亚马逊AWS官方博客
Amazon SageMaker RL – Amazon SageMaker 提供的托管式强化学习
在过去几年中,机器学习 (ML) 让人们无比兴奋。事实上,从医学影像分析到自动驾驶卡车,ML 模型可以成功完成的复杂任务列表不断增长,但究竟是什么让这些模型如此智能呢?
简而言之,您可以通过几种不同的方式训练模型,其中包括以下三种方式:
- 监督式学习:对标记过的数据集(即包含样本和答案的数据集)运行算法。模型将逐步学会如何正确地预测正确的答案。回归和分类都属于监督式学习的示例。
- 非监督式学习:对未标记的数据集(即仅包含样本的数据集)运行算法。在这里,模型将逐步学习数据模式,并相应地组织整理样本。集群和主题建模都是非监督式学习的示例。
- 强化学习:这种方法与其他方法截然不同。这里,计算机程序(也称为代理)与其环境交互:大多数情况下,此类行动都在模拟器中执行。代理会收到针对其所采取行动的正面或负面反馈:反馈由用户定义的函数计算得出,该函数会输出一个数值,表示应该获得奖励的行动。通过尝试最大限度增加正面反馈,代理即可学习最优决策策略。
在 AWS re:Invent 2017 大会上发布的 Amazon SageMaker 旨在帮助客户快速构建、训练和部署 ML 模型。今天,随着 Amazon SageMaker RL 的推出,我们很高兴地将 Amazon SageMaker 的优势延伸到强化学习,让所有开发者和数据科学家都能更轻松地实现强化学习 – 不论其在 ML 领域的专业知识水平如何。
强化学习快速入门
强化学习 (RL) 乍听起来让人迷惑不解,所以我们通过示例来说明。假设有一个代理需要学习如何通过一个迷宫。模拟器允许它按照特定方向移动,但会阻止它穿过墙壁:利用 RL 学习策略,代理很快就可以开始采取更加相关的行动。
要理解的一件重要事情是,RL 模型并未经过一组预定义、带标记的迷宫(也就是监督式学习)的训练。相反,代理一步一步地探索其环境(当前迷宫),然后通过移动一步来获得反馈:进入死胡同将获得负面反馈,而向出口靠近一步则可以获得正面反馈。在处理过多个不同的迷宫之后,代理就会习得行动/反馈数据点,并对模型进行训练,以便下次制定更好的决策。这种探索和训练循环是 RL 的核心:只要有足够的迷宫和足够的训练时间,我们很快就能掌握穿越任何迷宫的方法。
RL 特别适合这样的情况:环境复杂、不可预测,而且构建先前数据集不可行或者成本过于高昂,但可以对这种环境进行模拟,包括自动驾驶汽车、游戏、投资组合管理、库存管理、机器人或工业控制系统。例如,研究人员已经证实,与基于规则的典型系统相比,为 HVAC 系统应用基于 RL 的控制措施可以节省 20%-40% 的成本 [1],而且也能大幅降低对生态系统的影响。
隆重推出 Amazon SageMaker RL
Amazon SageMaker RL 以 Amazon SageMaker 为基础构建,添加了预先打包的 RL 工具套件,可以轻松集成任何模拟环境。可以预见,训练和预测基础设施是完全托管式的,让您可以专注于 RL 问题,而非管理服务器。
如今,您可以利用 SageMaker 为 Apache MXNet 和 Tensorflow 提供的容器,包括 Open AI Gym、Intel Coach 和 Berkeley Ray RLLib。就像通常使用 Amazon SageMaker 一样,您可以利用其他 RL 库(例如 TensorForce 或 StableBaselines)轻松创建自己的自定义环境。
在模拟环境中,Amazon SageMaker RL 支持以下选项:
- 适用于 AWS RoboMaker 和 Amazon Sumerian 的第一方模拟器。
- 使用 Gym 接口开发的 AI Gym 环境和开源模拟环境,例如 Roboschool 或 EnergyPlus。
- 客户使用 Gym 接口开发的模拟环境。
- 商业模拟器,如 MATLAB 和 Simulink(客户需要管理自己的许可证)。
Amazon SageMaker RL 还附带了一系列 Jupyter 笔记本,就像 Amazon SageMaker 一样。可以在 Github 上获取这些笔记本,其中包括简单的示例(倒立摆、简单的走廊),此外还有各种领域的先进示例,例如机器人、运筹学、金融等。您可以轻松扩展这些笔记本,根据自己的业务问题对其进行自定义。
此外,您还可以找到展示如何利用同构或异构扩展来扩展 RL 的示例。后者对于许多 RL 应用程序尤为重要,因为在这些应用程序中,模拟在 CPU 上运行,训练在 GPU 上进行。您的模拟环境也可以采用本地或远程的方式在不同的网络中运行,SageMaker 会为您设置好一切。
不要担心,具体用法要比看起来容易得多。我们来看一个示例。
利用 Amazon SageMaker RL 实现预测式 Auto Scaling
Auto Scaling 允许您动态扩展服务(例如 Amazon EC2),根据您定义的条件自动增减容量。目前,这通常需要设置阈值、警报、扩展策略等。
让我们看看如何使用 RL 模型和自定义模拟器优化此过程,假设要对您的 Amazon EC2 容量进行扩展(当然,这只是一个简单例子)。为简洁起见,我在此处仅着重介绍最重要的代码片段:您可以在 Github 上找到完整的示例。
在这里,我们的目的是使实例容量适应负载配置文件。我们不希望预置不足(错失流量),也不希望过度预置(浪费资金):我们希望“恰到好处”。
用 RL 的语言来说:
- 该环境包含负载配置文件和多个正在运行的实例。
- 在每个步骤中,代理都可以执行两项操作:添加实例和移除实例。添加实例有助于处理更多事务,但需要花费资金,而且需要几分钟时间才能联机。移除实例可以节省资金,但会降低整体处理容量。
- 反馈是运行实例的成本与成功完成交易所创造的价值的组合,如果容量不足,则会造成重大损失。
设置模拟
首先,我们需要一个模拟器来生成类似于在大流量 Web 服务器上可以看到的负载配置文件:为此,我们使用一个非常简单的 Python 程序。这是一个绘制 3 天内每分钟事务量 (tpm) 的示例:以周期性事务为主,带有不可预测的突增峰值。
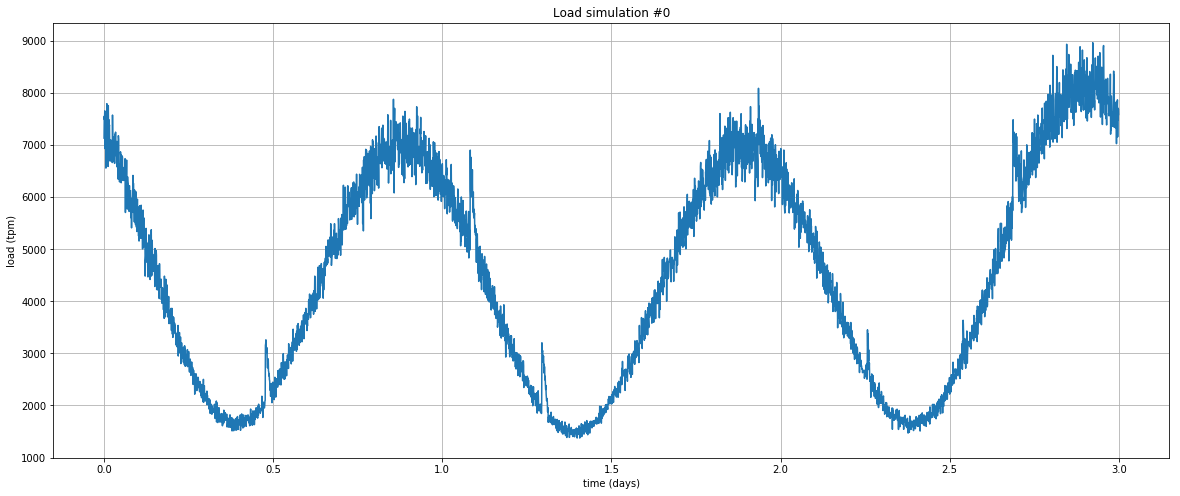
初始状态如下:
config_defaults = {
"warmup_latency": 5, # It takes 5 minutes for a new machine to warm up and become available.
"tpm_per_machine": 300, # Each machine can process 300 transactions per minute (tpm) on average
"tpm_sigma": 30, # Machine's TPM capacity is variable with +/- 30 standard deviation
"machine_cost": 0.05, # Machines cost $0.05/min
"transaction_val": 0.90, # Successful transactions are worth $0.90 per thousand (CPM)
"downtime_cost": 200, # Downtime is assumed to cost the business $200/min beyond incomplete transactions
"downtime_percent": 99.5, # Downtime is defined as availability dropping below 99.5%
"initial_machines": 50, # How many machines are initially turned on
"max_time_steps": 1000, # Maximum number of timesteps per episode
}
计算奖励
这个过程非常简单! 将当前负载与当前容量进行比较,扣除错失事务的成本,并为错失率超过 0.5% 的情况(相当严格的停机时间定义!)给予高比例惩罚。
def _react_to_load(self):
self.capacity = int(self.active_machines * np.random.normal(self.tpm_per_machine, self.tpm_sigma))
if self.current_load <= self.capacity:
# All transactions succeed
self.failed = 0
succeeded = self.current_load
else:
# Some transactions failed
self.failed = self.current_load - self.capacity
succeeded = self.capacity
reward = succeeded * self.transaction_val / 1000.0 # divide by thousand for CPM
percent_success = 100.0 * succeeded / (self.current_load + 1e-20)
if percent_success < self.downtime_percent:
self.is_down = 1
reward -= self.downtime_cost
else:
self.is_down = 0
reward -= self.active_machines * self.machine_cost
return reward模拟过程分步解析
下文说明了代理完成 RL 框架启动的每一个步骤。如上所述,该模型最初会预测随机行动,但经过几轮训练后,它会变得更加智能。
def step(self, action):
# First, react to the actions and adjust the fleet
turn_on_machines = int(action[0])
turn_off_machines = int(action[1])
self.active_machines = max(0, self.active_machines - turn_off_machines)
warmed_up_machines = self.warmup_queue[0]
self.active_machines = min(self.active_machines + warmed_up_machines, self.max_machines)
self.warmup_queue = self.warmup_queue[1:] + [turn_on_machines]
# Now react to the current load and calculate reward
self.current_load = self.load_simulator.time_step_load()
reward = self._react_to_load()
self.t += 1
done = self.t > self.max_time_steps
return self._observation(), reward, done, {}在 Amazon SageMaker 上进行训练
现在,我们已准备好训练模型,就像其他任何 SageMaker 模型一样:传递映像名称(此处是 Intel Coach 的 TensorFlow 容器)、实例类型等。
rlestimator = RLEstimator(role=role, framework=Framework.TENSORFLOW, framework_version='1.11.0', toolkit=Toolkit.COACH, entry_point="train-autoscale.py", train_instance_count=1, train_instance_type=p3.2xlarge) rlestimator.fit()
在训练日志中,可以看到代理首先在未经过任何训练的情况下探索其环境:这称为热身阶段,用于生成要学习的初始数据集。
## simple_rl_graph: Starting heatup
Heatup> Name=main_level/agent, Worker=0, Episode=1, Total reward=-39771.13, Steps=1001, Training iteration=0
Heatup> Name=main_level/agent, Worker=0, Episode=2, Total reward=-3089.54, Steps=2002, Training iteration=0
Heatup> Name=main_level/agent, Worker=0, Episode=3, Total reward=-43205.29, Steps=3003, Training iteration=0
Heatup> Name=main_level/agent, Worker=0, Episode=4, Total reward=-24542.07, Steps=4004, Training iteration=0
...热身阶段完成后,模型将经历重复学习循环(又称为“策略训练”)和基于学习内容的探索(又称为“训练”)。
Policy training> Surrogate loss=-0.09095033258199692, KL divergence=0.0003891458618454635, Entropy=2.8382163047790527, training epoch=0, learning_rate=0.0003
Policy training> Surrogate loss=-0.1263471096754074, KL divergence=0.00145535240881145, Entropy=2.836780071258545, training epoch=1, learning_rate=0.0003
Policy training> Surrogate loss=-0.12835979461669922, KL divergence=0.0022696126252412796, Entropy=2.835214376449585, training epoch=2, learning_rate=0.0003
Policy training> Surrogate loss=-0.12992703914642334, KL divergence=0.00254297093488276, Entropy=2.8339898586273193, training epoch=3, learning_rate=0.0003
....
Training> Name=main_level/agent, Worker=0, Episode=152, Total reward=-54843.29, Steps=152152, Training iteration=1
Training> Name=main_level/agent, Worker=0, Episode=153, Total reward=-51277.82, Steps=153153, Training iteration=1
Training> Name=main_level/agent, Worker=0, Episode=154, Total reward=-26061.17, Steps=154154, Training iteration=1
在模型达到我们设定的时期数量后,训练就完成了。在本例中,我们进行了 18 分钟的训练:让我们来看看模型的学习效果。
![]()
直观呈现训练效果
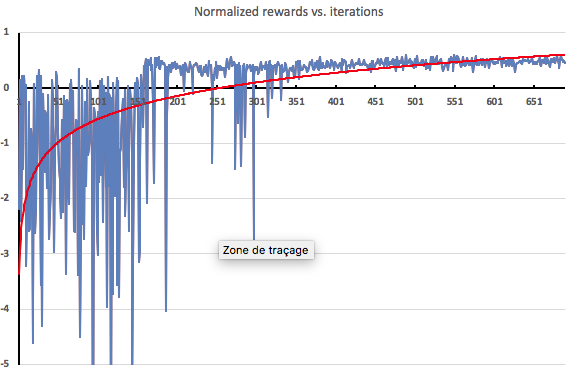
了解训练效果的一种方法就是将代理在每次探索迭代后收到的反馈绘制成图表。正如预期的那样,在热身阶段(150 次迭代)的反馈非常消极,因为此时代理根本没有接受过训练。随后,接受训练后,反馈就会迅速改善。
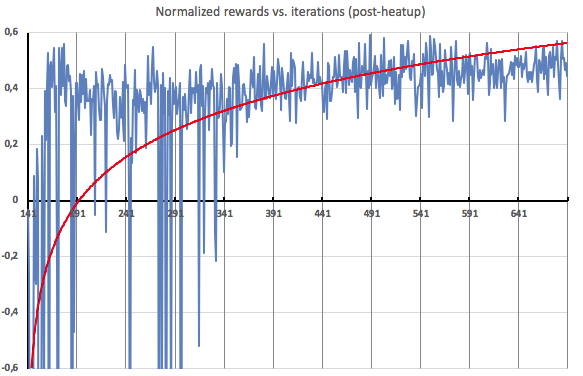
下文详细说明了热身后迭代的情况。如您所见,在热身阶段大约过半之后,代理开始收到高度一致的正面反馈,这表明它能够对其发现的负载配置文件进行有效的扩展。
部署模型
对模型感到满意后,就可以像部署任何 SageMaker 模型一样对其进行部署,并使用新创建的 HTTPS 终端节点进行预测。或者,如果您正在训练机器人,也可以使用 AWS Greengrass 在边缘设备上进行部署。
现已推出
我希望这篇博文提供了丰富的有用信息。本文对于 Amazon SageMaker RL 功能的介绍只是冰山一角。目前,您可以在已推出 Amazon SageMaker 的所有区域使用 RL。不妨开始体验,并与我们分享您的想法。我们迫不及待想看看您创建的成果!
— Julien;
[1]“Deep Reinforcement Learning for Building HVAC Control”(用于构建 HVAC 控制装置的深度强化学习),T. Wei、Y. Wang 和 Q. Zhu,DAC’17,2017 年 6 月 18-22 日,美国德克萨斯州奥斯汀。