亚马逊AWS官方博客
浅谈AWS CloudFront在特殊场景下的配置和错误处理
近期笔者参与了一个视频加速传输的项目,他们产品的用户遍及全球各地。为了将视频内容快速稳定提供给他们的客户,他们原先开发和部署了自己的CDN网络,但随着业务的发展,自建的CDN网络已经很难支撑不断增长的用户规模,我们与客户一起构建基于AWS Cloudfront与自建CDN的混合部署满足更大的业务需求。本文适用于AWS Global Region环境,分为以下两部分内容:
-
- 第一部分介绍了如何通过Lambda@Edge替待presigned url来防止Cloudfront内容被非法访问。
- 第二部分介绍了在使用Cloudfront过程中针对发生的问题如何进行分析和排除。
1. 使用Lambda@Edge替代presigned url实现防盗链
AWS官方提供了Pre-signed URL功能防止对通过CloudFront内容的非法访问,但是在测试过程中,我们发现部分安卓、低端设备对于可以接受的URL的长度有限制,进而导致Pre-signed URL不被接受。为了解决此问题,需要将客户自研CDN的防盗链机制和Cloudfront通过Lambda@edge结合在一起。在此过程中有以下几点注意事项:
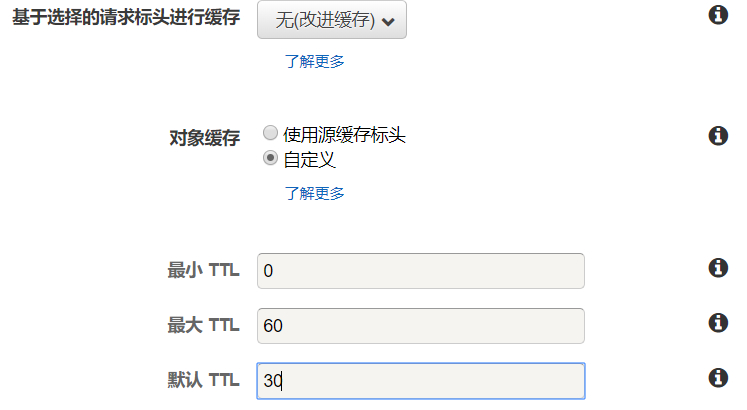
a. 针对HLS视频配置m3u8文件的缓存行为时,需要通过下图的设置将其设置成为不缓存:

提示:这里需要说明的是,虽然大多数情况下,只要缓存TTL小于TS分片产生的时间间隔就可以进行缓存(参考文档)。但在本场景中,由于每个客户机顶盒设备获取的m3u8文件内容都不相同,无需缓存,因此我们将TTL全部设置为0。
同时通过下列设置将客户端设备访问内容时所带的用于识别身份的查询串token除了在lambda@edge中进行处理外,还通过CloudFront转发给作为源的客户自研CDN,这样客户自研CDN在接收到token后可以将将其附加到其产生的m3u8文件中的TS分片连接(这里需要说明的是用户自研CDN并不是像CloudFront一样是一个纯粹的内容分发网络,它还具有视频转码和重新分片的功能):

b. 针对HLS视频配置TS文件的缓存行为时,由于是实时视频(作为源的客户自研CDN每3秒产生一个m3u8文件,里面包含3个播放时长是3秒的TS分片),所以无需缓存太长时间:
另外对于终端设备访问TS文件时所带的token查询串,则交由Lambda@edge处理,无需再传递给作为源的客户自研CDN:

c. 在AWS控制台创建下列Lambda函数对终端设备访问m3u8和ts文件是所带的查询串中的token进行验证:
提示:(1)Lambda函数必须在N. Virginia区域(US East)创建 。
(2)创建函数时可以选择使用cloudfront-modify-reponse-header作为蓝图然后再进行修改。

Lambda函数创建完后,可以如下图所示在控制台选择Cloudfront作为触发器,将其与对应的m3u8和ts缓存行为的viewer request关联起来:



2. Cloudfront的错误分析和调试步骤
下面把在环境构建过程中遇到的问题以及排错建议罗列如下:
a. 可能发生在源站上:源站返回HTTP 5xx错误
b. 也可能发生在CloudFront上:CloudFront无法连接到源站
c. 还可能发生在Lambda @ Edge上:Lambda @ Edge代码抛出未处理的异常
为了确保内容可以以最小的中断时间持续交付给用户,当Cloudfront内容交付失败时,我们需要快速定位问题并迅速采取措施解决问题。 在下文中我们描述了如何通过下列四个步骤来对AWS内容交付中可能遇到的问题进行分析和调试:
2.1启用CloudFront日志记录
要分析问题发生的原因,首先要有可供分析的日志数据,因此我们需要配置CloudFront输出包含有关其所接收的每个用户请求的详细信息的日志文件。 具体操作步骤如下图所示,登录AWS管理控制台然后转到CloudFront控制台,在CloudFront分配的常规配置选项中启用日志记录(Logging)。

启用日志记录后,CloudFront会开始将访问日志以W3C扩展日志文件格式存放到配置中指定的Amazon S3存储桶(日志输出会有一定时间的延迟)。
提示:如果需要减少日志文件的存储成本,你可以利用S3对象生命周期管理功能(参见S3 Object Lifecycle management)在一段时间后删除日志或将日志移动到更便宜的Glacier存储层。
接下来你可以设置Amazon Athena以便于查询CloudFront访问日志。 Athena是一种交互式查询服务,可以使用标准SQL查询轻松分析Amazon S3日志中的数据。 Athena是无服务器的,因此没有需要管理的基础架构,你只需为运行的查询付费。 您可以按照以下步骤完成Athena的设置:
在Athena中创建 CloudFront日志表
将以下 DDL 语句复制并粘贴到 Athena 控制台中。修改语句中用于存储日志的 Amazon S3 存储桶的名字。
在 Athena 控制台中运行上述查询后Athena会注册 cloudfront_logs 表,后面我们就可以通过SQL语句来查询Cloudfront日志数据了。
提示:为了减少查询CloudFront日志所需的成本和时间,你可以按照此博客文章中的指导对日志文件进行分区。
2.2设置CloudWatch告警
日志文件为我们提供了Cloudfront出现问题时可以用于分析的数据,但我们还需要一种在问题出现时可以及时通知运维管理人员的机制。 为了发送警报通知,我们建议使用Amazon SNS这种完全托管的发布/订阅消息服务。首先我们打开Amazon SNS控制台,创建一个针对特定主题的邮件消息订阅:

接着我们可以在Amazon CloudWatch里面配置告警。CloudFront与CloudWatch是完全集成的,它可以以1分钟的粒度自动发布针对每个Cloudfront分配的六个监控指标 (请求,下载字节数,上载字节数,4xx错误率,5xx错误率,总错误率),如果有与Cloudfront分配相关联的lambda函数,CloudFront还会为每个分配发布额外的四个监控指标(Lambda@Edge 的 5xx 错误率, Lambda执行错误 , 无效函数响应错误和Lambda Throttles )。 我们可以在CloudFront控制台或CloudWatch控制台中根据这些指标设置监控告警。 例如要在CloudWatch控制台中根据5xxErrorRate指标设置警报,我们可以执行以下操作:
a. 在AWS控制台中,打开相应区域(例子中是us-east-1)中的CloudWatch控制台。
b. 在“ Alarms”选项卡上,为需要监控的CloudFront分配ID选择 Create Alarm > Select metric > CloudFront > Per-Distribution Metrics > 5xxErrorRate,然后在“Period”输入1分钟。
c. 根据应用程序监控要求设置5xxErrorRate的触发警报阀值。
d. 在“Send notification to:”设置中 ,选择之前创建的SNS主题。
e. 选择Create Alarm 。

配置完成后起初告警的状态是INSUFFICIENT_DATA,但很快就会变为OK 状态。

2.3 分析和解决CloudFront上发生的内容交付问题
当接收到告警时,我们首先需要区分问题是由CloudFront还是由Lambda @ Edge函数引起,以便后续可以使用正确的工具进行故障排除。 要帮助确定错误背后的原因,我们可以打开CloudFront控制台上的监控仪表板(Monitoring dashboard ) ,选择并查看Cloudfront分配的指标和关联的Lambda函数指标。例如假设我们收到了上文中根据5xxErrorRate指标设置的警报触发产生的通知,我们可以按照以下步骤跟踪发生的情况:
a. 在CloudFront控制台中,选择“ Monitor” 。
b. 搜索并选择您的CloudFront分配,然后选择View distribution metrics 。

c. 首先看一下Error rate仪表板。 如果发现是Lambda @ Edge导致5xx错误,那么我们可以跳到下一章节描述的步骤:调试Lambda @ Edge函数来处理这个问题。 否则的话我们可以确认错误是由CloudFront引起的,我们可以按照下列步骤进行进一步的分析以查看导致它们的原因。

d. 在Athena中对CloudFront日志文件执行以下查询语句来统计分析错误。下面的第一个查询按错误代码统计出发生5xx错误的请求数。当我们查看查询结果时,假设发现500是发生数量最多错误代码,接下来我们可以使用第二个查询过滤错误代码,以确定返回500错误数量最高的URI。
根据上述统计分析,我们可以识别出现最多问题和跟它相关联的URI,然后我们就可以采取相应的措施来解决问题。 例如在分析过程中发现日志中存在以下错误代码之一都可能是问题:
-
-
- 当源站无法访问或超时未响应时,CloudFront会返回504网关超时错误。 我们可以检查这些错误的时间戳,并将它们与源站的日志进行比较。 如果我们需要更多帮助,可以使用AWS控制台上的 Support菜单来开故障工单,并提供从Cloudfront分配日志文件中获取的相关的请求ID( x-edge-request-id )。
- 您的源站返回500,501或503内部错误,这些响应会缓存在CloudFront上。我们通过查询Athena日志文件可以过滤出导致故障的服务器端URI,然后进一步分析和调试这个URI对应的应用程序代码。
- 在源站上由于错误的TLS配置,导致客户端访问出现502 Bad Gateway错误 。日志中出现这种信息时我们可以根据这个信息检查源站上的TLS证书和配置 。
-
有关不同HTTP错误以及如何防止它们发生的详细帮助信息,请参阅CloudFront文档 。
2. 4 调试Lambda @ Edge函数
如果我们在3.2节的查询分析过程中,从 Error rate图表中看到是Lambda @ Edge出现HTTP 5XX错误峰值,则下一步我们需要了解导致错误出现的原因。 例如出现HTTP 5XX的错误峰值可能是由Lambda函数代码中的异常引起的,也可能是函数返回了对CloudFront的无效响应,或者函数可能已被限流(throttled)。 要了解有关Lambda @ Edge错误类型的更多信息,请参阅测试和调试Lambda @ Edge函数 。
为了发现在特定情况下导致错误峰值的原因,我们可以深入分析Cloudfront控制台上的监控图表。 首先选择监控仪表板中的Lambda @ Edge Errors选项卡,我们可以看到如下内容:



根据日志和监控图标中出现的错误类型,我们可以根据以下决策图中的步骤来调试Lambda @ Edge函数。 下文介绍了调试不同错误类型的详细步骤。

a. 执行错误
执行错误是使用Lambda @ Edge时最常见的错误。因为Lambda @ Edge函数中存在未处理的异常或代码中存在错误导致CloudFront没有从Lambda @ Edge获得响应时会发生执行错误这种情况。要解决此问题,我们需要通过分析CloudWatch中的Lambda @ Edge日志来调试代码。 如果Lambda @ Edge函数未正确执行 ,它会尝试将错误对象转换为具有以下格式的字符串,并将该字符串发送到CloudWatch日志文件。
要在查看执行错误,请在控制台的Monitoring Dashboard中选择正在分析的Lambda @ Edge函数,然后选择View logs ,我们将被重定向到CloudWatch控制台,在这里可以查看与Lambda函数关联的日志组的详细信息。

要在CloudWatch中更快地分析日志,我们可以使用CloudWatch Logs Insights工具。 Insights能够以交互方式搜索和分析日志数据。 我们可以运行查询以便快速了解操作问题和解决它们。 例如我们可以通过Insights中的以下查询过滤错误消息,仅查看与特定错误相关的消息。

我们还可以使用Insights查询代码用Console.log()接口输出的日志文件。 例如一个Lambda @ Edge函数,该函数用于单页面应用程序的A / B测试。 在代码中我们可以通过执行以下操作来记录在每个Lambda @ Edge执行中选择的页面版本:
然后我们可以在Insights中使用以下查询来过滤INFO消息,提取所选页面版本并计算每次出现的次数:
fields @timestamp, ddbRegion
| filter @message like /INFO/
| sort @timestamp desc
| stats count() by ddbRegion
b. CloudFront验证错误
有时Lambda函数会向CloudFront返回无效的响应。 例如如果响应的对象结构不符合Lambda @ Edge事件结构 ,或者响应包含无效标头或其他无效字段,就会返回验证错误。 请注意在Lambda控制台中测试Lambda函数时,CloudFront不会验证您的Lambda函数,这意味着Lambda函数可以在控制台中正确运行,但在将其添加到分配并在CloudFront中部署时仍然可能会失败。
CloudFront将验证日志发送到用户附近的AWS区域中的CloudWatch日志。 在“监控仪表板”中,选择要查看日志的区域,然后选择“查看日志”,将被重定向到CloudWatch控制台以查看与Lambda函数关联的日志组。

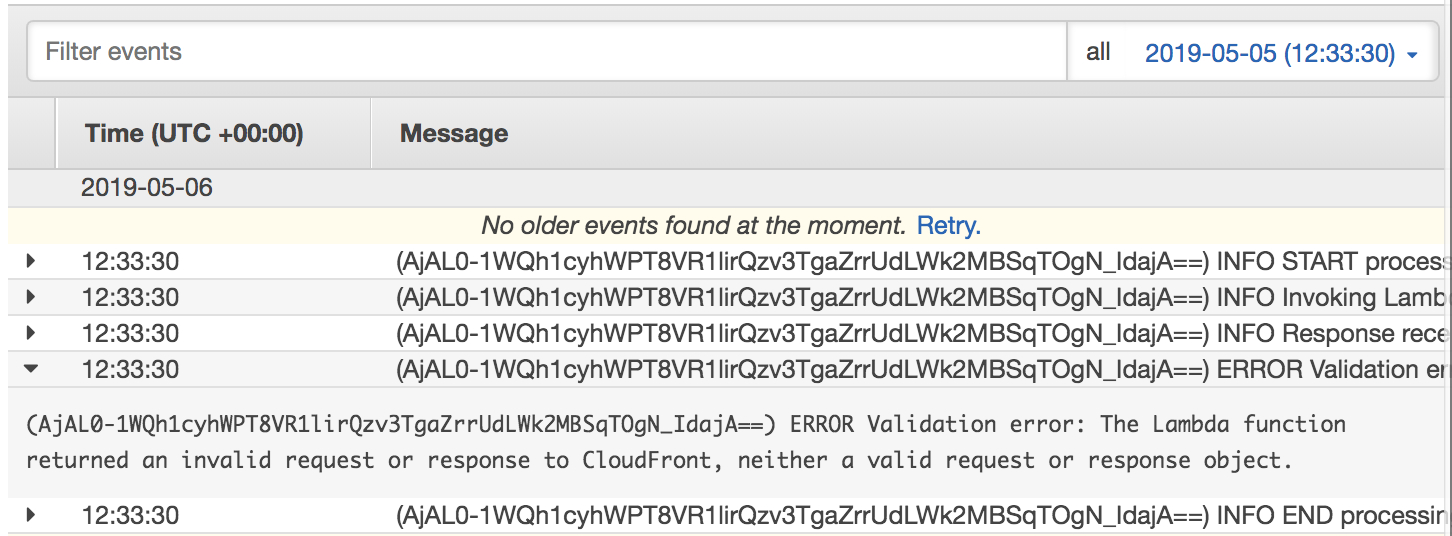
在日志中,您可以看到CloudFront验证错误的原因,如下图所示:
c. 限流
并发性是指特定AWS区域中Lambda @ Edge同时执行的数量。如果达到区域并发限制 ,Lambda @ Edge服务会按每个区域的限制限制Lambda函数调用。要更好地了解达到并发限制的位置和原因,请在“监控仪表板”上选择“Lambda @ Edge”功能,然后选择“ View function metrics” 。

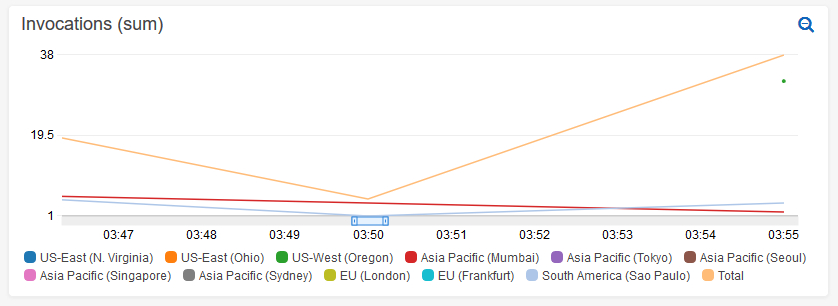
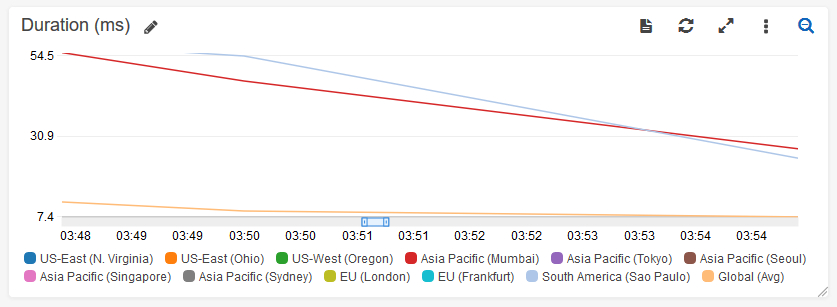
然后检查Invocations和Duration仪表板,它按区域显示按区域调用函数的频率,以及函数执行的时间:
在三种情况下可能会导致Lambda函数的并发运行受到限制:
a. 第一种会受到限制情况发生当请求数量很高导致频繁地调用函数时。如果发生这种情况,我们可以向AWS支持部门申请提升Lambda函数受到限制的区域中的并发执行的限制。 另外一个选项是考虑重新调整应用程序架构以减少并发调用Lambda @ Edge的数量,例如在Lambda @ Edge触发器设置中指定更具体的CloudFront行为。
b. 第二种受到限制情况是当Lambda函数代码执行时间较长时。 要解决此问题可以考虑检查Lambda函数是否有依赖的外部组件在运行时没有响应。 如果是这样的话可以在Lambda函数代码中设置超时。
c. 第三种受到限制情况发生当应用程序在极短时间内(秒级)接收到突然的流量高峰时。 在这种情况下,Lambda @ Edge需要为Lambda函数的运行启动新的运行时(runtime),这会给Lambda函数的执行持续时间增加额外的延迟开销。 此延迟开销会更快地消耗可用的执行并发级别。 减少此开销的方法之一是压缩Lambda函数部署包的大小。
要了解有关优化并发性的更多信息,请阅读关于Lambda @ Edge设计最佳实践的博客文章。