亚马逊AWS官方博客
在 AWS 搭建无代码可视化的数据分析和建模平台
现代企业常常会有利用数据分析和机器学习帮助解决业务痛点的需求。如制造业中,利用设备采集上来的数据做预测性维护,质量控制;在零售业中,利用客户端端采集的数据做渠道转化率分析,个性化推荐等。
通常业务部门需要提需求给技术团队,技术团队将业务需求转换为技术需求,调动数据工程师,数据科学家,机器学习工程师等,做数据处理、分析以及建模,整个流程较长,需要比较高的跨团队沟通成本,且对企业人才储备技能有要求。 客户业务部门普遍期望降低使用机器学习解决业务问题的门槛和学习成本,使得业务分析人员可以较少借助数据科学家和数据工程师,快速解决特定领域的业务数据洞察。
本文以汽车行业的故障分析为例,演示如何在亚马逊云科技上构建一套无代码数据分析平台,业务人员不需要有编程能力、 SQL 或任何机器学习的先验知识,即可自行根据业务场景和具体需求,自助式的上传导入数据做出分析,从而帮助业务人员以最短的时间,最方便的使用数据。
场景和痛点
车辆的异常故障率通常受多个因素影响,比如生产批次问题,使用年限,经销商维保等。
在过去,质保部门被动的接受零散客户的问题上报和维修请求,当某车型或某批次的问题积攒到一定程度乃至爆发后,才能定位这部分车辆的问题统一进行召回。突然的故障爆发使得相关部门没办法提前预算出维修经费,没法提前准备备件,没法提前做管控措施,也影响车主的体验。
因此,对车辆质保数据做数据分析,对故障发生情况做基于时序的分析或者聚类分析,并根据现有数据对故障趋势进行预测,可以帮助业务部门实现质量预警,质量改善的目标,有助于企业和部门提前做预算,提前采取相应措施降低整体维修费用。
技术目标
基于实销车辆数据,以及车辆维修数据 ( 两个 Schema 如下表所示),基于车型,绘制出可以描述故障发生情况的曲线, 对曲线进行分类,归纳出相似的故障曲线,筛选出异常的故障曲线,以达到对异常故障进行预测,提前预警的目的。
- 车型故障曲线 :如根据时间、行驶里程数、车龄等维度的车辆故障数增长曲线。 本文以车龄这个维度为示例,其他条件类似,只是聚合条件发生变化。
- 归纳相似形状,筛选异常故障曲线
- 根据现有数据预测趋势
Sampling Schema
- Repair data
| Index | Column Name | Data Type | Note | Example |
| 1 | claim-no | string | 维修唯一识别号 | CLNO_2019306 |
| 2 | repair | string | 维修日期 | 2018-12-03 00:00:00.0 |
| 3 | regidate | string | 销售时间 | 2017-08-14 00:00:00.0 |
| 4 | regidate_quarter | bigint | 销售季度 | 3 |
| 5 | regidate_year | bigint | 销售年份 | 2017 |
| 6 | caragemonth | double | 车龄(月) | 15 |
| 7 | carageday | double | 车龄(天) | 476 |
| 8 | vin | string | 车架号 | VIN706842 |
| 9 | engineseries | string | 引擎系列 | ENGINESERIES1 |
| 10 | series | string | 车系 | SERIES9 |
| 11 | model | string | 模型系列 | MODEL110 |
| 12 | seriesmodel | string | 具体车型 (模型系列+ 车系) | SERIES9-MODEL110 |
| 13 | prodd | string | 出厂日期 | 2017-03-31 00:00:00.0 |
| 14 | mileage | bigint | 里程数 | 42226 |
| 15 | partner | string | 经销商 | PARTNER98 |
| 16 | defectcode_l3 | string | 故障代码(短版) | d3FySj |
| 17 | defectcode_l3_num | double | 故障代码数字映射(短板) | 23 |
| 18 | defectcode | string | 完整故障代码 | d3FySj6Y |
| 19 | defectcode_num | double | 完整故障代码数字映射 | 32 |
- Sales data
| Index | Column name | Data type | Note | Example |
| 1 | series | string | 系列名称 | SERIES0 |
| 2 | sales_quarter | string | 销售日期(年份+季度) | 2012Q1 |
| 3 | sales_num_nozero | bigint | 非零销售额 | 1 |
架构
- 选择 Glue Databrew 作为主要数据处理的工具。 AWS Glue Databrew 提供一个可视化的工具,可以帮助数据分析师和数据科学家对数据做数据清洗和转换,从而方便后续将数据应用到分析和机器学习的场景。Glue Databrew 提供多达 250 种预构建转换中的操作,都可通过 UI 自动执行,不需要任何代码。比如,筛选异常数据、将数据转换为标准格式以及纠正无效值等等。
- 利用 Glue 做数据格式(Schema)的爬取,通过 Athena 作为 connector,最终用 QuickSight 作为 BI 展示工具,做 dashboard 展示
- 利用 Databrew 处理后的数据作为模型输入,利用 Sagemaker Canvas 生成预测模型。Amazon SageMaker Canvas 通过为业务分析师提供可视化、点击式的界面来扩展对机器学习 (ML) 的访问,利用AutoML 技术,根据您的独特用例自动创建 ML 模型,而无需任何机器学习经验或编写任何代码。 同时SageMaker Canvas 与 Amazon SageMaker Studio 集成,使业务分析师可以更轻松地与数据科学家共享模型和数据集,以便他们验证和进一步优化 ML 模型。

前提条件
- Glue Databrew 在大多数区域已经支持(包括北京和宁夏区),可在控制台切换至目标区域。 SageMaker Canvas 目前在部分区域推出,具体 region 请参考此 FAQ 文档。本文使用 Ohio (us-east-2) 为例。
- 将样本数据先存储在目标区域的某个 S3 桶中。如您不了解如何上传,请参考此 S3 文档
方案步骤
1. Glue Databrew 进行数据转换
该章节完成如下功能
- 无效数据清理
- 转换车辆维修数据,以适配销售数据
- 车辆维修数据和销售数据的合并
- 按照车型和车龄聚合数据
- 计算故障率
详细步骤
1.打开 Databrew 控制台,点击左侧栏 “数据集 (Datasets)”, 点击 “连接新数据集 (Connect new dataset)” 以创建数据源
2.在为数据集命名 (如 “repair-data”) 并选择 S3 的存储位置,数据格式 csv,采用默认分隔符 “,” ,点击创建数据集。同理,创建命为 sales-data 的数据集,csv 格式,默认分隔符 “,” 创建数据集。

3.选中刚创建好的数据集 repair-data,选择 “使用此数据集创建项目 (create project with dataset)” , 输入项目名称和配方名称,选择现有的或者新创建一个 IAM Role,需确保此 IAM Role 有权连接到所选的数据。点击 创建项目。 等待 DataBrew 界面的加载。
4.第一步, 无效数据的清理。
(1)选择 CarAgeDay 这一列(代表按天计算的车龄),点击 filter,并选择仅保留大于 0 的数据(或者根据需求,自定义此值)。如图所属,编辑完 Greater than 0 的条件后,点击 add to recipe,此时会在右侧生成浏览,请点击 APPLY 以生效
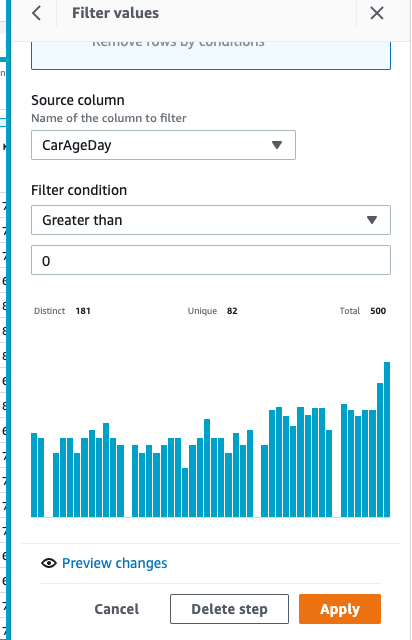
(2)将 mileage 进行 filter,只保留大于 0 的有效数据。同样点击 add to recipe 然后点击 apply 以生效。

5.第二步,将车辆维修数据的销售年份和销售季度合并为一个字段适配销售数据:点击右侧 recipe,add step,并选择 merge 操作 (Concatenate Columns),将 RegiDate_Year 和 RegiDate_Quarter 合并, 以 “Q” 作为连接符,target column name “year_quarter”


6.第三步,合并车辆维修数据和销售数据: 点击JOIN 操作,选择 sales-data 作为要 join 的数据集,选择 LEFT JOIN, 并将 year_quarter 以及 Sales_Quarter 作为 join key,浏览后点击finish

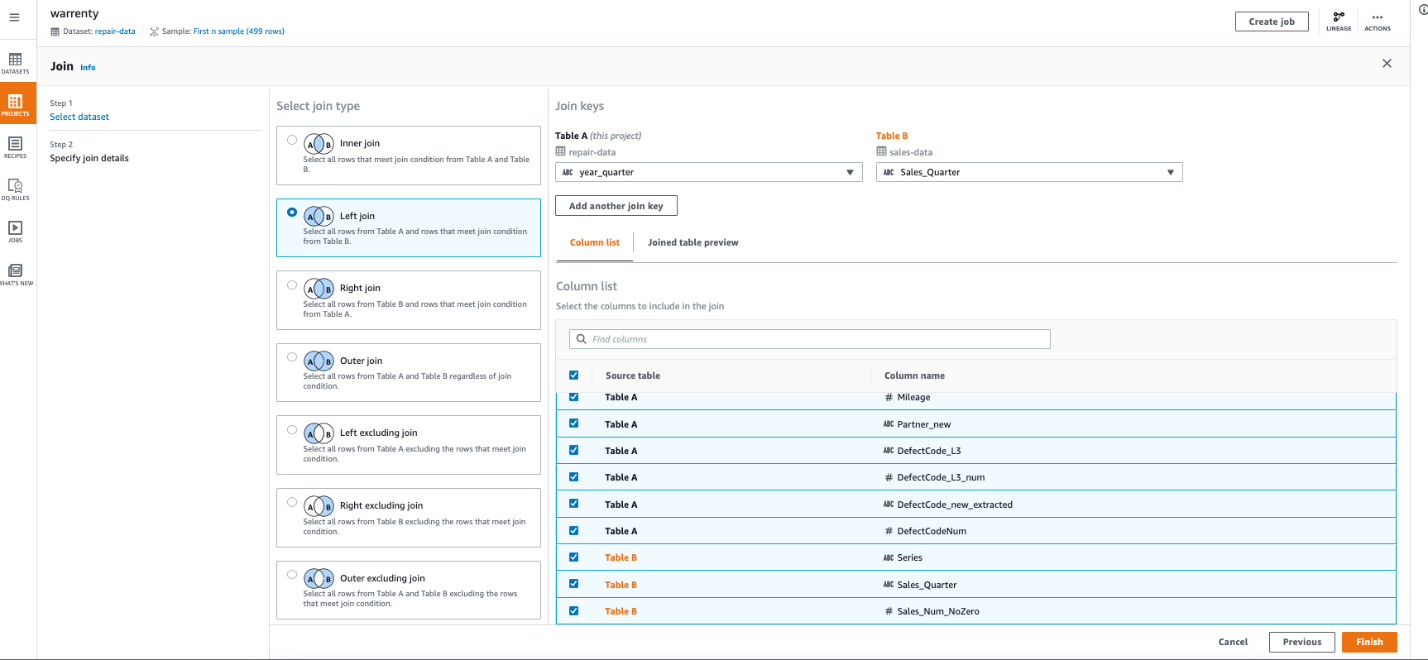
7.第四步,按照车型和车龄聚合数据: 如下图所示,按照 Series_new 和 CarAgeMonth 做聚合 Group by,生成故障数和销售数。

8.第五步,计算故障率
(1)为了做除法,先将 defect number 改为 INT 数据类型
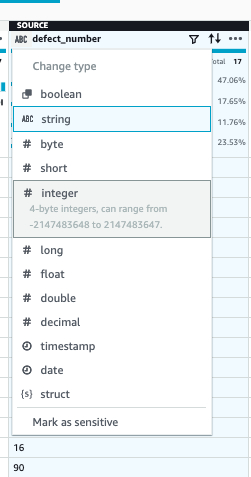

(2)为了计算故障率,我们选择DIVIDE方法,第一列选择 defect_number, 第二列选择 total_sales_number,目标列命名为 defect_rate

9.第五步,计算故障率:对 defect_rate 做过滤,去除小于0 的那些无效值

10.最终数据和配方如图所示, 基于每种车型做聚合,我们可以追踪出针对不同车龄的故障率。当然您也可以根据需求自行对数据做更多处理和转换。

11.点击右上方 Create job,以将此配方用于整个数据集。 定义job名称,文件输出地址(S3 location),选择 IAM role (此 Role 需要有 S3 对应位置的读写权限)后,点击最下方 create and run job, 大概会在 2min 完成数据的处理。

12.当 final 后,可以选择将 recipe publish 以保存配方。此配方在下一次可以直接用于应用于其他样本集。
2. 利用 QuickSight 进行数据展示
该章节完成如下功能
- Glue 爬取 Databrew 输出的 Schema,作为数据目录
- 利用 Athena 作为 Connector,连接至 BI 工具 QuickSight
- 在 QuickSight 中自定义 Widget 和 Dashboard
详细步骤
1.到 Glue Crawler (爬网程序) 中,点击添加爬网程序 (add crawler ),定义 S3 数据所在位置,也就是刚才 Databrew 的输出位置 。定义完成后,记得点击 run crawler 以启动此运行任务。 当job 完成后,请到左侧 Table (表)这一栏中检查 data schema 。


2.因 Athena 使用的是 Glue 的数据目录,因此点击来到 Athena,可以看到刚才我们爬网过的 defect-rate 的 table,本文也用 Glue 也爬过其他的两张原始表,显示如下。
3.控制台到 QuickSight ,添加数据集 (dataset), 选择 Athena 作为数据源。根据提示,选择目标表,将数据加载到 QuickSight 当中。

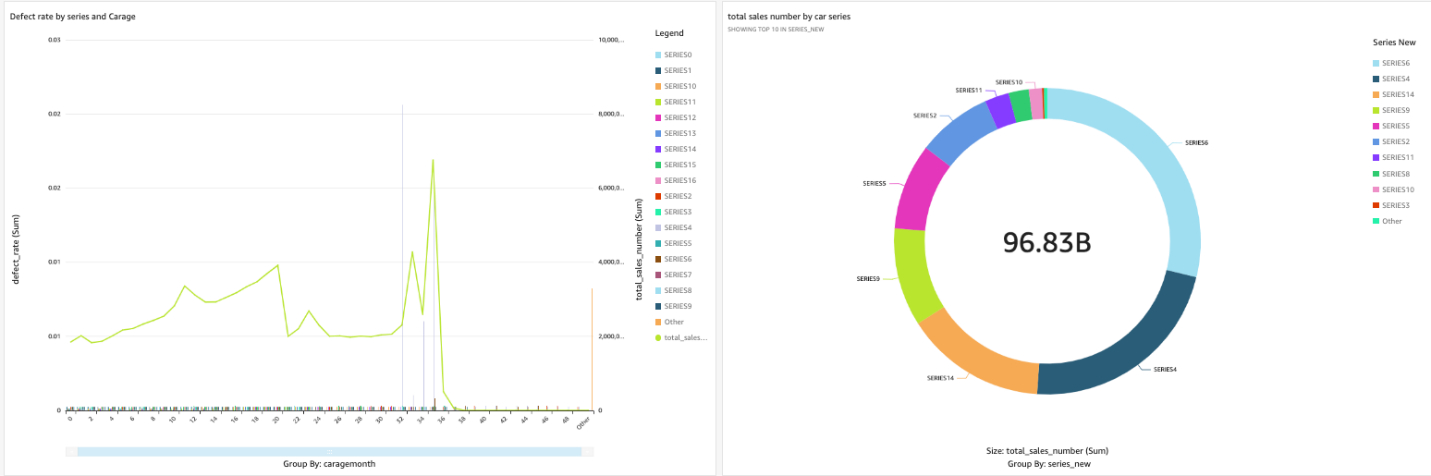
4.导入成功后,添加 New analysis , 在这里可以利用数据的不同维度,以及不同的图表形式,进行自定义的数据探索和展示。本文以不同车型的 defect rate,销量为例,可以看出,SERIES4 为比较畅销的一款车型,此车故障率较高,且故障率基本高频发生在车龄三年左右的时候,我们可以根据此规律提前做客户关怀和车检。 因此文重点不在于 Quicksight 的使用,因此不再展开,如对 QuickSight 使用不熟悉,可以点击此教程 做参考。

12.在将所有的数据都整合完毕后,点击右上方的 *share* ,可以将此发布为一个 dashboard
3. 利用 Sagemaker Canvas 作为机器学习的工具
该章节完成如下功能
- 对数据进行额外处理
- 合并多份数据
- 利用 Sagemaker Canvas 构建模型
- 生成预测
详细步骤
1.我们可以利用已有的数据做车辆销售数量预测,维修数预测等。本文以故障率作为 预测的目标为例。首先在 Databrew 将其他多余的 column 取出掉,只保留 series,caragemonth,defect_rate 三个列,目标是根据 series 和 carage,可以推测出不同系列车型的故障率。(也可以在下一步 csv 下载完毕后,手动移除掉这两列)
2.因为 Sagemaker Canvas 目前只支持一个单文件作为模型的 dataset,因此我们首先用 Athena 将多个 Databrew 输出的文件 merge 成单个 csv。 我们打开 Athena 执行 select * 之后像截图右下角所示将结果进行下载,这样我们得到一个单个 csv 文件。

3.进行必要的列移除(如第一步所述)
4.将数据上传至 Sagemaker Canvas dataset
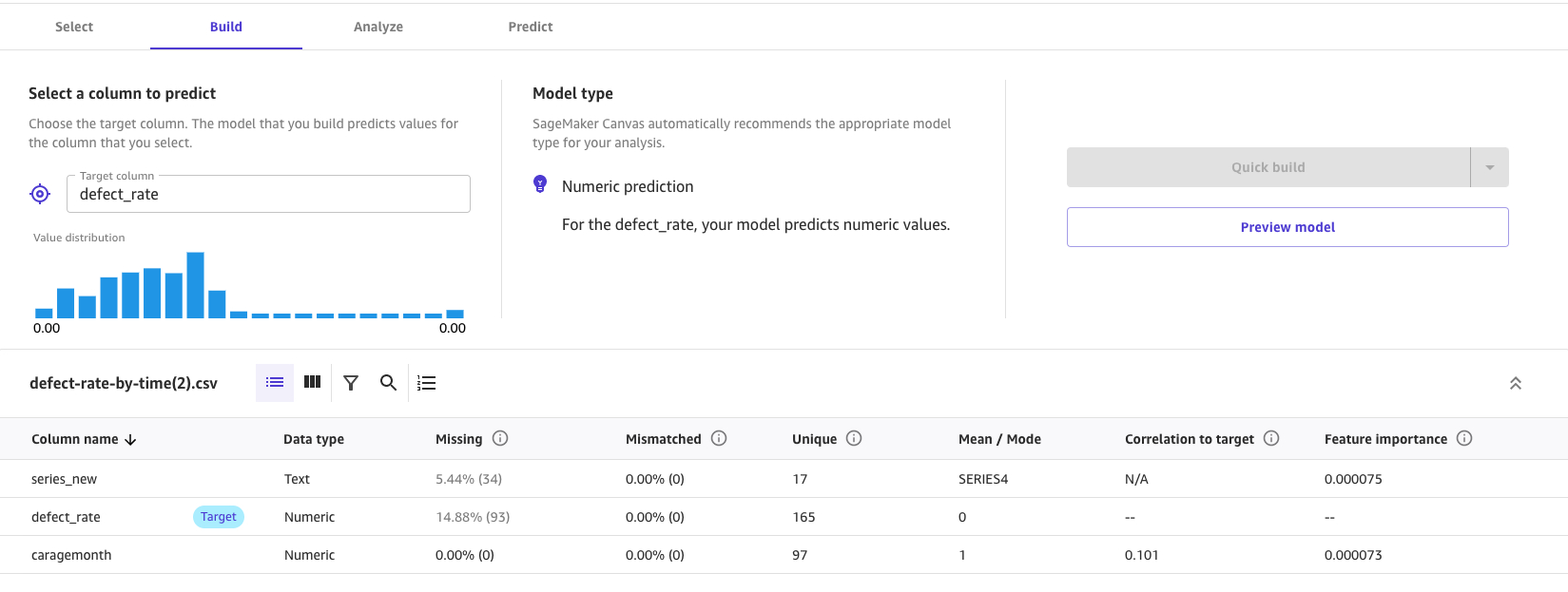
5.Create model,选中此数据集,选中 target 为 defect_rate。 如希望快速生成模型,选择 quick build 以构建模型(2-15min); 如需要更高的精准度,选择 standard build (2-4小时)。本文选择 quick build。
6.等待模型生成后,就可以根据 carage 做故障率的预测。可以上传一份 csv 文件,做 batch prediction;也可以输入单个值进行 single prediction。 本文以前者为例,上传希望预测的 series 和 carage(120个月),最终得到结果如下

8.如果选择的是 Standard build,在模型创建后,SageMaker Canvas 还可以一键将模型共享到 Amazon SageMaker Studio ,使业务分析师可以邀请数据科学家对模型和共享数据集进一步验证和进一步优化 ML 模型,达到生产部署的水平。

结论
本文提供了一个基于图形化的数据处理和 AutoML 的方案,利用 Glue Databrew 和 Sagemaker Canvas 等服务,构建一个无代码数据分析和机器学习平台,一方面,帮助客户业务分析师降低数据处理和ML 专业知识的学习曲线,降低跨部门沟通成本,保持AutoML结果的可解释性,方便与数据科学家在模型和数据集层面共享并持续优化。 另一方面,此平台基于无服务器,无需客户管理服务器,按需付费。