亚马逊AWS官方博客
使用 Amazon Lake Formation 为数据网格构建数据共享工作流
解决方案概览
AWS 中用于分析的典型数据网格架构包含一个中央账户,该账户汇总来自多个生产者账户的所有不同的数据产品。使用者可以在单个位置搜索可用的数据产品。与使用者共享数据产品时,实际上不会创建单独的副本,而只是创建指向目录项的指针。这意味着生产者对其产品所做的任何更新都会自动反映在中央账户以及所有使用者账户中。
基于这一点,解决方案包含了多个组件,如下图所示:

中央账户包括以下组件:
- AWS Glue – 用于数据目录用途。
- AWS Lake Formation – 用于保护对数据的访问,并提供数据共享功能来支持数据网格架构。
- AWS Step Functions – 实际工作流将定义为状态机。您可以进行自定义以符合企业的审批要求。
- AWS Amplify – 工作流 UI 使用 Amplify Framework 对访问实施保护。它还使用 Amplify 托管基于 React 的应用程序。在后端,Amplify Framework 创建了两个 Amazon Cognito 组件来支持安全要求:
- 用户池 – 提供用户目录功能。
- 身份池 – 通过使用 Amazon Cognito 用户池作为用户详细信息的位置来提供联合登录功能。身份池提供了临时凭证,以便工作流 UI 能够访问 AWS Glue 和 Step Functions API。
- AWS Lambda – 包含由 Step Functions 状态机编排的应用程序逻辑。此外,它还会在生产者批准或拒绝访问请求时提供必要的应用程序逻辑。
- Amazon API Gateway – 为生产者提供 API 以便接受和拒绝请求。
生产者账户包含以下组件:
- Amazon Simple Notification Service(Amazon SNS)– 生产者在 SNS 主题中维护其审批者名单。在需要审批时,工作流引擎会在相应数据拥有者的 SNS 主题中发布消息。
- AWS Identity and Access Management(IAM)– 如果工作流引擎需要向生产者的 SNS 主题发送审批请求,它会代入
ProducerWorkflowRole角色。
使用者账户包含以下组件:
- AWS Glue – 用于数据目录用途。
- AWS Lake Formation – 在数据可用后,使用者可以通过 Lake Formation 向其用户授予访问权限。
- AWS Resource Access Manager(AWS RAM)– 如果被授予者账户与授予者账户属于同一企业,则可立即向被授予者提供共享资源。如果被授予者账户不属于同一企业,则 AWS RAM 会向被授予者账户发送邀请,以便其接受或拒绝资源授予。有关 Lake Formation 跨账户访问的更多详细信息,请参阅跨账户访问:工作原理。
解决方案分为多个步骤:
- 部署中央账户后端,包括工作流引擎及其关联组件。
- 为生产者账户部署后端。您可以重复执行此步骤多次,具体取决于要加入工作流引擎的生产者账户的数量。
- 在中央账户中部署可选的工作流 UI,以便与中央账户后端进行交互。
工作流概览
下图展示了工作流。在这个特定的示例中,状态机将检查表或数据库(取决于共享的内容)是否具有 pii_flag 参数,以及此参数是否设置为 TRUE。如果同时满足这两个条件,它将向生产者的 SNS 主题发送审批请求。否则,它会自动与提出请求的使用者共享产品。

此工作流是解决方案的核心,并且可根据企业的审批流程进行自定义。此外,您还可以向数据库、表甚至列添加自定义参数,以附加额外的元数据来支持工作流逻辑。
先决条件
以下是部署要求:
- 数据网格设置
- NodeJS v14.x
- Yarn v1.22.10+
- AWS Cloud Development Kit(AWS CDK)CLI v1.119.0+
- Amplify CLI v5.3.0+(用于工作流 UI)
- 您在其中部署的每个账户(中央账户和生产者账户)的 AWS 配置文件
您可以从 GitHub 存储库克隆工作流 UI 和 AWS CDK 脚本。
部署中央账户后端
要为中央账户部署后端,请在克隆 GitHub 储存库后转到项目的根目录,然后输入以下代码:
这将部署以下项:
- Lambda 函数和 Step Functions 状态机使用的 IAM 角色
- Lambda 函数
- Step Functions 状态机(工作流本身)
- API Gateway
部署完成后,它会在 src/cfn-output.json 位置生成一个 JSON 文件。UI 部署脚本使用该文件生成范围缩小的 IAM 策略和工作流 UI 应用程序,以找到由 AWS CDK 脚本创建的状态机。
用于中央账户部署的实际 AWS CDK 脚本位于 infra/central/ 中。这还包括状态机和 API Gateway 使用的 Lambda 函数(位于 infras/central /functions/ 文件夹中)。
Lake Formation 权限
下表包含中央账户数据湖管理员需要向各个 IAM 角色授予的后端的最低权限,以使其能够访问 AWS Glue 数据目录。
| 角色 | 权限 | 可授予 |
| WorkflowLambdaTableDetails |
|
不适用 |
| WorkflowLambdaShareCatalog |
|
|
工作流目录参数
工作流使用以下目录参数来提供其功能。
| 目录类型 | 参数名称 | 描述 |
| 数据库 | data_owner |
(必需)拥有数据产品的生产者账户的账户 ID。 |
| 数据库 | data_owner_name |
用于在 UI 中标识生产者的易读名称。 |
| 数据库 | pii_flag |
一个标志(true/false),用于确定数据产品是否需要审批(基于示例工作流)。 |
| 列 | pii_flag |
一个标志(true/false),用于确定数据产品是否需要审批(基于示例工作流)。这仅在请求表级访问权限时可用。 |
您可以使用 UpdateDatabase 和 UpdateTable 分别将参数添加到数据库和列级粒度。或者,您可以使用适用于 AWS Glue 的 CLI 添加相关参数。
使用 AWS CLI 运行以下命令来检查数据库中的当前参数:
您将获得以下输出:
要使用上表中指示的参数来更新数据库,我们首先创建输入 JSON 文件,其中包含我们要用来更新数据库的参数。例如,参见以下代码:
运行以下命令来更新数据目录:
部署生产者账户后端
要为生产者账户部署后端,请转到项目的根目录并运行以下命令:
这将部署以下项:
- 已在其中发布审批请求的 SNS 主题。
- 与中央账户建立了信任关系的
ProducerWorkflowRoleIAM 角色。此角色允许 Amazon SNS 发布到之前创建的 SNS 主题。
您可以运行此部署脚本多次,每次均指向要参与工作流的不同生产者账户。
要接收通知电子邮件,请在部署脚本创建的 SNS 主题中订阅您的电子邮件。例如,我们将主题命名为 DataLakeSharingApproval。要获取完整 ARN,您可以转到 Amazon Simple Notification Service 控制台或运行以下命令来列出所有主题并获取 DataLakeSharingApproval 的 ARN:
在获取 ARN 后,您可以通过运行以下命令来订阅电子邮件:
之后,您将通过订阅的电子邮件地址收到一封确认电子邮件。选择 Confirm subscription(确认订阅)以接收来自此 SNS 主题的通知。
部署工作流 UI
工作流 UI 设计为部署在中央数据目录所在的中央账户中。
要开始部署,请输入以下命令:
这将部署以下项:
- Amazon Cognito 用户池和身份池
- 基于 React 的应用程序,用于与目录进行交互和请求数据访问权限
部署命令将提示您输入以下信息:
- 项目信息 – 使用原定设置值。
- AWS 身份验证 – 将您的个人资料用于中央账户。Amplify 使用此配置文件来部署后端资源。
- UI 身份验证 – 使用原定设置配置和您的用户名。当系统要求配置高级设置时,请选择 No, I am done(不,我已完成)。
- UI 托管 – 使用 Amplify 控制台进行托管,然后选择手动部署。
该脚本提供了部署的项的摘要。输入 Y 会触发要在后端部署的资源。该提示与以下屏幕截图的内容类似:

部署完成后,系统只会提示您输入初始用户信息,例如用户名和电子邮件。系统会自动生成临时密码并将其发送到提供的电子邮件。用户须在首次登录后更改密码。
部署脚本通过附加到经 Amazon Cognito
身份验证的 IAM 角色的内联策略向用户授予 IAM 权限:
剩下的最后一步是向与 Amazon Cognito 身份池关联的经身份验证的 IAM 角色授予 Lake Formation 权限(对数据库和表的 DESCRIBE 权限)。您可以通过运行以下命令来查找 IAM 角色:
IAM 角色名称位于 awscloudformation 键下的 AuthRoleName 属性中。授予所需权限后,您可以使用浏览器中提供的 URL 来打开工作流 UI。
我们会通过电子邮件将临时密码发送给您以便您完成初始登录,之后,系统会要求您更改密码。
登录后,首页会显示使用者可以访问的数据库的列表。

选择 Request Access(请求访问权限)可查看数据库详细信息和表的列表。

选择 Request Per Table Access(按表访问权限请求),然后查看表级别的更多详细信息。

返回上一页,我们通过输入接收共享请求的使用者账户 ID 来请求数据库级别的访问权限。

由于此数据库已贴有 pii_flag 标签,因此工作流需要向产品拥有者发送审批请求。要接收此审批请求电子邮件,产品拥有者需通过电子邮件订阅产品账户中的 DataLakeSharingApproval SNS 主题。详细信息看起来应类似于以下屏幕截图:

该电子邮件看起来类似于以下屏幕截图:

产品拥有者选择 Approve(批准)链接以促使 Step Functions 状态机继续运行并将目录项共享给使用者账户。
在此示例中,使用者账户不属于企业,因此,使用者账户的管理员必须转到 AWS RAM 并接受邀请。
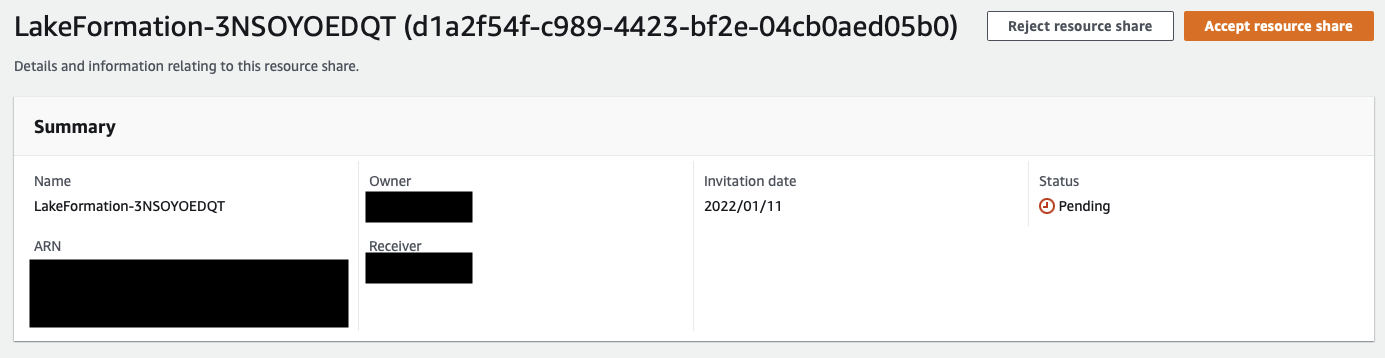
接受资源共享后,共享数据库将显示在使用者账户的目录中。
清除
如果您不再需要使用此解决方案,请使用提供的清除脚本来删除已部署的资源。
生产者账户
要从生产者账户中删除已部署的资源,请对您在其中部署的每个生产者账户运行以下命令:
中央账户
运行以下命令可从中央账户中删除工作流后端:
工作流 UI
工作流 UI 的清除脚本依靠 Amplify CLI 命令来启动对已部署资源的清除。此外,您可以使用自定义脚本删除由 Amazon Cognito 使用的经身份验证的 IAM 角色中的内联策略,以便 Amplify 能够完全清除所有已部署的资源。运行以下命令可触发清除操作:
此命令不需要 profile 参数,因为它使用现有 Amplify 配置来推断资源的部署位置以及使用的配置文件。
结论
这篇博文说明了如何构建工作流引擎来自动实施企业的审批流程,从而获得对具有不同敏感度的数据产品的访问权限。通过使用工作流引擎,可以自助方式实现数据共享并编纂企业的内部流程,使其能够随着更多数据产品和团队的加入而安全地扩展。
提供的工作流 UI 演示了一种可能的集成方案。其他可能的集成方案包括与企业工单系统集成以触发工作流以及接收和响应审批请求,或者与企业聊天应用程序集成以进一步缩短审批周期。
最后,可以使用所演示的方法来实现高度定制。企业可以完全控制工作流、定义数据产品敏感度级别的方式、自动审批的内容以及需要进一步审批的内容、审批的层次结构(例如,单个审批者或多个审批者)以及交付审批并采取行动的方式。您可以利用这种灵活性来自动实施公司的流程,帮助他们安全地加速成为一个数据驱动型企业。
关于作者
 Jan Michael Go Tan 是 Amazon Web Services 的首席解决方案构架师。他帮助客户使用 AWS 云设计可扩展的创新性解决方案。
Jan Michael Go Tan 是 Amazon Web Services 的首席解决方案构架师。他帮助客户使用 AWS 云设计可扩展的创新性解决方案。