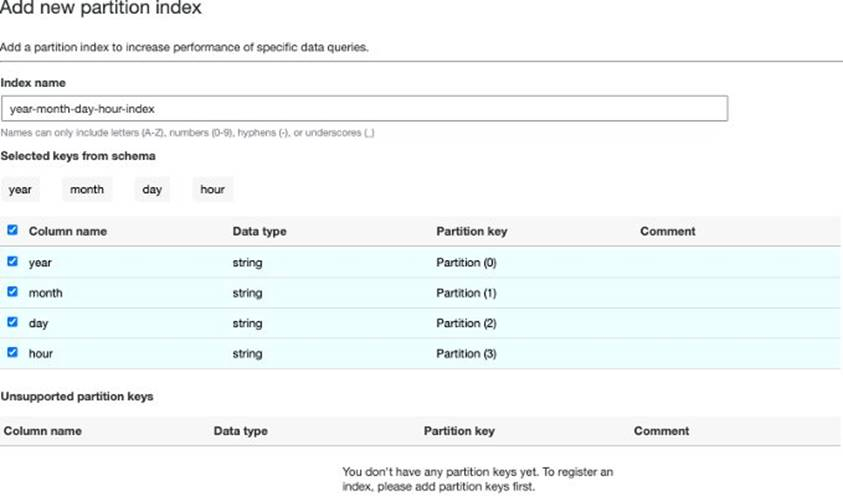
我们可以使用 Glue 爬网程序产生出 table_with_index 表单与分区资料,并储存于 Glue Data Catalog 中,然后在Tables 点选产生出来的表单,点选右上角的 Partitions and indices,然后点选 Add new index 创建分区索引。命名索引名称与勾选 keys ,并完成分区索引创建。

为了要进一步在该表单上启用分区过滤功能,我们会编辑表单的 TBLPROPERTIES 加入 partition_filtering.enabled = true 的设置。

为了进一步启用分区过滤功能,我们会编辑表单的 TBLPROPERTIES 加入 partition_filtering.enabled = true 的设置
Athena 产生该表单的 DDL,我们可以观察到该表单已经定义包含year, month, day, hour 的 PARTITION 资料与TBLPROPERTIES 启用分区过滤功能。
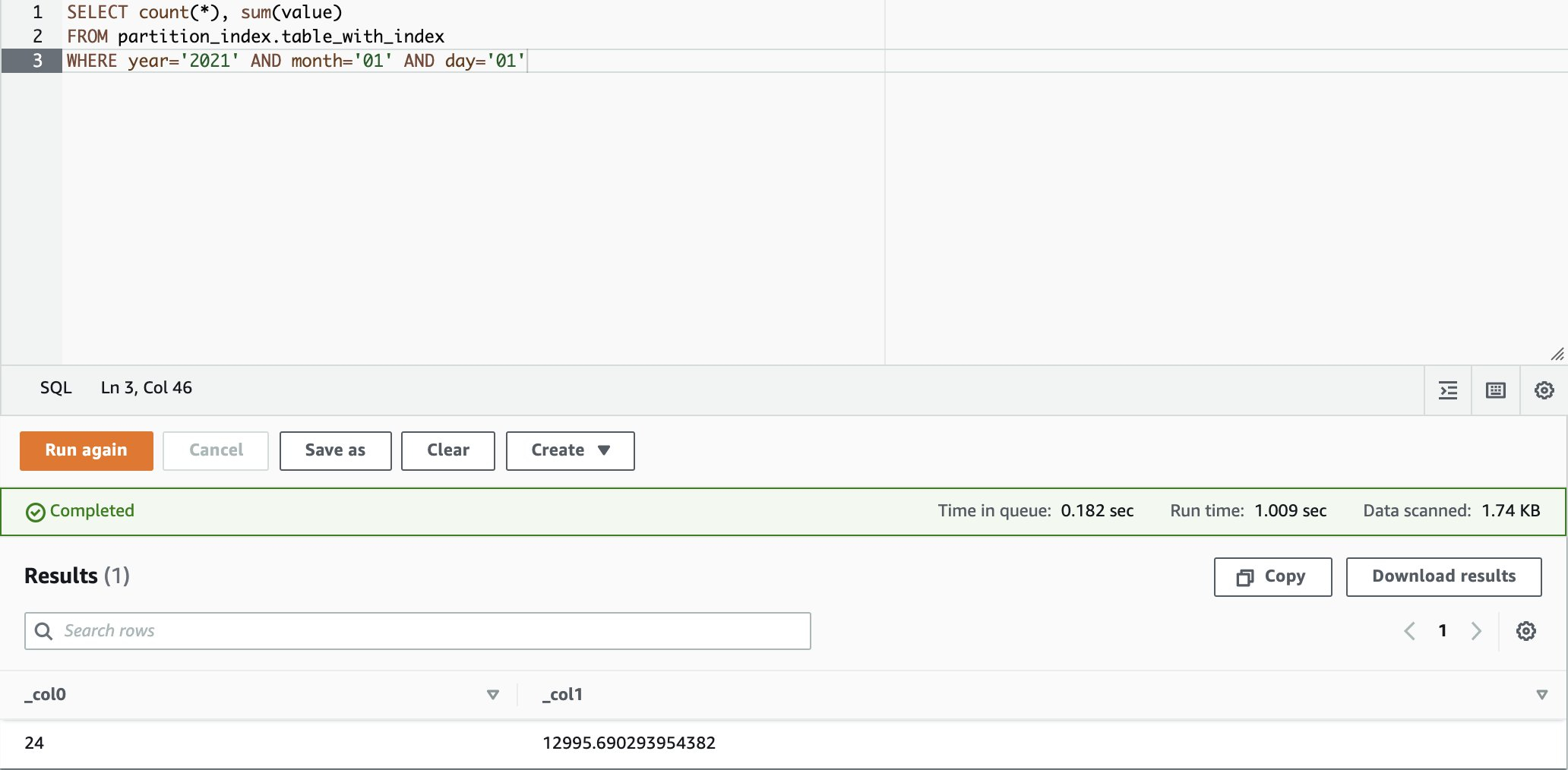
在Athena Console 执行以下SQL语法,我们可以观察到Athena 只有搜寻对应分区的路径下的资料,所以 Data Scanned 同样为 1.74 KB。透过 Glue 分区检索,GetPartitions 查询将尝试获取分区的子集,而不是加载表中的所有分区,查询时间为 1.009 秒。
运行多次平均
总结
未建立分区索引的表的Query速度明显的比 Athena 分区投影 以及 Amazon Glue 分区索引来的更花时间。Athena 分区投影则比 Amazon Glue 分区索引更快一点。分区投影直接计算出分区信息,来跳过Glue Data Catalog,可以比使用Glue 分区索引更快。如果使用的场景在Athena上较多,可以使用Athena 分区投影。Glue的分区索引则是适用其他场景,例如EMR使用Glue Catalog,Glue ETL使用 Glue Pushdown Predicate。