亚马逊AWS官方博客
亚马逊云科技 WAF 部署小指南(一)WAF 原理、默认部署及日志存储
什么是亚马逊云科技 WAF?
亚马逊云科技 WAF 是一个网页应用的防火墙服务。它能帮助保护您的网页应用或网页 API 应对常见的网页攻击。这些攻击会影响应用的可用性,产生安全风险,或消耗过量的计算资源。
使用 WAF 是对网页应用增加深度防御的好办法。WAF 可以帮助应对类似 SQL 注入、CSS 和其他常见的漏洞攻击。WAF 允许您创建自己的定制规则在 HTTP 请求到达应用之前决定是阻断还是允许该请求。
使用 curl 来创建和发送 HTTP 请求。这些请求是用来测试 WAF 规则的。curl 在Windows Subsystem for Linux(简称 WSL)上可以使用。
如果你不确定,建议您使用亚马逊 Cloud9 环境来完成这个实验。Cloud9 环境包含所有所需工具。Cloud9 的默认设置就可以满足本次实验的要求。
内容简介
本文分为五个步骤为您讲述如何创建带有 WAF 的网站环境,并把 WAF 的检查日志记录下来的最小架构。
步骤一:创建 WAF 的 Web ACL。
步骤二:创建一个测试用的 Web 服务器和 ALB 以测试 WAF 的防护效果。
步骤三:把我们创建的 Web ACL 与步骤二创建的 ALB 关联起来,以使 WAF 防护功生效。
步骤四:对 WAF 规则做一些常用的配置调整。
步骤五:启用 WAF 日志,把日志记录进 S3 存储桶,并用 Athena 进行查询。
架构图:

步骤一:创建 Web ACL
一个 Web ACL(Web Access Control List)是亚马逊云科技 WAF 的核心资源。他包含评估每个收到请求的原则(rules)。一个 Web ACL 使用 CloudFront 发布点、API 网关或者应用负载均衡器关联你的网页应用程序。
这个实验使用 WAF v2,请确认你没有使用经典 WAF(WAF Classic)。
托管规则
最快的方法来开始使用 WAF 是在 WebACL 里部署托管规则组(Managed Rule Group for WAF)。
托管规则组是一组 WAF 规则,由亚马逊云科技或者亚马逊市场里的第三方厂商创建和维护。这些规则提供了对常见攻击的保护。或者针对特定应用类型的攻击。每一个托管的规则组防御一类常见的攻击,如 SQL 或者命令行攻击。
亚马逊云科技提供了一系列可供选择的规则组,例如 Amazon IP Reputation list,Known Bad Inputs 和 Core rule set,还有其他规则组可供使用。
下图在 Web ACL 里加入了亚马逊云科技的托管规则里的 Core rule set(包含 OWASP 和常见 CVE 防御的托管规则)以及防范 SQL injection 的托管规则。

现在让我们来创建我们的第一个 Web ACL-Sample-web-acl。
在配置开始前,我们需要了解亚马逊云科技的 WAF Web ACL 可以部署在两个位置,分别是 Global 和各个 region。如下图所示:

Global 的 Web ACL 会被部署到亚马逊云科技全球 400 多个 PoP 节点,使用一致的 WAF 防护策略与 CloudFront 结合来保护用户的源站。
Region 的 Web ACL 在每个 Region 配置不同的 Web ACL,用于保护同 Region 里的 Web 服务器。* 如果您的 Web ACL 配置完以后找不到,很可能就是因为查看的不是当时创建 Web ACL 的 Region。
现在我们点击 Create Web ACL 来创建我们的第一个 Web ACL:

在这里填写红框里的内容,注意 Description 如果不填写以后不能修改。在 Resource type 这里,选择 CloudFront distribution,创建的是 Global Web ACL。如果选择 Regional resource,创建的就是 Region Web ACL。
这里,如图所示,我们选择在 US East Region 创建一个Regional Web ACL。
点击Next。
添加相关的规则,这里我们选择 Web 防护必用的四个托管规则:
分别是:
- Amazon IP reputation list(来自亚马逊云科技安全情报的已知恶意 IP 列表)
- Core rule set(包含跨站脚本攻击等 OWASP 攻击防护的策略)
- Known bad inputs(包含已知的漏洞发现和利用防护-其中包含 Log4j 漏洞的相关防护)
- SQL database(包含 SQL 注入攻击防护)
*注意:此处从 2023 年 4 月起 WAF 的 WCU 已经从 1500 WCU 提升到 5000 WCU。能够容纳更多的托管和定制化 WAF 规则。中国区的 WAF 也完成了该项提升。从下图的界面大家就可以看到这个变化。


加好以后点击 Next 结果如下:

再点击 Next 可以设置各条规则的优先级。
这里我们建议把比较复杂的检查条件优先级安排在低优先位置,让恶意请求先经过简单条件的检查。比如 Reputation List 的检查只检查 IP 地址信息,就把它放在最先检查的位置。

点击 Next 设置 CloudWatch metrics,这里保持默认即可:

然后检查之前配置的内容点击“Create web ACL”。

几乎不用等待,您就可以得到一个名为“Sample-web-acl”,位于 US East Region 的 Web ACL。
步骤二:创建一个测试用的 Web 服务器和 ALB 以测试服务效果
直接用 WAF 保护生产环境里的 Web 服务器需要特别注意出现误杀的情况。因此这里我们先创建一个简单的测试用网页服务器。这里我们选用了一个 echo-server 的 Docker 镜像,创建一个 httpecho 的容器让它能够把我们通过 http 访问服务器的请求头都提取出来作为 http 响应给我们的浏览器。
首先启用一个 t2.micro 的 EC2,使用 Amazon Linux2 AMI 启动。
在此 EC2 上安装 Docker,参考 https://docs.aws.amazon.com/zh_cn/AmazonECS/latest/developerguide/docker-basics.html。
具体 Linux 命令如下:
1. 安装 docker
2. 赋予 ec2-user 用户 docker 启动的 linux 权限
3. 退出当前 ssh session 以使权限生效
4. 使用 ec2-user 再次 login 检查 docker 信息
输出如下即为 docker 安装成功:
5. 运行 echo-server docker image,监听 TCP 1028 端口
6. curl检查本地服务
输出如下即表示服务正常。该输出表示 echo-server 服务器收到 curl 送来的 http 请求,内容非常简单:
7. 在 US East Region 建立 ALB
监听 TCP 80 端口,后端转发至 EC2 的 TCP 1028 端口。
ALB 配置完成后如下图:

ALB Target Group 状态如图:

使用浏览器访问 http://httpechoalb-123456789.us-east-1.elb.amazonaws.com。
得到如下结果,即表示 ALB 与 EC2 的工作正常。可以看到通过浏览器访问网页,我们的 User-Agent 字段内容是很长的。

步骤三:把我们创建的 Web ACL – Sample-web-acl 与步骤二创建的 ALB 关联起来
1. 点击 Web ACL 里的 Associated resources:

2. 选择关联 Application Load Balance,关联步骤二创建的 httpechoalb。

3. 关联完成。如果需要,在配置好证书的情况下,httpechoalb 还可以完成 https 解密,然后由 WAF 进行网页请求的内容检查。

4. 使用一个 curl 命令模拟 SQL injection 测试,此处我们把 User-Agent 字段模拟成和浏览器一样,以绕过其他 WAF 检查条目:
输出如下,即表示 WAF 发现了恶意内容。予以阻断并回应 http 403。
步骤四:对 Web ACL 做一些常用的调整
1. 在 WAF 规则列表前部增加限速规则
在 WAF 防护的时候,我们会建议在 WAF 规则列表前部增加限速规则。具体配置如下:
这里我们根据每个客户端访问的源 IP 进行限速,每个公网源 IP 访问的次数限定在每 5 分钟 1000 次以下。超过这个频率的请求将被过滤。具体大家可以根据自己应用的请求频率再做调整。有了这个限速规则,当外部使用 HTTP 泛洪进行攻击的时候,我们可以先把限速规则的访问速率降下来,先限制住请求数量最多的个别源 IP,来恢复大多数正常用户的访问。

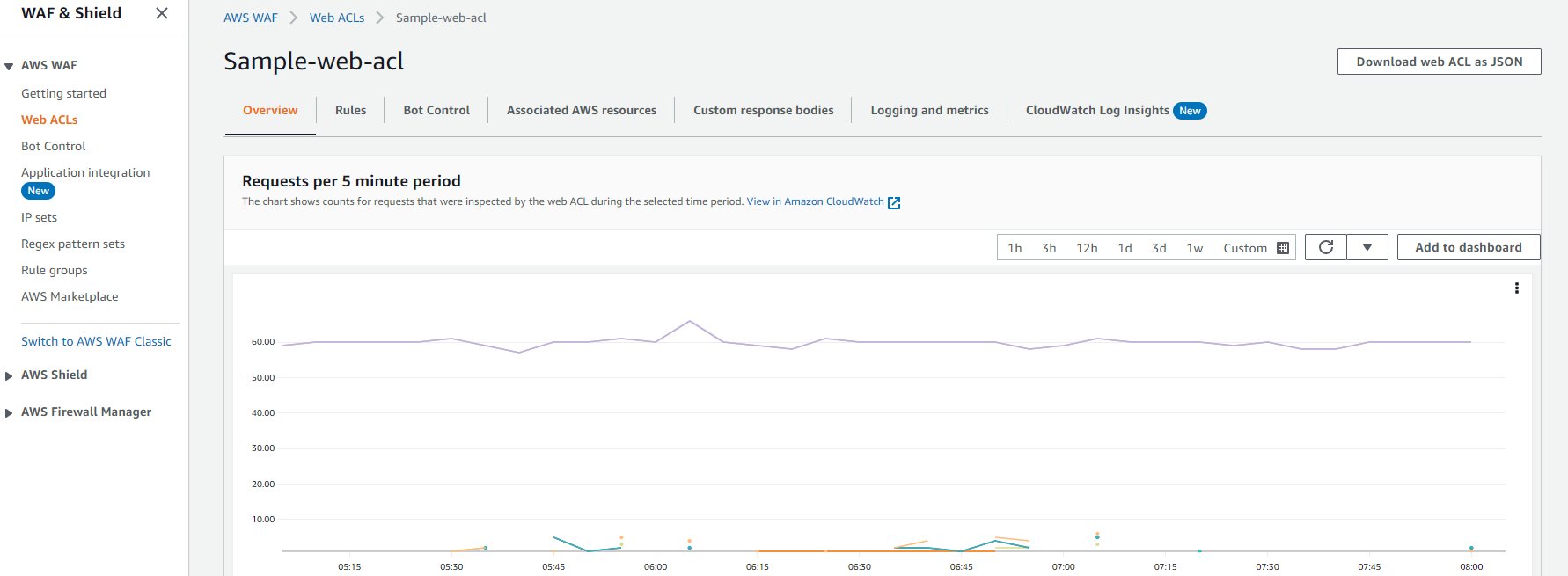
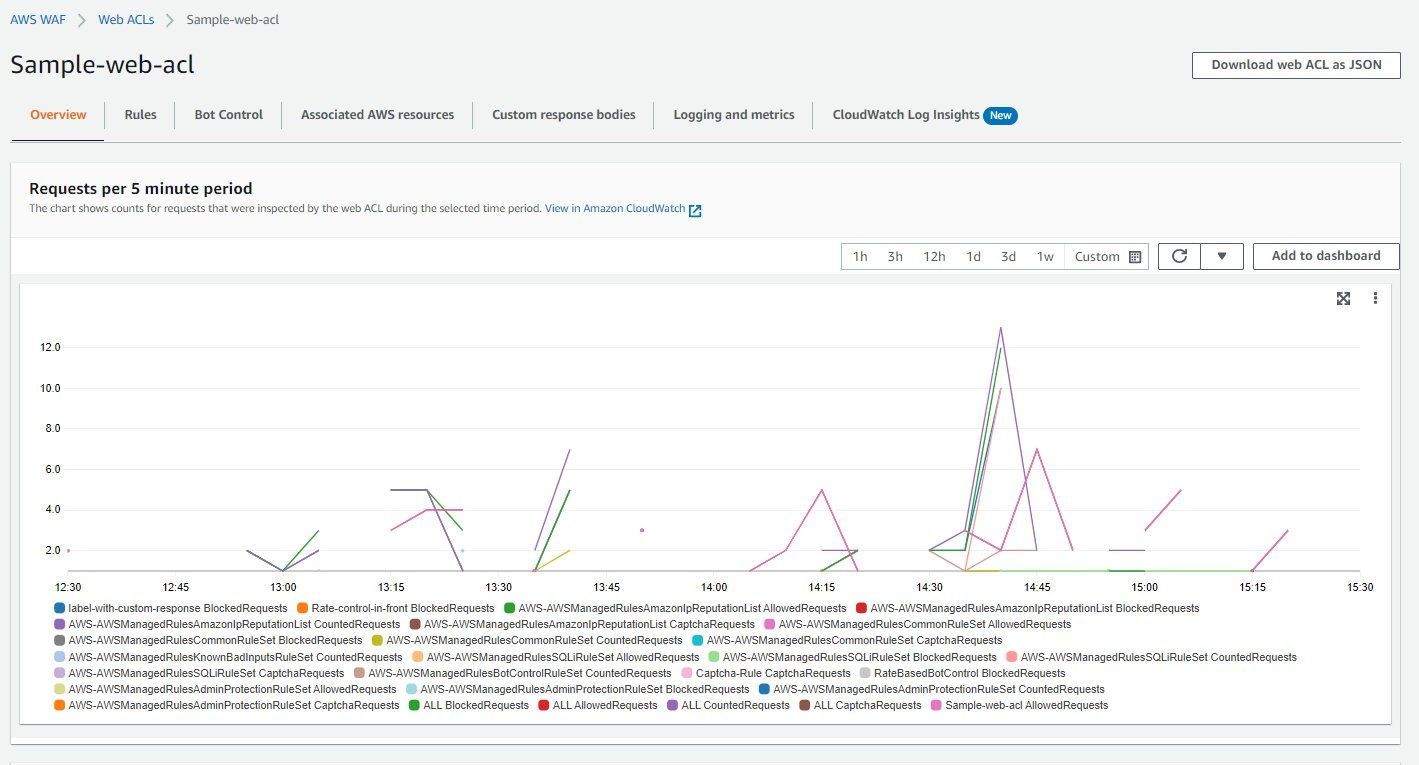
如果需要了解网站的日常访问速率帮助确定合适的限速速率,可以把 WAF 设置成 Count 或者 Group Override 模式挂载到 ALB 或者 CloudFront 上。然后就可以在 WAF Overview 的面板上看到网站的峰值请求速率,如下图。
*注意:下图的请求数据是以每 5 分钟的请求总量来显示的。如果需要了解每秒请求量需要除以 300。如下图 60.00 读数的请求量对应的是 0.2 次的每秒请求量。
2. 注意一些容易产生误杀的字段
例如:Core rule set 里的 SizeRestrictions_BODY 和 NoUserAgent_HEADER 子规则,经常会导致一些较大的上传请求体或者生产用自动脚本的请求被过滤。
此时可以根据业务情况把该条子规则设置为 Count 模式。

3. 设置检查白名单
对于需要设置白名单的请求,有两种方法应对不用的场景。
场景一:对于需要绕过所有后续 WAF 检查的白名单请求。可以把匹配条件规则的 Action 设置为 Allow。就可以绕过后续所有 WAF Rule 的检查。
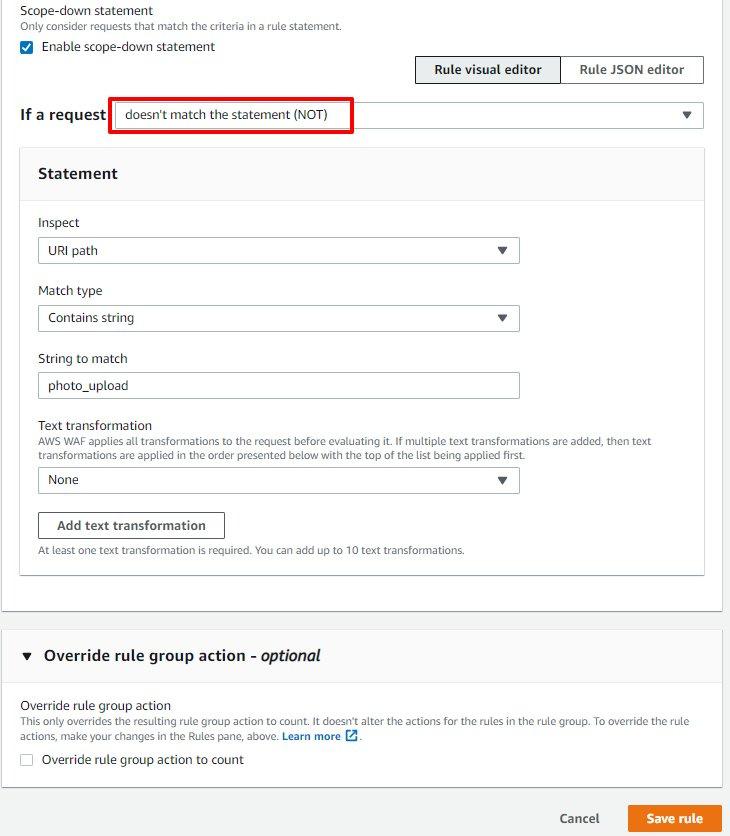
场景二:对于托管规则里误杀的请求,可以使用 Scope Down(缩小检查范围)设置来让请求不匹配检查范围从而绕过检查。
具体设置如下:
注意 Scope Down 设置是当请求匹配过滤条件的时候必须进行检查。因此我们想让 photo_upload 这个 uri path 绕过检查的时候,选择的过滤条件是不匹配该条件(NOT)。从而达到不包含 photo_upload uri path 的请求需要检查。反之则不检查。
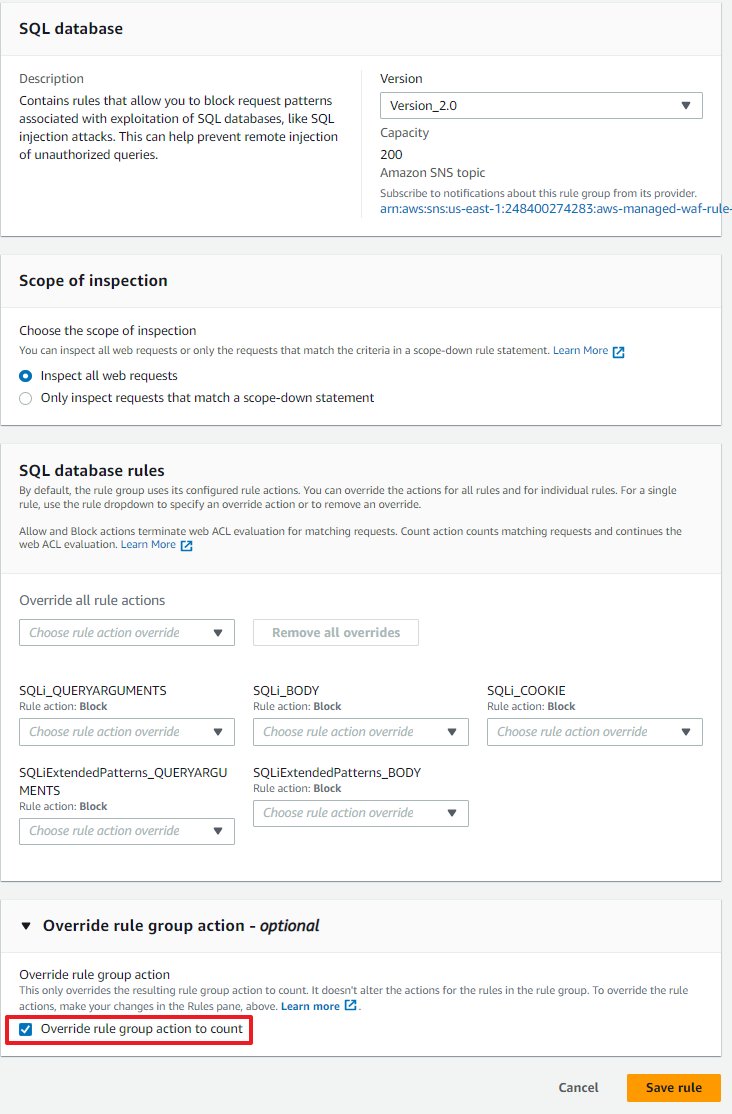
4. 正确设定 Count 或 Group Override 模式
在 WAF 规则在生产网正式启用之前,往往需要将 WAF Rule 设置成观察模式来判定是否有正常请求被误杀。这个过程中,设置 WAF 规则为 Group Override 模式能够保证匹配的请求被打上匹配规则的标签。所以,在防误杀判定过程中,我们更推荐使用 Group Override 模式来让 WAF 工作在观察模式下搜集日志。Group Override 模式对匹配规则的请求所做的操作和阻断模式唯一的差别在于最后的允许和阻断,在打匹配标签的行为上和阻断模式完全一样。是比 Count 模式更好的阻断规则启用前的模拟。
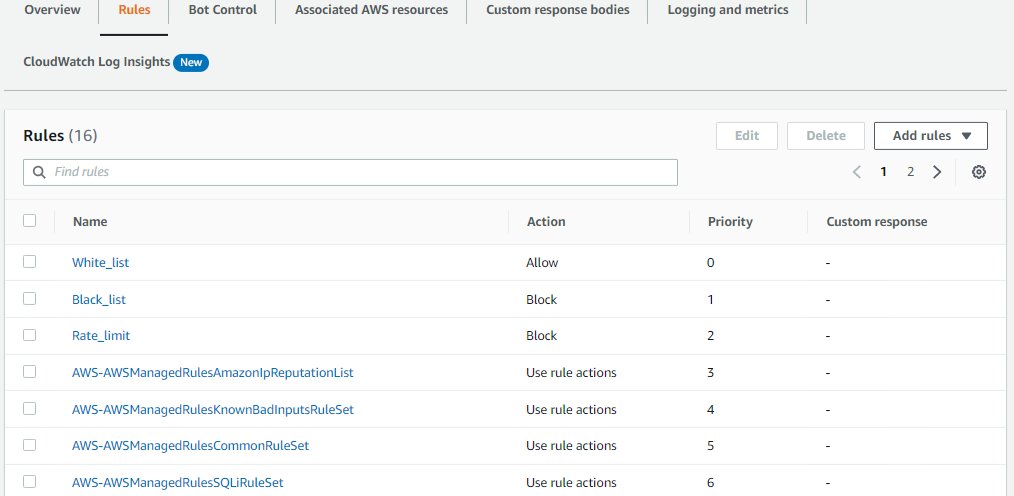
5. 安排好规则顺序
掌握了以上技巧,我们把 WAF 的各项规则排序如下。做 IP 地址过滤类的规则由于处理速度快,放在规则组的前部。White_list 和 Black_list 分别是黑名单和白名单,放在最前部以保证规则的绝对有效性。Rate_limit 是限速规则,平时放一个较宽的速率,当有攻击发生时可以迅速压低每 IP 的请求速率。
托管规则类的规则放在后部。
*注意:修改 WAF rule 的规则顺序没有直接的按钮,可以点击任意 WAF rule 进入编辑状态,然后不做修改就进行保存。之后就可以看到安排 WAF rule 先后顺序的选项了。
步骤五:启用日志
经过以上五个步骤,我们的 WAF 已经可以开始防护网页应用,打开 WAF Overview 的面板,我们可以看到一些经过 WAF 检查的 Web 请求。不过这里的请求,是帮助操作人员了解 WAF 的大致工作情况的。
WAF Overview 里的数据是经过采样的。选择采样的请求来检查请求信息,里面并没有阻断请求的规则匹配细节。这对于我们日常的排查误杀的工作仍然不够用。
WAF Overview 面板:
采样请求可以根据不同的 WAF rule 进行过滤:

采样请求内容并不包含 WAF 匹配规则:

由于 WAF Overview 里的数据是经过采样的,并且历史的访问记录并不归档。因此如果我们需要使用 WAF 完成安全合规的任务,或者做误杀排查工作,就必须要启用 WAF 日志功能。
WAF 日志搜集和处理有多种选择。我们这里先介绍操作最简易的 S3 日志存储方式。这种方法适用于仅把 WAF 日志作为访问记录存储,日常不会经常查询和做安全事件调查的组织。
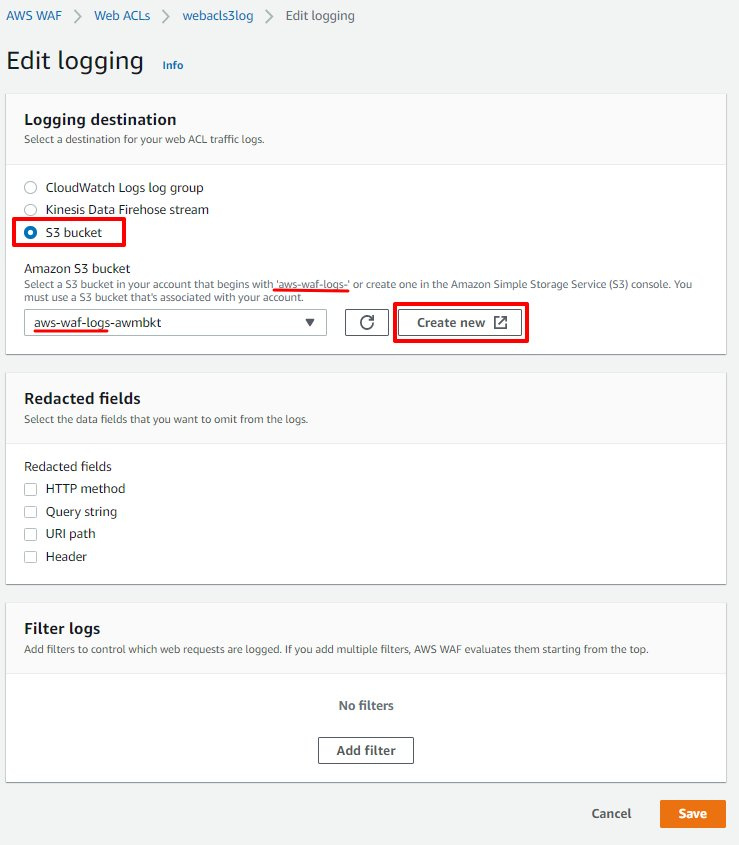
1. 启用 WAF 日志:

在日志记录选择方面,我们选择直接把日志放入 S3 bucket。
然后我们需要创建一个 S3 桶,注意桶名必须以 aws-waf-logs-开始。否则我们在下拉框里就看不到这个新建的桶。
完成后点击 Next,WAF 日志就会随后送到这个指定的桶了。
要查看 WAF 日志,我们可以去 S3 桶查看。如下图所示,可以看到 WAF 日志根据每个 Web ACL 的名字分别做了子目录。因此多个 Web ACL 可以放在同一个 S3 桶里,并不会冲突。
新的日志被记录 S3 桶通常需要 5 分钟左右的时间。
*日志直接记录入 S3 桶的方法操作最简单。但是日志的时延稍高,并且有 CloudWatch 的日志格式转换费用。所以在日志量在 100TBytes/月以下的场景用户大多会使用 Kenisis Firehose 来输出日志。需要增加一点配置,但是时延能够做到 1 分钟的水平。具体操作可以参考 WAF 部署小指南三的步骤四。

想要查询 S3 桶里的日志。我们可以使用 Athena 来直接对 S3 桶的数据进行查询。
首先,使用下面的 Athena 命令创建一个 WAF 日志表:
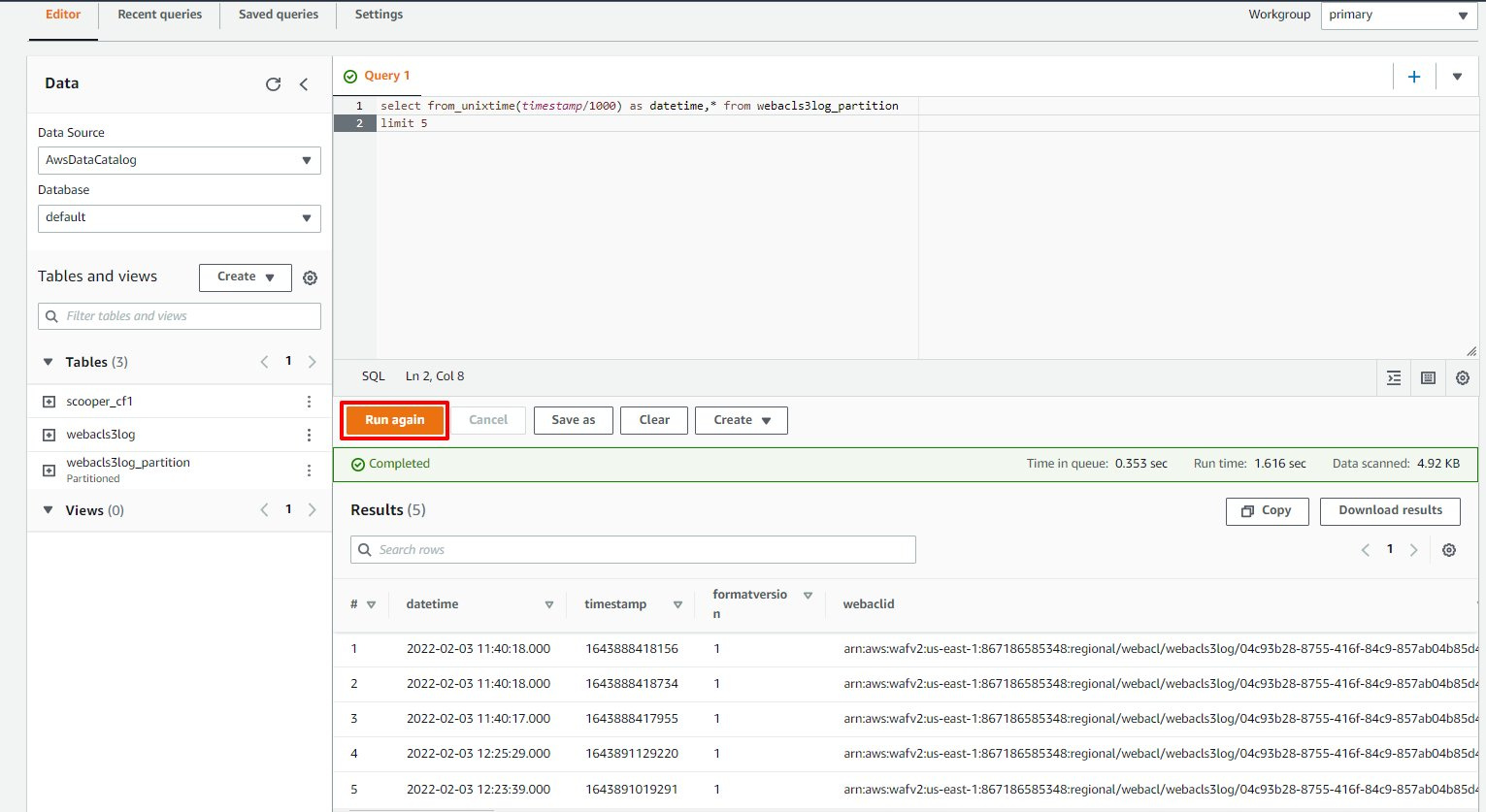
然后就可以使用 SQL 语句来进行日志查询了。这里我们举两个例子:
搜索前 5 条 WAF 日志,列出日志里所有字段
输出结果:
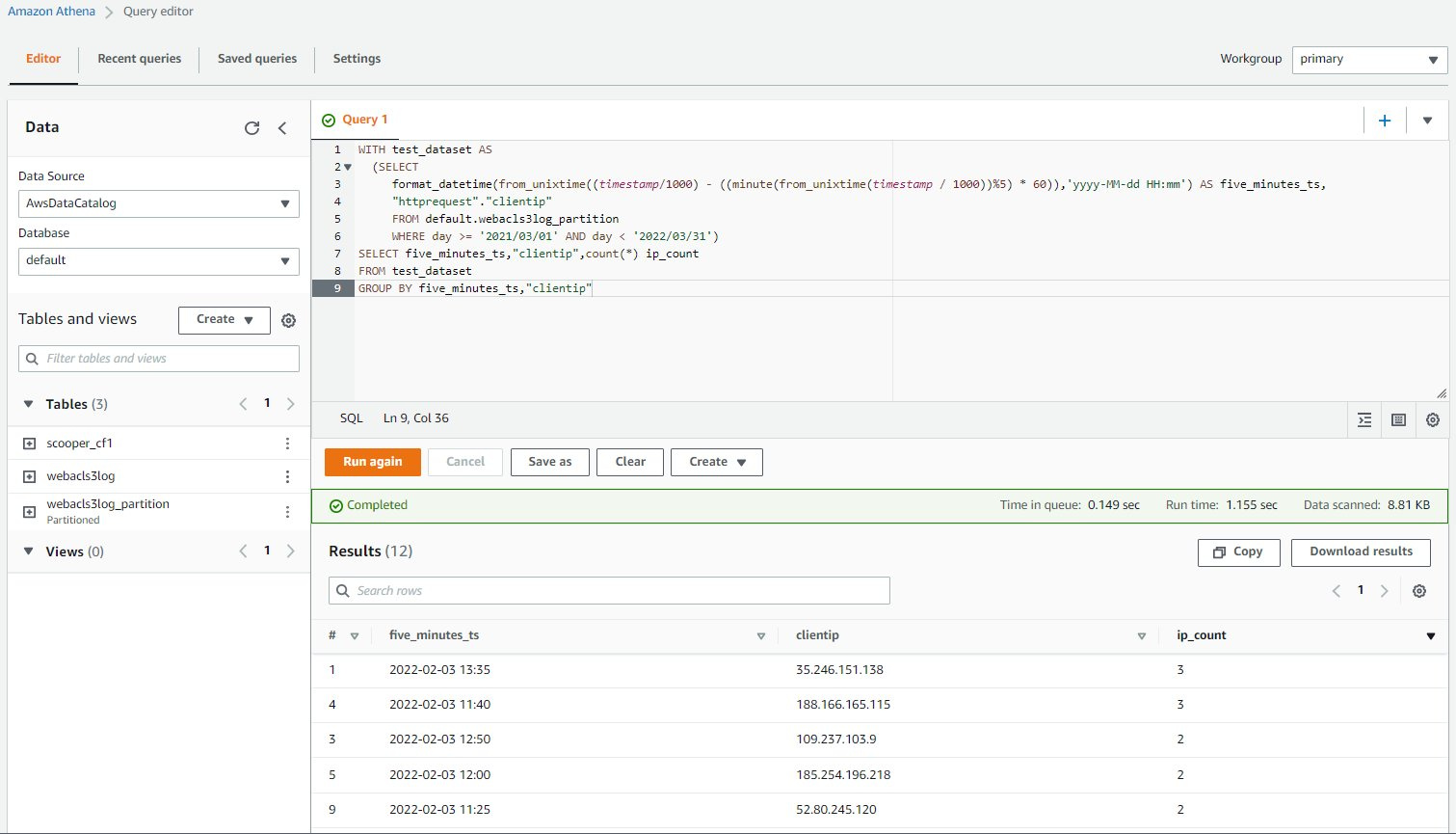
搜索特定时间范围的日志并按照 clientip 做汇总:
关于 WAF 直接使用 S3 存储日志并使用 Athena 做查询的更多介绍可以在这里找到:https://docs.aws.amazon.com/zh_cn/athena/latest/ug/waf-logs.html#query-examples-waf-logs。
小结
通过以上五个步骤,我们完成了亚马逊云科技 WAF 的启用和配置的工作。并且把 WAF 日志存储在 S3 桶,使用 Athena 进行历史日志的查询。可以满足基本的归档查询需要。本文介绍的 WAF 防护的 Web ACL 和 Rule 可以作为一个生产环境的 WAF 防护策略。达到 OWASP 和 SQL 注入等攻击防护的要求。此外,本方案通过使用 S3 存储桶记录 WAF 日志,保证用户可以存储合乎行业和法规要求时间长度的日志。并可以通过 Athena 进行类 SQL 语言的查询来回溯日志。对于 WAF 运营有更高要求的用户,可以参考 WAF 部署小指南的后续文章,选择更适合您的方案。