亚马逊AWS官方博客
Amazon Redshift 继续保持在性价比方面的领先地位
数据是一种战略资产。要想从数据中及时获取价值,能够在大规模下保持较低成本的同时确保高性能的系统必不可少。Amazon Redshift 是最流行的云数据仓库,每天有成千上万的客户使用它来分析 EB 级数据。我们不断增加新的功能,以便在客户将更多数据带入 Amazon Redshift 环境时,不断为客户提升性价比。
这篇文章详细介绍了我们通过 Amazon Redshift 机群的遥测数据发现的分析工作负载趋势,我们为提高 Amazon Redshift 性价比而推出的新功能,以及通过源自 TPC-DS 和 TPC-H 的最新基准测试获得的结果,这些结果有力地支持了我们的领先地位。
数据驱动型性能优化
我们坚持不懈地致力于提高 Amazon Redshift 的性价比,这样您便可以持续感受到实际工作负载的改进。为此,Amazon Redshift 团队采用数据驱动型方法实现性能优化。Werner Vogels 介绍了我们在 Amazon Redshift 中采用的方法以及在云端优化性能的技巧,我们坚持不懈地将专注于利用来自庞大客户群的性能遥测数据,推动我们客户最为重视的 Amazon Redshift 性能改进。
此时,您可能会问,为什么性价比很重要? 数据仓库的一个关键层面在于它如何随着数据的增长扩展。您是在增加了更多数据时为每 TB 支付更多费用,还是保持稳定且可预测的成本? 我们努力确保 Amazon Redshift 不仅能在数据增长时提供强劲的性能,而且还能提供稳定的性价比。
优化高并发、低延迟的工作负载
我们观察到的趋势之一是,客户越来越多地构建需要高并发度、低延迟查询的分析应用程序。在数据仓库环境中,这意味着会有数百甚至数千名用户运行查询,且响应时间 SLA 低于 5 秒。
一种常见场景是由 Amazon Redshift 提供支持的商业智能控制面板,用来为非常大量的分析师提供分析功能。例如,我们的一位客户处理外汇汇率,并使用 Amazon Redshift 支持的控制面板基于这些数据向其用户提供洞察。平均而言,这些用户会对 Amazon Redshift 生成 200 个并发查询,在市场开盘和收盘时会激增至 1200 个并发查询,并且 P90 查询 SLA 为 1.5 秒。Amazon Redshift 能够满足这一要求,使得客户可以满足业务 SLA,并为其用户提供尽可能最好的服务。
我们跟踪的一个具体指标是,所有集群中短运行时间查询(运行时间少于 1 秒的查询)所占的运行时间百分比。在过去的一年中,我们看到 Amazon Redshift 机群中的短查询工作负载显著增加,如下图所示。
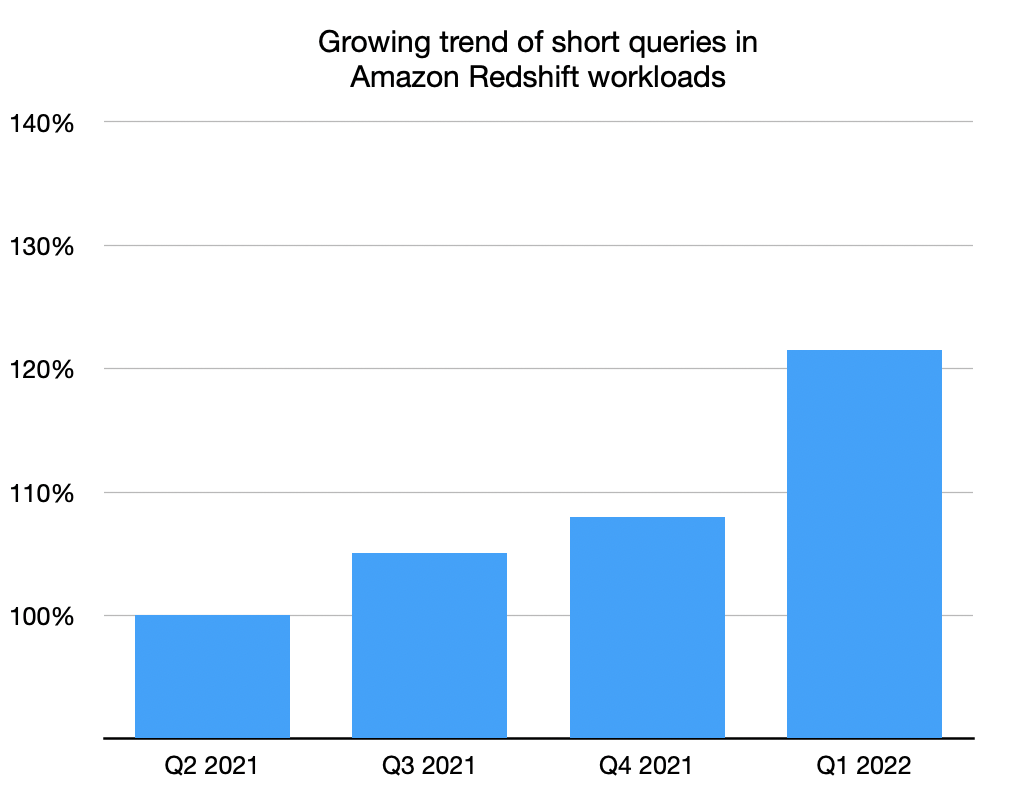 我们开始更深入地研究 Amazon Redshift 如何运行此类工作负载,并从中发现了几个优化性能的机会,以便为您提供更好的短查询吞吐量:
我们开始更深入地研究 Amazon Redshift 如何运行此类工作负载,并从中发现了几个优化性能的机会,以便为您提供更好的短查询吞吐量:
- 我们显著减少了 Amazon Redshift 的查询规划开销。尽管这种开销并不是很大,但它会是短查询运行时间的重要部分。
- 对于多个并发进程争用相同资源的情况,我们改进了几个核心组件的性能。这进一步减少了查询开销。
- 我们进行了改进,使得 Amazon Redshift 能够更高效地将突增的这些短查询转到并发扩展集群中,从而改善并行查询能力。
为了探明 Amazon Redshift 在进行这些工程改进后的情况,我们使用源自 TPC-DS 的云数据仓库基准测试开展了内部测试(有关基准测试的更多详细信息,请参见后文,该基准测试在 GitHub 上提供)。为了模拟高并发度、低延迟的工作负载,我们使用了一个 10 GB 的小型数据集,这样便可以在几秒以内运行所有查询。我们还对其他几个云数据仓库运行了相同的基准测试。对于此测试,我们没有启用弹性伸缩功能,例如 Amazon Redshift 上的并发扩展,因为并非所有数据仓库都支持该功能。我们使用了 ra3.4xlarge Amazon Redshift 集群,并使用按需价格,将所有其他数据仓库的大小调整为最接近的等价配置。基于此配置,我们发现,对于主要需要短查询、低延迟和高并发度的分析应用程序,Amazon Redshift 可提供高达 8 倍的性能,如下图所示。
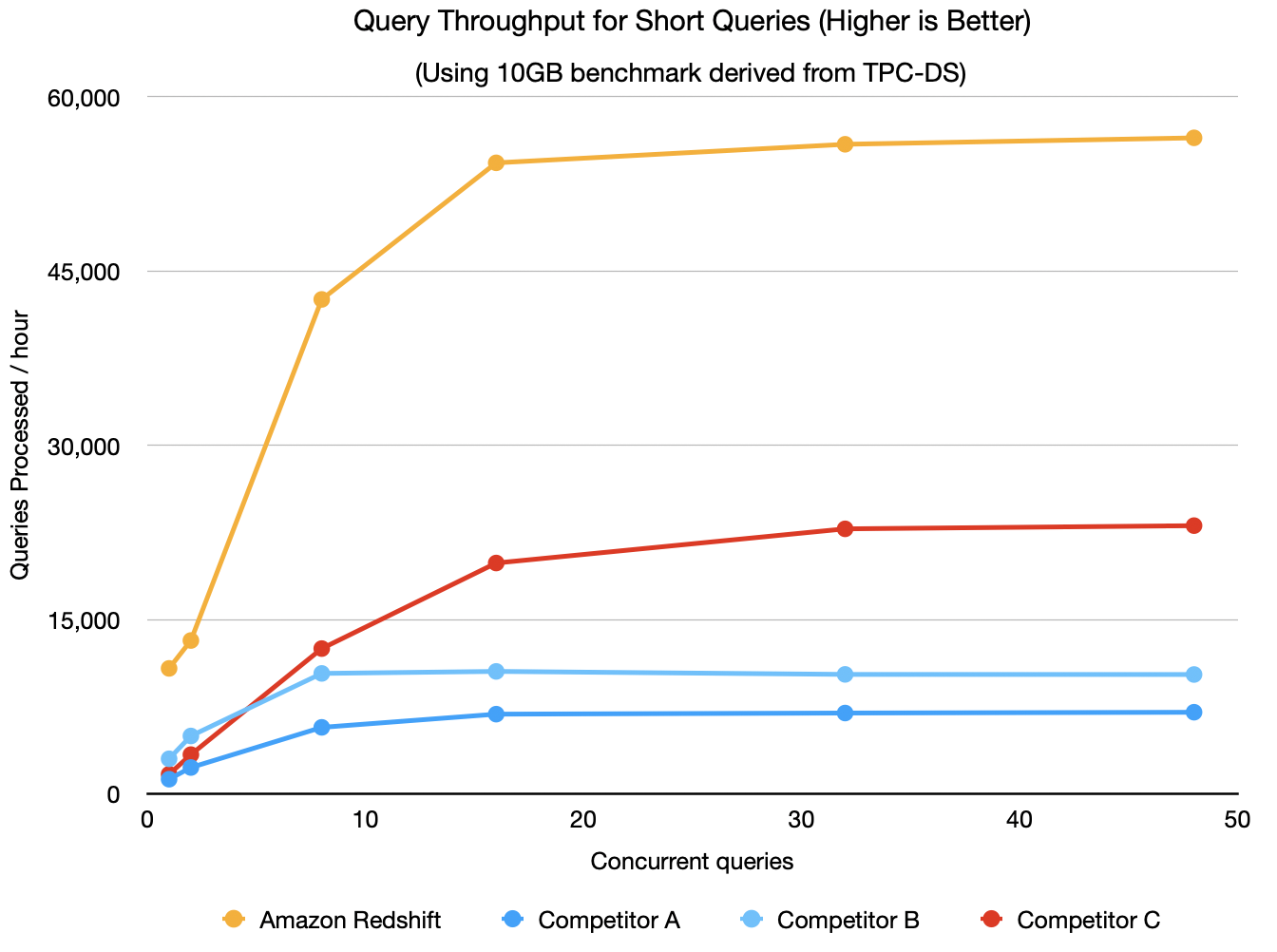
借助 Amazon Redshift 上的并发扩展,随着用户并发度的增长,可以将吞吐量无缝地自动扩展到其他 Amazon Redshift 集群。根据遥测数据,我们可以看到越来越多的客户使用 Amazon Redshift 构建此类分析应用程序。
这只是我们团队持续开展的幕后工程改进的一小部分,这些改进旨在使用数据驱动型方法帮助您提高性能并节省成本。
提高性价比的新功能
随着数据格局的不断演变,客户需要能够持续推出新功能的高性能数据仓库,以实现大规模下的最佳性能,同时为所有工作负载和应用程序保持较低的成本。我们会继续添加功能,这些功能可直接提高 Amazon Redshift 的性价比,而不会给您带来额外成本,让您能够解决任何规模的业务问题。这些功能包括通过 AWS Nitro System 使用业界一流的硬件、使用 AQUA 进行硬件加速、自动重写查询以使用物化视图加快运行速度、面向架构优化的自动表优化(ATO, Automatic Table Optimization)、提供动态并发和优化资源利用率的自动工作负载管理(WLM, Automatic Workload Management)、短查询加速、自动物化视图、矢量化和单指令/多数据(SIMD, Single Instruction/Multiple Data)处理等等。Amazon Redshift 已经发展成为一个自我学习、自我调整的数据仓库,消除了管理性能的工作需求,使您可以专注于构建分析应用程序等高价值活动。
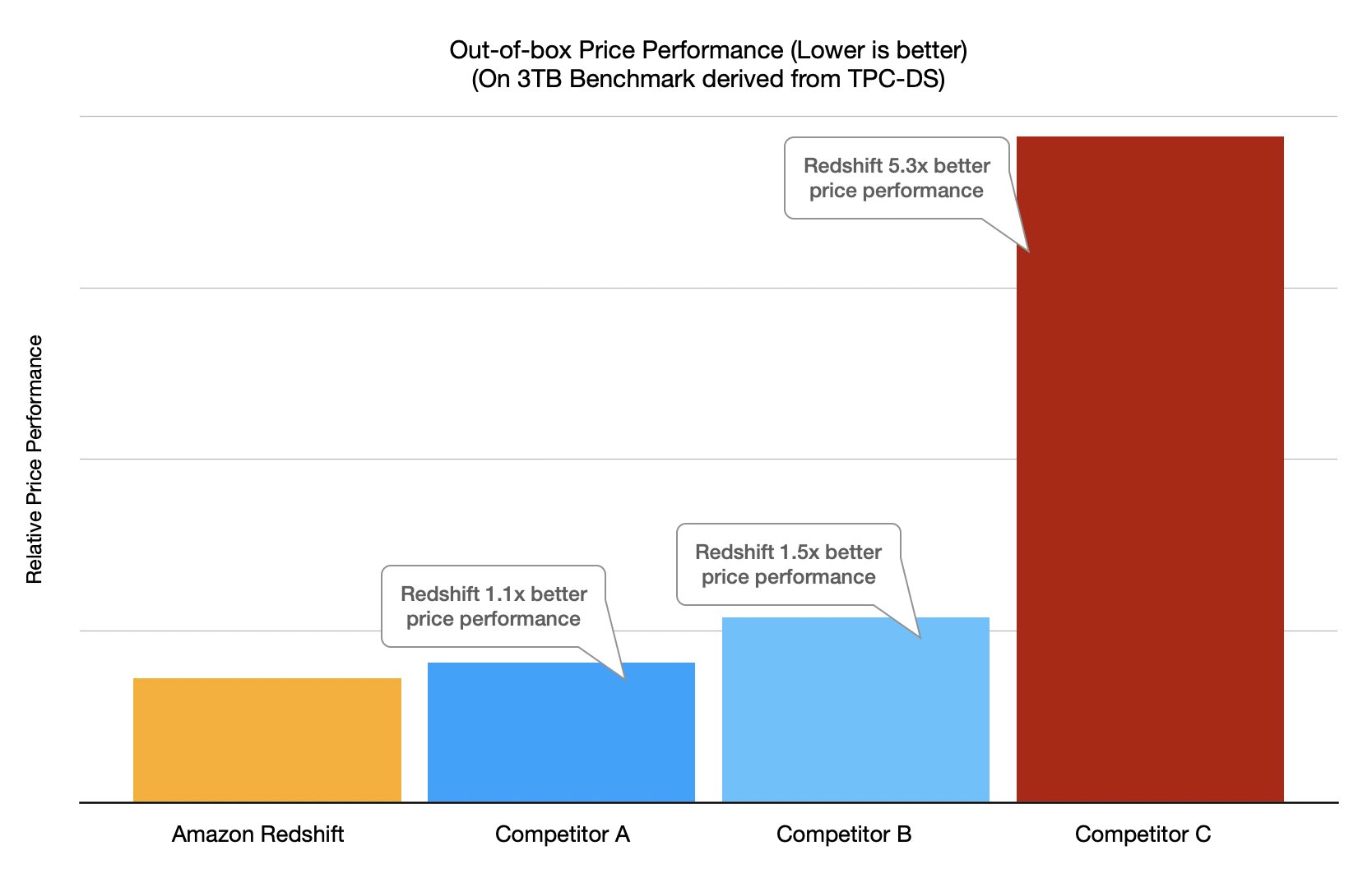
为了验证最新的 Amazon Redshift 性能增强功能的影响,我们运行了性价比基准测试,将 Amazon Redshift 与其他云数据仓库进行了比较。对于这些测试,我们使用 10 节点的 ra3.4xlarge Amazon Redshift 集群,运行了源自 TPC-DS 的基准测试和源自 TPC-H 的基准测试。对于在其他数据仓库上运行测试,我们根据所有数据仓库公开发布的按需定价,选择了价格与 Amazon Redshift 集群最相符的数据仓库规格(每小时 32.60 美元)。由于 Amazon Redshift 是一个自动优化数据仓库,因此所有测试都是“开箱即用”的,这意味着无需应用手动调整或特殊的数据库配置 – 集群启动并运行基准。然后,将每小时成本(USD)乘以基准运行时间(以小时为单位)来计算性价比,这等于运行基准测试的成本。
对于源自 TPC-DS 测试和源自 TPC-H 的测试,我们发现 Amazon Redshift 始终能够提供最佳的性价比。下图显示了源自 TPC-DS 的基准测试的结果。
下图显示了源自 TPC-H 的基准测试的结果。
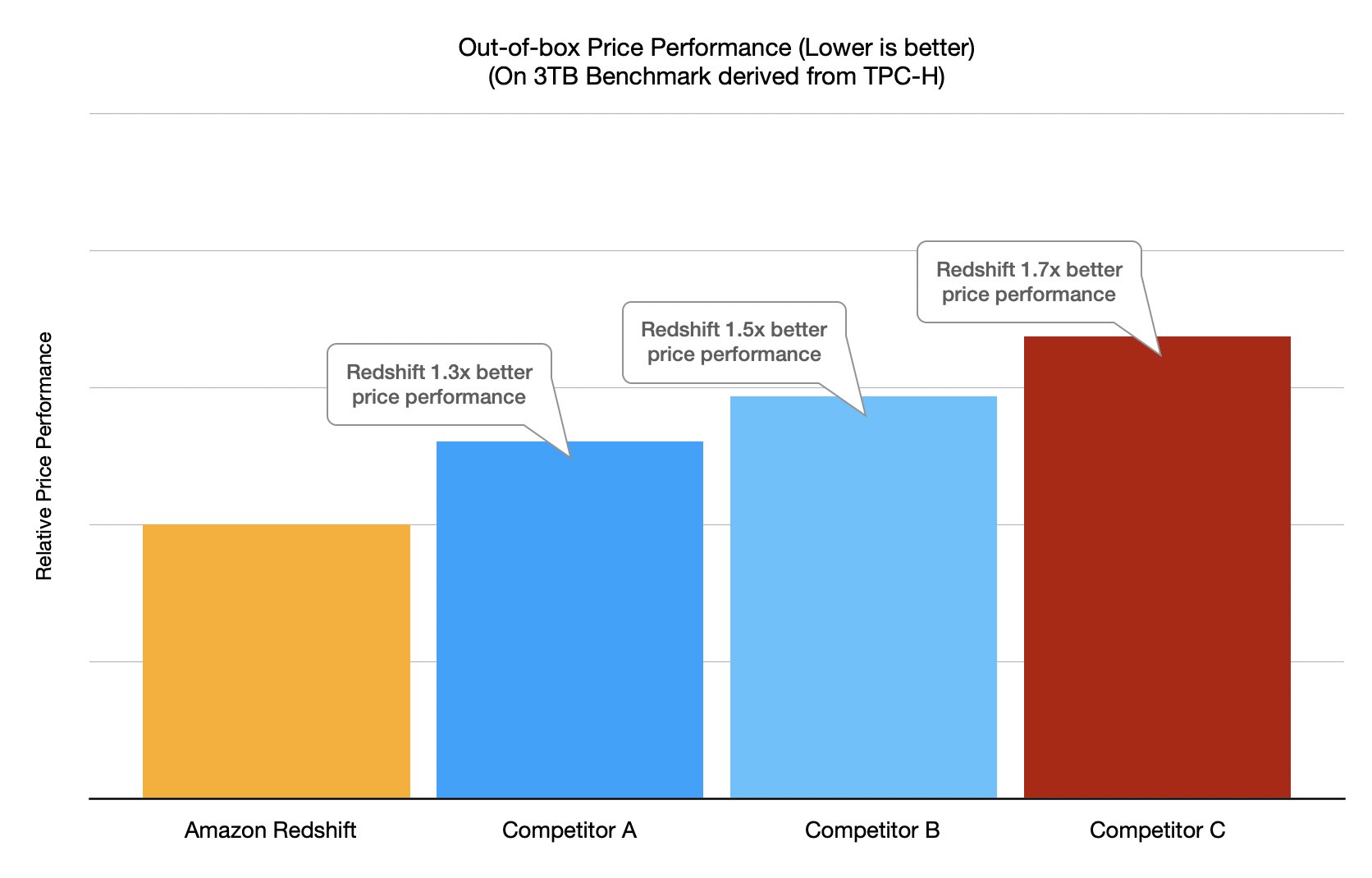
尽管这些基准测试再次证实了 Amazon Redshift 在性价比方面的领先地位,但我们始终建议您使用自己的概念验证工作负载来试用 Amazon Redshift,这是了解 Amazon Redshift 与您数据需求相符程度的最佳方式。
为您的工作负载找到最佳性价比
本文中使用的基准测试源自行业标准的 TPC-DS 和 TPC-H 基准测试,具有以下特性:
- 从 TPC-DS 和 TPC-H 不经修改地使用架构和数据。
- 从 TPC-DS 和 TPC-H 不经修改地使用查询。如果数据仓库不支持原定设置 TPC-DS 或 TPC-H 查询的 SQL 语言,则该数据仓库将使用 TPC 批准的查询变体。
- 该测试仅包括 99 个 TPC-DS 和 22 个 TPC-H SELECT 查询。不包括维护和吞吐量步骤。
- 使用 TPC-DS 和 TPC-H 套件的原定设置随机种子生成的查询参数,进行了三次全功率运行(单个流)。
- 计算性价比时使用的主要指标是查询总运行时间。运行时间采用三次运行中最好的一次。
- 将每小时成本(USD)乘以基准运行时间(以小时为单位)来计算性价比,这等于运行基准测试的成本。所有数据仓库均使用公开发布的按需定价。
我们将此基准测试称为云数据仓库基准测试,您可以使用 GitHub 上提供的脚本、查询和数据,轻松重现上述的基准测试结果。如前所述,它源自 TPC-DS 和 TPC-H 基准测试,因此不能与已发布的 TPC-DS 或 TPC-H 结果进行比较,因为我们的测试结果并未遵循该规范。
每个工作负载都有各自的特色,因此,如果您刚刚开始入门,概念验证是了解 Amazon Redshift 在您独特情况下表现如何的最佳方式。在运行自己的概念验证时,您必须关注正确的指标 – 查询吞吐量(每小时查询数)和性价比。您可以自行运行或者在 AWS 或系统集成和咨询合作伙伴的帮助下运行概念验证,从而做出数据驱动型决策。
结论
这篇文章讨论了我们在 Amazon Redshift 客户那儿发现的分析工作负载趋势,我们为提高 Amazon Redshift 性价比而推出的新功能,以及最新基准测试的结果。
如果您是 Amazon Redshift 的现有客户,请联系我们参加免费的优化研讨会,并简要了解在 AWS re:Invent 2021 上宣布的新功能。要了解 Amazon Redshift 的最新发展动态,请关注 Amazon Redshift 新增功能新闻源。