亚马逊AWS官方博客
使用 Amazon AppFlow 与 Amazon Athena 分析 Google Analytics 数据
Original URL:https://aws.amazon.com/cn/blogs/big-data/analyzing-google-analytics-data-with-amazon-appflow-and-amazon-athena/
软件即服务(SaaS)应用正在快速普及,市场占有率亦一路飙升。在制定各类具有决定性影响的业务决策时,这部分数据当然不容忽视。Amazon AppFlow是一项全托管集成服务,能够帮助大家将SaaS系统中的数据安全传输至数据湖。大家可以按需、按计划或者在事件发生之后运行数据传输流。您可以使用Amazon Athena快速分析这部分数据,并将其与存储在Amazon Simple Storage Service(Amazon S3)上的众多数据集相结合。您还可以引入多个SaaS数据集,并通过Athena联邦查询功能将这些数据集与位于传统数据库(例如Amazon Relational Database Servce,简称Amazon RDS)中的运营数据汇总起来。
在本文中,我们将分步了解如何使用Amazon AppFlow提取Google Analytics数据,并将其存储在Amazon S3中以供后续使用Athena加以查询。
架构概述
下图所示,为本文中描述的流程。大家首先需要在Amazon AppFlow内部创建一个新流程,用于将Google Analytics数据传输至Amazon S3。传输的数据格式为多行JSON,但Athena无法支持这种格式。我们需要使用AWS Lambda函数将该JSON格式文件转换为Apache Parquet格式。通过这样的转换,大家即可高效且经济地运行查询。该函数还可包含其他变换机制,例如变更Amazon S3前缀以及使用Hive式分区进行数据存储等。Amazon AppFlow还支持在调度作业中仅提取新数据,随后使用Amazon S3事件触发器及Lambda转换函数开发出适合实际需求的自动化工作流。Amazon AppFlow目前在全球15个区域内正式上线,请在您S3存储桶所在的区域使用AppFlow。在本次演练中,我们使用美国东部(北弗吉尼亚州)区域。

在本文中,我们将使用示例Google账户、具有适当权限的OAuth客户端以及Google Analytics数据。当然,大家也可以使用自己的Google资源。要从Amazon AppFlow中启用对Google Analytics的访问,为此,我们需要预先置备一个新的OAuth客户端,具体操作步骤如下:
- 在Google API控制台(https://console.developers.google.com)上,选择Library。
- 在搜索字段中输入
analytics。 - 选择Google Analytics API。
- 选择ENABLE 并返回上一页。
- 在列出的搜索结果中选择Google Analytics Reporting API。
- 选择ENABLE 并返回主页。
- 选择OAuth consent screen。
- 创建一个新的Internal应用(如果您使用的是个人账户,请选择 External)。
- 添加com作为Authorized domains。
- 选择Add scope。
- 添加../auth/analytics.readonly作为Scopes for Google APIs。
- 选择Save。
- 选择Credentials。
- 添加OAuth client ID credentials。
- 选择Web application。
- 输入
https://console.aws.amazon.com/作为授权的JavaScript原始URL。 - 输入
https://AWSREGION.console.aws.amazon.com/appflow/oauth作为授权的重新定向URL。 (将AWSREGION替换为您当前使用的区域。如果您在us-east-1, 中使用Amazon AppFlow,则输入https://console.aws.amazon.com/appflow/oauth。) - 选择Save。
设置Lambda与Amazon S3
我们首先需要创建一个新的S3存储桶,作为Amazon AppFlow的传输目的地。接下来,我们编写一个新的Lambda函数,使用pandas与pyarrow模块将JSON格式的数据转换为Parquet格式。最后,我们对Amazon S3事件触发器进行设置,要求其在有新的Amazon S3对象创建活动时自动调用Lambda函数。
创建一个新的S3存储桶
要创建一个Amazon S3存储桶,请完成以下操作步骤:
- 在Amazon S3控制台上,选择Create bucket。
- 为您的存储桶输入名称,例如
appflow-ga-sample。 - 选择Create bucket。
为您的Lambda层准备.zip文件
要创建一个包含pandas与pyarrow模块的.zip文件,请完成以下操作步骤:
- 设置一套能够运行Docker的环境。
- 运行以下命令:
- 在Amazon S3控制台上,选择
appflow-ga-sample。 - 选择Create folder。
- 为您的文件夹输入名称,例如
lambda-layer。 - 选择Save。
- 选择lambda-layer。
- 选择Upload。
- 选择pandas-pyarrow.zip,而后选择Upload。
为Parquet导出创建一个Lambda层
要创建一个Lambda层,请完成以下操作步骤:
- 在Lambda控制台上,选择 Layers。
- 选择Create layer。
- 在name部分,输入您的层名称,例如
pandas-parquet。 - 选择Upload a file from Amazon S3。
- 在Amazon S3 link URL部分,为您的zip文件输入一条Amazon S3路径,例如
s3://appflow-sample/lambda-layer/pandas-parquet.zip。 - 在 Compatible runtimes部分,选择Python 3.6。
- 选择Create。


为数据转换创建Lambda函数
要创建Lambda函数并触发对应的Amazon S3事件,请完成以下操作步骤:
- 在Lambda控制台上,选择Create function。
- 选择Author from scratch。
- 在Function name部分,为您的函数输入名称,例如
ga-converter。 - 在Runtime部分,选择 Python 3.6。
- 选择Create a new role with basic Lambda permissions。
- 选择Create function。

- 在Lambda函数配置部分,在Function code中的lambda_function 部分输入以下代码。

这条Lambda函数负责下载AppFlow输出文件,从Google Analytics JSON文件中提取必要数据,而后将其转换为Parquet格式。最后,它使用另一个键名将其再次上传至Amazon S3。大家可以修改脚本内容(特别是维度与值名称部分),或者根据需要进行其他转换。
添加层
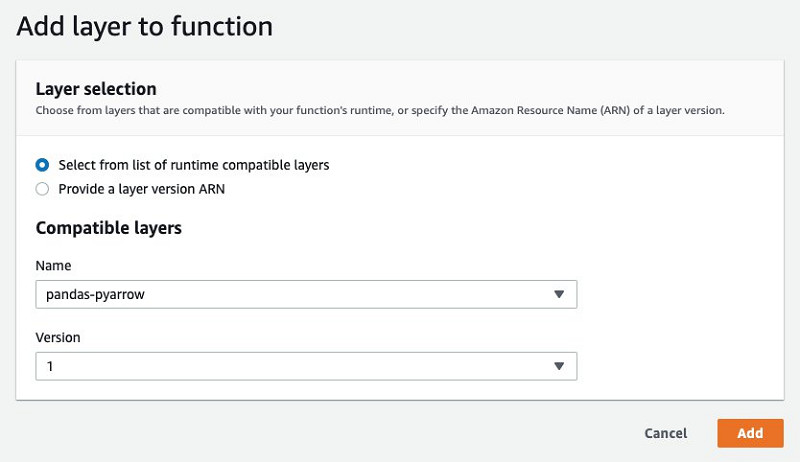
要向您的Lambda函数中添加其他层,请完成以下操作步骤:
- 在Designer当中选择Layers。
- 选择Add a layer。
- 选择Select from list of runtime compatible layers。
- 在Name部分,选择pandas-pyarrow。
- 在Version部分,选择1。
- 选择Add。

上调超时设置
要上调Lambda超时设置,请完成以下操作步骤:
- 在Configuration选项卡中的Basic settings下,选择Edit。
- 将Timeout设置为30 sec。
- 选择Save。
- 在Configuration选项卡中,选择Save。
添加事件触发器
要添加Amazon S3事件触发器,请完成以下操作步骤:
- 在Designer部分,选择Add trigger。
- 选择S3,再选择我们之前创建的存储桶。
- 在Event type部分,选择All object create events。
- 在Prefix部分,输入
raw。 - 选择Add。


添加权限
要为Lambda函数添加适当的权限以读取及写入Amazon S3对象,请完成以下操作步骤:
- 在Permissions选项卡上,输入角色名称,例如
ga-converter-role-zm6u0f4g。 - 在AWS Identity and Access Management (IAM)控制台上,选择Policies。
- 选择 Create Policy。
- 在JSON 选项卡中,输入以下策略 (将目标存储桶名称
arn:aws:s3:::appflow-ga-sample*替换为您的实际存储桶名称)。 - 选择Review policy。
- 为您的新策略输入一个名称,例如
lambda-s3-ga-converter-policy。 - 选择Create policy。
- 在IAM控制台上,选择
- 在搜索字段内输入您的角色名称(
ga-converter-role-zm6u0f4g)。 - 选择您的角色。
- 选择Attach policies。
- 选择lambda-s3-ga-converter-policy。
- 选择Attach policy。
设置Amazon AppFlow
现在,我们可以创建一个新的Amazon AppFlow流,将数据从Google Analytics转移至Amazon S3。要创建新的Amazon AppFlow传输流,请完成以下操作步骤:
- 在Amazon AppFlow控制台中,选择Create flow。
- 为您的流输入名称,例如
my-ga-flow。 - 选择Next。
- 在Source name部分,选择 Google Analytics。
- 选择Create new connection。
- 输入您的OAuth客户端ID与客户端secret,而后为连接命名,例如
ga-connection。 - 在弹出的窗口中,选择允许amazon.com访问Google Analytics API。
- 在Choose Google Analytics object部分,选择Reports。
- 在Choose Google Analytics view部分,选择All Web Site Data。
- 在Destination name部分,选择Amazon S3。
- 在Bucket details部分,选择我们之前创建的存储桶。
- 输入
raw作为前缀。 - 选择 Run on demand。

- 选择Next。
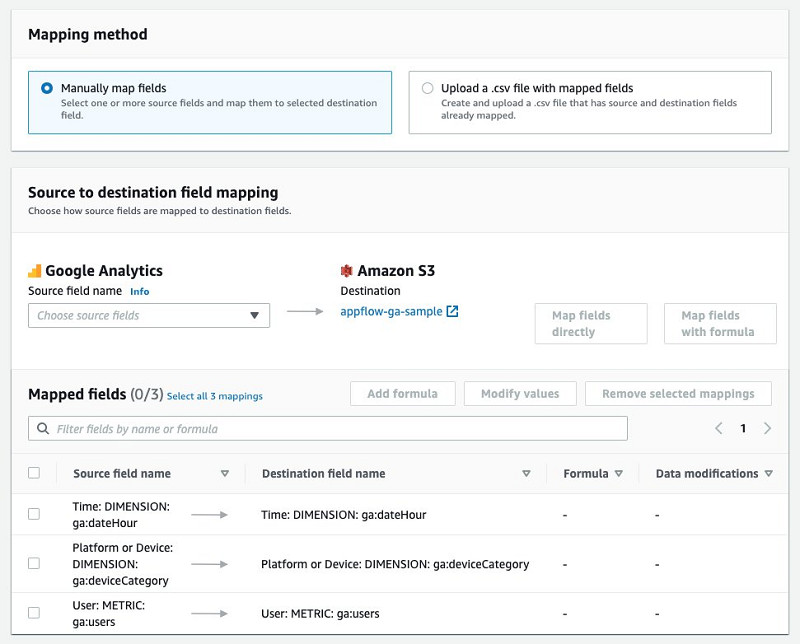
- 选择Manually map fields。
- 为Source field name选择以下三个字段:
- Time: DIMENSION: ga:dateHour
- Platform or Device: DIMENSION: ga:deviceCategory
- User: METRIC: ga:users
- 选择Map fields directly。

- 选择 Next。
- 在Add filters部分,选择Next。
- 选择Create flow。

实际运行
在新流创建完成之后,即可随时按需运行:
- 在Amazon AppFlow控制台上,选择my-ga-flow。
- 选择Run flow。
在本实验中,为便于理解,建议您选择按需执行作业。 实际上,您可以选择计划的作业并仅定期提取新添加的数据。 Amazon S3事件触发器还可以帮助您自动转换数据。
通过Athena查询数据
大家需要在查询前先创建一个外部表,具体操作步骤如下:
- 在Athena控制台上,向查询编辑器内输入
create database appflow_data。 - 选择 Run query。
- 在查询编辑器内输入以下命令(将目标存储桶名称
appflow-ga-sample替换为您的实际存储桶名称): - 选择Run query。
现在,我们可以查询Google Analytics数据了。输入以下查询即可实际运行。这项查询将显示一小时周期之内,网站访问中占比最高的设备类型:
以下截屏,为此项查询的结果。
总结
本文向大家介绍了如何使用Amazon AppFlow将Google Analytics数据传输至Amazon S3,并使用Amazon Athena对数据进行分析。利用这套架构,大家无需自主构建专门面向Google Analytics或者其他SaaS应用的数据提取应用程序。Amazon AppFlow使您能够一次性建立起全自动数据传输与转换工作流,以及与之配套的集成查询环境。