亚马逊AWS官方博客
Auto Scaling 现在可用于 Amazon SageMaker
AWS ML 平台团队产品经理 Kumar Venkateswar 分享有关 Auto Scaling with Amazon SageMaker 公告的详细信息。
借助 Amazon SageMaker,成千上万的客户能够轻松地构建、训练和部署其 Machine Learning (ML) 模型。如今,使用 Auto Scaling for Amazon SageMaker,我们可以更轻松地管理生产 ML 模型。现在,您可以让 SageMaker 根据 AWS Auto Scaling 策略自动扩展实例数,而不必通过手动管理实例数来匹配推理所需的规模。
对于许多客户来说,SageMaker 简化了 ML 的管理过程。我们发现,客户采用托管的 Jupyter notebook 和托管的分布式训练。我们还发现,客户在将 Machine Learning 与应用程序进行集成的过程中,要将其模型部署到 SageMaker 推理主机上。SageMaker 可以使此操作变得轻松 – 您不必考虑对推理主机上的操作系统 (OS) 或框架进行修补,也不必跨可用区配置推理主机。只需将模型部署到 SageMaker,剩下的操作交给 SageMaker 即可。
到目前为止,您需要为每个终端节点 (或生产变体) 指定实例数量和类型才能提供推理所需的规模。如果推理容量发生变化,您可以更改为每个终端节点提供支持的实例的数量和/或类型,以适应相关变化,而不会引发停机。除了可以轻松更改配置,客户还询问我们怎样才能更轻松地管理 SageMaker 的容量。
借助 Auto Scaling for Amazon SageMaker,在 SageMaker 控制台、AWS Auto Scaling API 和 AWS SDK 中执行此操作要容易得多。如今,客户可以配置 AWS Auto Scaling 要使用的扩展策略,而不必密切监控推理容量以及通过更改终端节点配置做出响应。作为响应,Auto Scaling 会根据实际工作负载上调或下调实例数量,这使用策略中定义的 Amazon CloudWatch 指标和目标值来确定。这样,客户便可自动调整其推理容量,从而以较低的成本来维持可预测的性能。您只需指定每个实例的目标推理吞吐量,并为每个生产变体提供实例数上限和下限。之后,SageMaker 将利用 Amazon CloudWatch 警报来监控每个实例的吞吐量,并根据需要上调或下调预置容量。
使用 Auto Scaling 配置终端节点后,SageMaker 将继续监控您部署的模型以便自动调整实例数量。SageMaker 会将吞吐量保持在所需的级别内,从而响应应用程序流量的更改。如此一来,可以在生产中更轻松地管理模型,并且帮助降低已部署模型的成本,因为您不再需要预置足够的容量便可管理峰值负载。您只需配置满足最小预期流量和最大峰值需求的限值,Amazon SageMaker 将在这两个限值范围内工作,从而将成本降到最低。
如何开始使用?打开 SageMaker 控制台。对于现有终端节点,首先访问相应终端节点以修改设置。
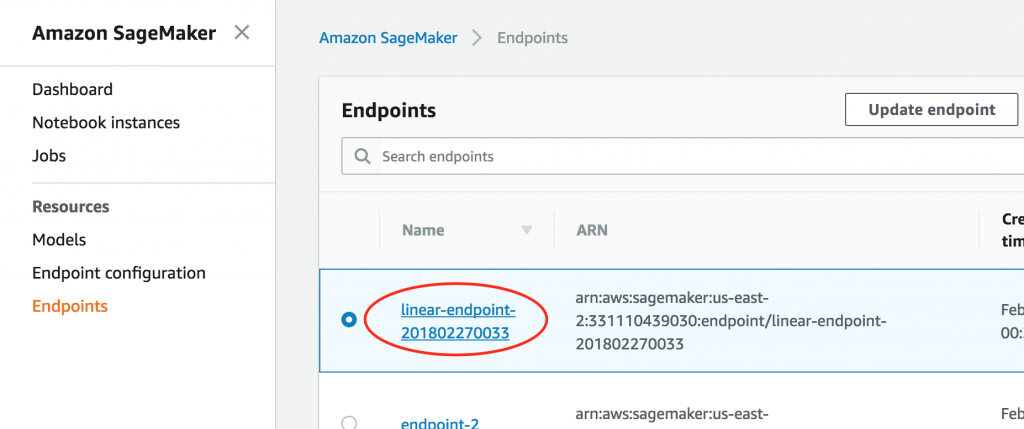
然后,滚动到 Endpoint runtime settings (终端节点运行时设置) 部分,选择变体,然后选择 Configure auto scaling (配置 Auto scaling)。
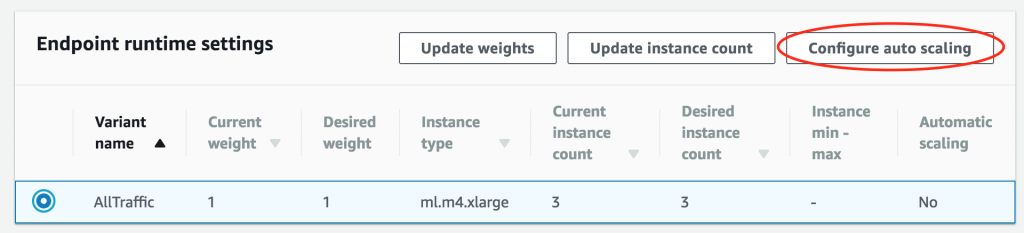
首先,配置最大和最小实例数。
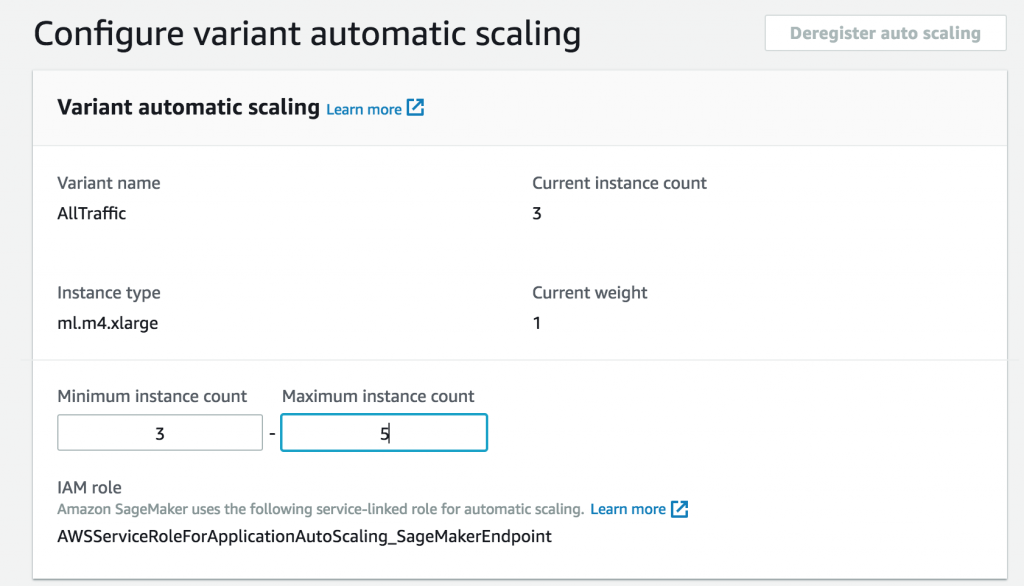
接着,根据以前的负载测试,选择您想通过其添加其他实例的每个实例的吞吐量。
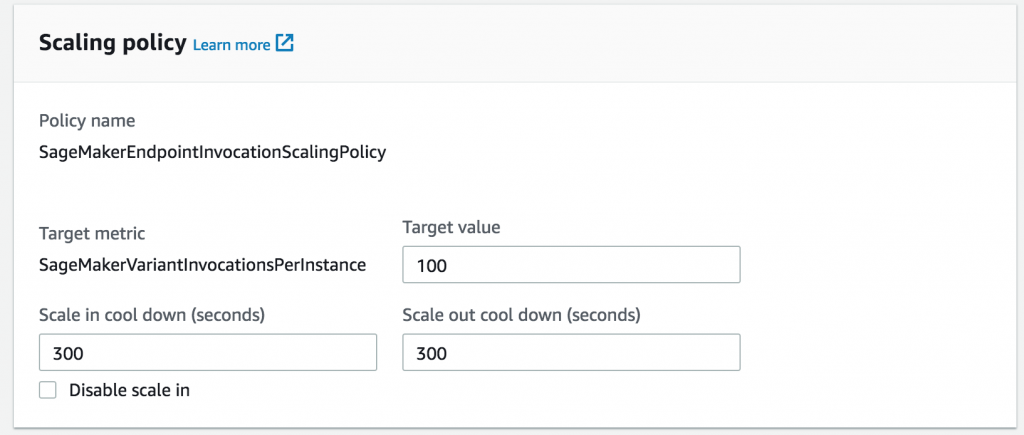
您可以选择设置向内或向外扩展的冷却时间,以免在工作负载出现剧烈波动时发生振荡。如果不设置冷却时间,SageMaker 将采用默认值。
这样就大功告成了!现在,您的一个终端节点将会随着推理的不断增加而自动进行扩展。
您按照常规的 SageMaker 现收现付定价为使用的容量付费,这样,您将不再需要为相对空闲时间不使用的容量付费!
目前,Auto Scaling in Amazon SageMaker 面向以下 AWS 区域推出:美国东部 (弗吉尼亚北部和俄亥俄)、欧洲 (爱尔兰) 和美国西部 (俄勒冈)。要了解更多信息,请参阅 Amazon SageMaker Auto Scaling 文档。

Kumar Venkateswar 是 AWS ML 平台团队的产品经理,AWS ML 平台包括 Amazon SageMaker、Amazon Machine Learning 和 AWS Deep Learning AMI。工作之余,Kumar 喜欢拉小提琴、玩万智牌。