亚马逊AWS官方博客
Apache MXNet 版本添加了对新的 NVIDIA Volta GPU 和 Sparse Tensor 的支持
我们对 Apache MXNet 版本 0.12 的发布感到很兴奋。MXNet 社区的参与者密切合作,为用户带来了新的增强功能。在此版本中,MXNet 添加了两项新的重要功能:
- 对 NVIDIA Volta GPU 的支持,这使用户能够大大减少神经网络模型的训练和推理时间。
- 对 Sparse Tensor 的支持,这使用户能够以最有利于存储和计算的方式使用稀疏矩阵训练模型。
对 NVIDIA Volta GPU 架构的支持
MXNet v0.12 版本添加了对 NVIDIA Volta V100 GPU 的支持,这使客户训练卷积神经网络的速度比 Pascal GPU 的速度快 3.5 倍。训练神经网络涉及数万亿次的浮点数 (FP) 乘法与加法运算。这些计算通常已使用单精度 (FP32) 完成以实现较高的准确度。但是,最近的研究表明,用户可以通过使用半精度 (FP16) 数据类型的训练获得与使用 FP32 数据类型的训练相同的准确度。
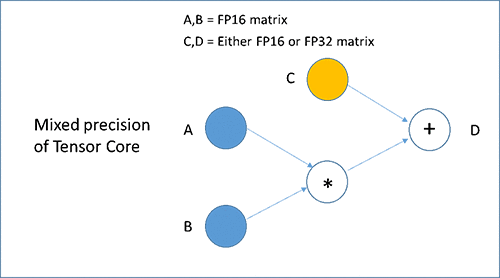
Volta GPU 架构引入了 Tensor Core。每个 Tensor Core 每个时钟周期可执行 64 次乘法和加法混合运算,约为每个 CUDA 核心在每个时钟周期内执行的 FLOPS 的四倍。每个 Tensor Core 执行如下所示的运算:D = A x B + C,其中 A 和 B 是半精度矩阵,而 C 和 D 可以是半精度或单精度矩阵,从而执行混合精度训练。利用新的混合精度训练,用户可以通过对网络的大多数层使用 FP16 并在必要时使用更高精度的数据类型来获得最佳训练绩效,且不会降低精度。
MXNet 使用户能够轻松使用 FP16 训练模型以利用 Volta Tensor Core。例如,您只需在 MXNet 中通过将以下命令选项传递到 train_imagenet.py 脚本即可启用 FP16 训练。
最近,我们宣布推出一套新的 AWS Deep Learning AMI,它们预安装了针对 Amazon EC2 P3 实例系列中的 NVIDIA Volta V100 GPU 进行了优化的各种深度学习框架,其中包括 MXNet v0.12。只需在 AWS Marketplace 中单击一下鼠标即可开始;或者,您也可以按照此分步指南操作,开始使用您的第一个笔记本。
Sparse Tensor 支持
MXNet v0.12 添加了对 Sparse Tensor 的支持,可高效地存储和计算大部分元素为零的张量。我们都很熟悉 Amazon 基于您过去的购买历史记录给出的推荐,并且熟悉 Netflix 基于您过去的查看历史记录和对其他节目的评分给出的节目推荐。这类适用于数百万人的基于深度学习的推荐引擎涉及大部分元素为零的稀疏矩阵的乘法与加法运算。以与在稠密矩阵之间执行矩阵运算相同的方式在稀疏矩阵之间执行的数万亿次矩阵运算在存储和计算方面的效率不高。在默认的稠密结构中存储和操作这类包含许多零元素的稀疏矩阵会导致浪费内存以及对零元素执行不必要的处理。
为了解决这类难点,MXNet 启用了 Sparse Tensor 支持,使 MXNet 用户能够以最有利于存储和计算的方式执行稀疏矩阵运算并更快地训练深度学习模型。MXNet v0.12 支持两大稀疏数据格式:Compressed Sparse Row (CSR) 和 Row Sparse (RSP)。CSR 格式经过优化,可表示包含大量列的矩阵,其中每个行仅包含几个非零元素。RSP 格式经过优化,可表示包含大量行的矩阵,其中大部分行切片都完全是零元素。例如,CSR 格式可用于为推荐引擎编码输入数据的特征向量,而 RSP 格式可用于在训练期间执行稀疏梯度更新。对于大多数常用的运算符 (例如,矩阵点积和元素级运算符),此版本启用对 CPU 的稀疏支持。未来版本中将添加对更多运算符的稀疏支持。
以下代码段说明如何将 scipy CSR 矩阵转换为 MXNet CSR 格式,并使用其中一个向量对其执行稀疏矩阵向量乘法运算。要了解有关在 MXNet 中使用新稀疏运算符的更多信息,请参阅这些教程。
后续步骤
MXNet 的入门很简单。可在发行说明中找到此版本的完整更改列表。如果您有疑问或建议,请给我们留言。
作者简介
 Sukwon Kim 是 AWS Deep Learning 的高级产品经理。他负责开发让客户能够更轻松地使用深度学习引擎的产品,工作重点是开源 Apache MXNet 引擎。在业余时间,他喜欢徒步旅行和旅游。
Sukwon Kim 是 AWS Deep Learning 的高级产品经理。他负责开发让客户能够更轻松地使用深度学习引擎的产品,工作重点是开源 Apache MXNet 引擎。在业余时间,他喜欢徒步旅行和旅游。