亚马逊AWS官方博客
通过 Amazon Athena 进行无服务器架构的大数据分析
互联网时代带来了数据量的海量增长,数据驱动业务决策成为大势所趋。分析人员迫切的希望能快速的交互式的从海量的数据中抓取有用的信息来辅助决策。在AWS上,Amazon S3对象存储服务由于其高可用性,高持久性,可扩展性和数据格式兼容性等特点成为建设存储海量数据的数据湖的首选。Amazon Athena可以轻松对Amazon S3中的数据进行交互式查询,是一款开箱即用、无需运维的全托管服务。
Amazon Athena介绍
借助Amazon Athena,分析人员能够轻松使用标准 SQL 分析 Amazon S3 中的数据。Athena 采用无服务器架构,因此无需管理任何基础设施,且只需按需为运行的查询付费。
Athena 简单易用。只需指向您存储在 Amazon S3 中的数据路径,定义架构并使用标准 SQL就可以 开始查询。查询可以在数秒内获取结果,并且可以实时展示查询结果以迭代查询语句。使用 Athena,无需执行复杂的 ETL 作业来为数据分析做准备。这样一来,任何具备 SQL 技能的人员都可以轻松快速地分析大规模数据集。
Athena 可与 AWS Glue 数据目录进行开箱即用集成。AWS Glue让您能够跨各种服务创建统一的元数据存储库、抓取数据源以发现 schema 并使用新的和修改后的表与分区定义填充数据目录,以及维护 schema 版本控制。您还可以使用 Glue 完全托管的 ETL 功能来转换数据或将其转化为列格式,以优化成本并提高性能。
Amazon Athena工作原理
Amazon Athena是完全的无服务器架构,用户不需要管理底层的资源只需要按照扫过的数据量付费。
用户可以通过控制台界面或者API的方式提交查询,查询结果会默认保存到S3中并返回到控制台界面。当您在后台查询现有表时,Amazon Athena 会使用 Presto,一种分布式 SQL 查询引擎。
Amazon Athena的元数据存储在Glue数据目录里,如果当前区域没有Glue服务则元数据保存在Athena自带数据库中。
Athena通过workgroups来限制资源的访问,可以限制每条查询最大扫过的数据量或者每个workgroup最大可以扫过的数据量。每个workgroup有单独的监控指标并可设置单独的告警。
Amazon Athena典型应用场景
Amazon Athena可以对S3里的数据进行交互式查询,常见的使用案例包括:
- Adhoc查询 – 一次性查询大量数据,Athena支持 ANSI SQL做查询和分析,可以直接查询源中的数据而不需要加载数据到Athena。 Amazon Athena 可以处理非结构化、半结构化的和结构化的数据包括 CSV、JSON、Avro 或者列式存储 Apache Parquet 和Apache ORC。
- 报表和展示工具 – Amazon Athena 可以结合 Amazon QuickSight做数据展示。Athena可以用来生成报表并且支持用BI工具直接查询比如 Tableau 或者 SQL clients, 支持 ODBC 或者JDBC 连接。
- 数据产品 – 使用Athena SDK 和 CLI工具可以把Athena查询嵌入到应用程序里面作为数据产品提供。
Amazon Athena客户案例
Atlassian通过开发企业协同办公SaaS产品,助力提升公司员工的办公效率以期达到产出最大化,旗下产品包括JIRA、Confluence、HipChat等。

参考连接: https://aws.amazon.com/cn/solutions/case-studies/atlassian/?nc1=h_ls
Atlassian的企业数据湖架构中采用了多个AWS服务包括Amazon S3、Amazon Kinesis、AWS Glue和Amazon Athena,具体架构如下:
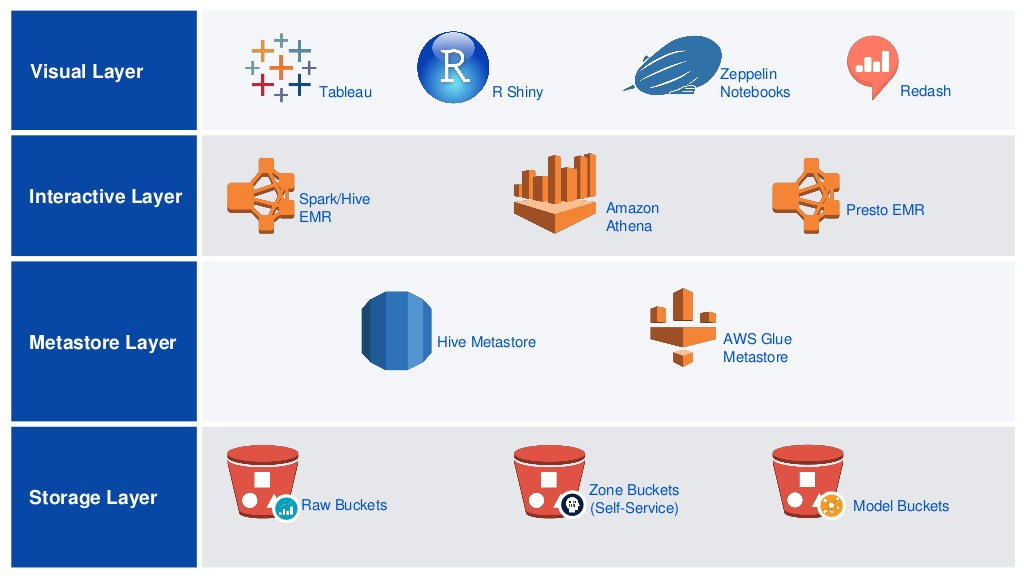
Athena被用作数据探索和展示工具的查询引擎,查询存储于S3中的处理好的数据。这套数据湖平台赋能给Atlassian的分析人员,让他们可以使用熟悉的展示工具或语言来更好的发掘数据中的价值。
Athena拥有全托管无需管理集群资源,只需要为运行的查询付费,并且可以追踪查询级别费用等优势。这些优势使得Atlassian决定把数据湖的查询引擎选型从Amazon EMR 的Presto集群迁移到Amazon Athena。
动手实践Amazon Athena
下面的动手的部分是基于东京区域的服务:
步骤 1:准备查询的数据
- 通过以下网址下载美国交通事故开放数据https://catalog.data.gov/dataset/traffic-collision-data-from-2010-to-present
- 打开Amazon S3控制台https://console.aws.amazon.com/s3/。
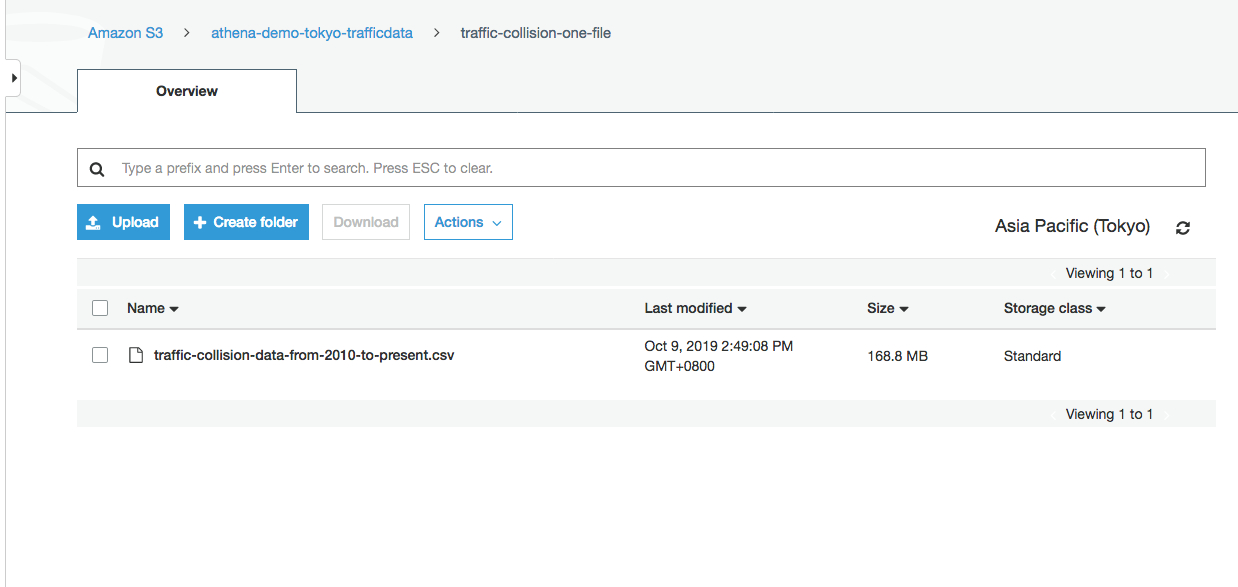
- 在东京区域创建一个S3存储桶取一个具有唯一性的名字例如athena-demo-tokyo-trafficdata-<当前日期>
- 在桶内创建一个文件夹traffic-collision-one-file并上传源数据

步骤 2:创建一张Athena表并查询
2.1使用DDL SQL语句创建您的 Amazon Athena表
(1)通过以下网址打开 Athena控制台:https://console.aws.amazon.com/athena/。(登陆的IAM user需要有AmazonAthenaFullAccess策略)

(2)通过在查询栏输入“create database demo;” 并且点击run query创建一个新database。

(3)Database在下拉栏里选择新建的demo,然后在查询栏里输入create table DDL创建一个新表。把S3存储桶换成步骤1中新建的S3路径。
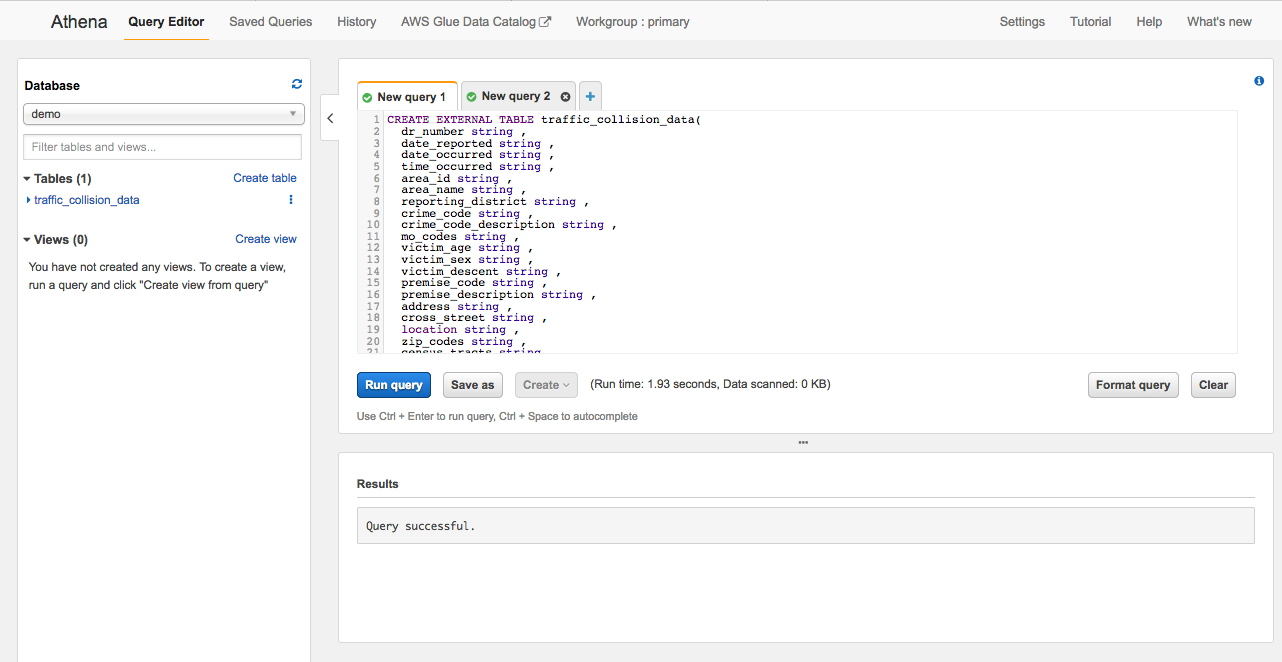
(4)在查询栏里输入“select * from traffic_collision_data limit 10”来观察数据含义。点击Save as 给查询命名,以便日后重复使用。

2.2建立逻辑视图来方便终端用户或展示工具查询
(1)统计每天发生的交通事故数量,在查询栏查询下列SQL

(2)点击Create,选择create view from query并取名为daily_accident_count_report。成功创建后查询栏会出现创建视图的DDL语句,日后也可通过DDL SQL语句创建。

(3)查询视图的内容 “select * from daily_accident_count_report”

2.3把数据从单一CSV文件转化为带分区的parquet格式
(1)在查询栏里键入一下create table with SQL语句。把external_location换成步骤1中的S3桶。此语句会创建一张新表和新S3地址,并且新S3地址会根据area_id做分区键,新数据会存为压缩的parquet格式可以极大的减小数据量。

(2)可以看到新建的表是一个具有分区的表,并且新的S3路径带有分区列信息。

步骤3:利用workgroups管理查询资源
1.切换到workgroup面板,点击create workgroup

2.创建一个新的workgroup。

3.点击切换workgroup。

4.点击view details可以更改workgroup设置,选择Data Usage Controls面板,添加每条查询扫过的数据量上限。

5.添加针对每个workgroup指定时间段扫过数据量的上限。
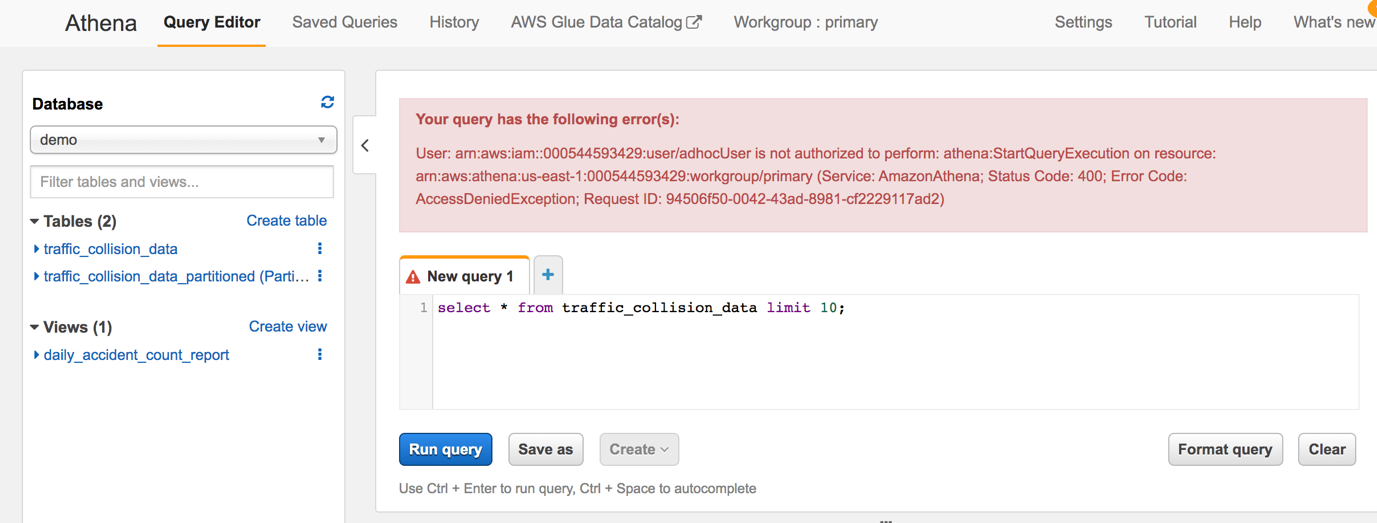
6.创建一个只有权限使用adhoc workgroup的IAM用户。用该用户登陆AWS控制台然后尝试切换成primary workgroup然后查询。可以看到查询报没有权限的错误。
把以下IAM策略赋予该用户,并把其中的<AWS账号>替换成自己的AWS账号(12位数字)
注:如果是使用宁夏和北京区域请把以下Resource部分所有的 “arn:aws:” 改成 “arn:aws-cn:”
扩展阅读:
Amazon Athena产品文档:https://docs.aws.amazon.com/zh_cn/athena/latest/ug/what-is.html
Amazon Athena Demo视频:https://aws.amazon.com/athena/getting-started/
本篇作者