亚马逊AWS官方博客
搭建基于S3的HBase读备份集群
作者:刘磊
当前aws的很多客户已经从将s3作为HBase的存储中获益,这当中包括更低的存储花费、更好的数据可靠性、更容易的扩展操作等待。比如FINRA就通过将HBase迁移到s3上将在存储上的花费降低了60%,此外还带来了运维上的便利,以及架构上的重大优化:将s3作为统一的存储层,实现了更彻底的存储和计算分离。在s3上部署HBase集群,可以让你在集群启动后立即进行数据查询操作,而不用等待漫长的快照恢复过程。
随着Amazon EMR 5.7.0的发布,现在你可以在集群层面进一步提升数据的高可用性和高可靠性,方法是基于同一个s3存储桶建立多个HBase的读备份集群。这会让你的数据通过读备份集群及时地被用户访问,即使在主集群遇到问题关闭的时候,当然你还可以通过在多个可用区中部署读备份集群来进一步增加数据访问服务的可靠性。
接下来的文章将告诉你如何在s3上建立HBase的读备份集群。
HBase 简介
Apache HBase是Apache Hadoop生态体系中的大规模、可扩展、分布式的数据存储服务。同时它还是开源的,非关系型的版本数据库,默认情况下运行在HDFS之上。它的设计初衷是为包含了数百万个列的数十亿行记录提供随机的、强一致性的、实时访问。同时它还和Apache Hadoop、Apache Hive和Apache Pig等大数据服务紧密结合,所以你可以轻易地为并行数据处理提供快速的数据访问。HBase数据模型、吞吐量、和容错机制能很好地为广告、web分析、金融服务和基于时间序列数据的应用等工作负载提供支持。
和其他很多Nosql数据库类似,HBase中的表设计直接影响着数据的查询和访问模式,根据这些模式的不同,查询的性能表现也会有非常大的差异。
HBase on S3
在建立基于S3的HBase读备份集群之前,你必须先学会HBase on S3的部署方法,本段为那些不熟悉HBase on S3架构的人提供了一些基本信息。
你可以通过将S3作为HBase的存储层,来分离集群的存储和计算节点。这使得你可以根据计算需求来规划集群,从而削减开支,毕竟你不再需要为HDFS上存储的3备份数据支付费用了。
HBase on S3架构中的默认EMR配置使用内存和本地磁盘来缓存数据,以此来提升基于S3的读性能。你可以在不影响底层存储的情况下任意地对计算节点进行伸缩,或者你还可以关闭集群来节省开支,然后快速地在另一个AZ中重新进行部署。
HBase on S3读备份集群应用案例
使用HBase on S3架构使得你的数据被安全、可靠地存储起来。它将数据和集群隔离进行存储,消除了因为集群异常终止带来数据丢失的可能性。尽管如此,在一些特殊情况下,你还是会希望数据能获得更高的可用性,比如集群异常终止或者整个AZ失效。另外一个情况是,通过多个集群访问一个S3上的根目录,你可以隔离HBase集群的读写操作,从而来降低集群的压力,提供更高SLA的查询服务。尤其是在主集群因为bulk load、heavy write、compaction等操作变得异常繁忙的时候。
下图展示了没有读备份的HBase on S3架构,在这个场景下,诸如集群终止和AZ失效等异常情况会使得用户无法访问数据。
S3上的HBase根目录,包含了HFile和表的原数据信息。

EMR 5.7.0之前的版本,无法将多个HBase集群指向同一个S3上的根目录,为了获得更高的可用性,你需要在S3上创建多个数据副本,并管理它们之间的一致性。
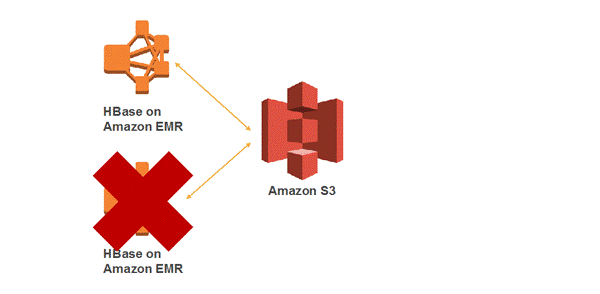
随着EMR 5.7.0的发布,现在你可以启动多个读备份集群并指向S3桶上同一个根目录,保证了你的数据通过读备份集群它们总是可达的。

下面是一些使用HBase读备份集群的例子,展示了启用前后的一些对比情况。
处于同一个AZ的HBase读备份集群:



处于不同AZ的HBase读备份集群:

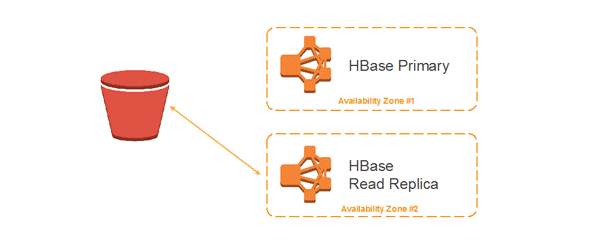
基于S3的HBase读备份集群的另一个好处是可以更加灵活地根据具体的工作负载来规划你的集群。比如,虽然你的读负载很低,但还是想要获得更高的可用性,那么就可以启动一个由较小实例组成的规模较小的集群。另一个例子是当你遭遇bulk load时,在高峰期集群需要扩张到很大以满足计算需求,在bulk load结束后,集群可以立即缩减以节省开支。在主集群伸缩的时候,读备份集群可以维持一个固定的规模以对外提供稳定的查询服务。
步骤
使用下列的步骤来启动基于S3 的HBase读备份集群,这项功能只针对EMR 5.7.0之后的版本。
创建使用HBase on S3的EMR集群:
配置文件示例JSON
向主集群添加数据
需要特别注意的是,在使用HBase读备份集群时,你必须要确保主集群上所有的写操作都被刷新到S3桶的HFile中。读备份集群会读取这些HFile中的数据,任何没有从Memstore刷新到S3的数据都不能通过读备份集群访问。为了确保读备份集群总是读到最新的数据,请参考以下步骤:
- 写入数据到主集群(大批量写入请使用Bulkload)
- 确保数据被刷新到S3桶中(使用Flush命令)
- 等待region 分割以及合并操作完成以确保HBase表的元数据信息保持一致性状态
- 如果任何region发生了分割、合并操作,或者表的元数据信息发生了变化(表的增加和删减),请在从集群上运行refresh_meta命令
- 当HBase表发生更新操作后,请在从集群上运行refresh_hfiles命令
从备份集群读区数据
你可以像往常一样从备份集群检索任何数据。
从主集群读取数据的截图:

从备份集群读取数据的截图:

可以看出,两个集群返回了同样的数据。
保持备份集群和主集群的一致性
为了保持备份集群数据和主集群的一致性,请参考以下建议:
在备份集群上:
1.运行refresh_hfiles命令:
- HBase表中的数据发生变化时(增、删、改)
2.运行refresh_meta:
- Region发生变化时(splits,compacts)或者集群中增加、删除了HBase表
在主集群上:
1.如果启用了compaction,运行compaction命令以避免Major Compation被触发引起数据的不一致性。
相关的属性和命令:
HBase属性:
| Config | Default | Ex planation |
| hbase.meta.table.suffix | “” | Adds a suffix to the meta table name: value=’test’ -> ‘hbase:meta_test’ |
| hbase.global.readonly.enabled | False | Puts the entire cluster into read-only mode |
| Hbase.meta.startup.refresh | False | Syncs the meta table with the backing storage. Used to pick up new tables or regions. |
如果hbase.emr.readreplica.enabled被设置为true,那么上述属性会被自动设置好。
HBase命令:
| Command | Description |
| refresh_hfiles <Tablename | Refreshes HFiles from disk. Used to pick up new edits on a read replica. |
| clear_block_cache <tablename> | Clears the cache for the specified table. |
| refresh_meta | Syncs the meta table with the backing storage. Used to pick up new tables/regions. |
总结
现在你可以为HBase建立高可用的读备份集群,通过它,在主集群发生异常情况时,你仍然可以获取稳定的数据查询服务。
作者介绍:

刘磊,AWS大数据顾问,曾供职于中国银联电子支付研究院,期间获得上海市科技进步一等奖,并申请7项国家发明专利。现任职于AWS中国专家服务团队,致力于为客户提供基于AWS服务的专业大数据解决方案、项目实施以及咨询服务。