亚马逊AWS官方博客
使用Fluent Bit与Amazon OpenSearch Service构建日志系统
一.概述
日志系统作为企业日常运维重要支撑,以及大数据分析、审计工作,已经成为企业IT系统不可缺少的重要组成部分。下面,我们考虑这样一种场景,我们在Amazon Web Services的 EC2中部署了Nginx,用于构建我们的Web Server,我们日常运维需要通过Nginx日志,及时了解到系统当前的PV、UV等指标。那么使用Amazon Web Services原生服务与开源工具的结合能否快速构建日志系统呢?阅读本文,您将会了解到:
- 如何通过Amazon for Fluent Bit 2.21.1将日志收集到Amazon Kinesis Data Streams
- 如何通过Amazon Lambda处理日志
- 如何通过Amazon for Fluent Bit 2.21.1将日志收集到Amazon S3
- 如何使用Amazon Managed Grafana结合Prometheus用于日常监控
- 常见问题和优化方法
Fluent Bit是一个使用C语言编写的开源的轻量级日志收集和转发工具,它可以帮助您从不同来源收集数据,如操作系统指标和日志等,使用Parsers可以解析日志,并且通过Outputs将它们发送到多个目的地。借助于Amazon for Fluent Bit 2.21.1版,您可以使用Amazon Kinesis Data Streams输出插件将您的记录提取到Kinesis服务中,并通过Kinesis触发Amazon Lambda来处理数据,并将日志发送到Amazon OpenSearch Service中。
Amazon OpenSearch Service可让您轻松执行交互式日志分析、实时应用程序监控、网站搜索等工作。OpenSearch 是一款开源的分布式搜索和分析套件,衍生自 Elasticsearch。不仅可以支持PB级文本与非结构化数据的搜索、可视化和分析,同时还可以与Amazon VPC集成,并提供多项安全功能,简化了管理员的日志分析工作。借助于Amazon Lambda,我们可以使用Python API将处理后的数据写入到Amazon OpenSearch Service服务。
二.简要说明
下面我们基于下图的总体架构,以us-west-2为例,详细讲解一下整个的实现过程。

1.通过Fluent Bit将日志收集到Amazon Kinesis Data Streams
- 通过控制台创建Amazon Kinesis Data Stream,作为日志系统的数据缓冲区,接收来自于Fluent Bit发送的数据。这样不仅可以避免由于客户端连接过多导致Amazon OpenSearch Service压力过大,还可以通过Amazon Lambda与Amazon Kinesis Data Stream集成,对数据进行处理或异常行为的分析报警等。如下图所示,我们将数据流名称设置为LogStream。

对于数据流容量模式,本文选择“按需”模式用于以下场景,大家可以根据自己的实际需求,选“按需”或“预置”,如果大家想了解更多关于“按需”或“预置”的选择,可以点击这里查看我们的官方文档。
- 接下来我们创建一台EC2,AMI选择支持ARM架构的Amazon Linux 2,并在EC2上安装SSM Agent与Nginx。创建过程我们选择默认的VPC并创建一个安全组, Nginx日志文件路径设置为默认路径
/var/log/nginx/,参考截图如下:

- 为EC2创建新的IAM角色,并将该角色附加到EC2上,这样Fluent Bit可以有权限写入Kinesis的数据流,关于角色的策略文档,参考如下:
注意,请将<YOUR ACCOUNT ID>替换成您所使用的账户ID。
- 安装与配置Amazon for Fluent Bit 21.1
sudo docker pull amazon/aws-for-fluent-bit: 2.21.1
并在/etc/fluent-bit/conf/目录下创建一个fluent-bit.conf配置文件,在配置文件中我们指定Nginx日志文件路径与Kinesis Stream名称,Fluent Bit配置文件内容参考如下:
配置完成后,我们启动Fluent Bit,查看/tmp/fluent-bit.log日志文件验证启动状态。考虑到有些场景下,可能不需要docker,大家可以将Fluent Bit从docker中复制到宿主机上运行。
/opt/fluent-bit/bin/fluent-bit -c /etc/fluent-bit/conf/fluent-bit.conf

- 创建VPC Endpoint。截止到上一步,安装在EC2上Fluent Bit在连接Amazon Kinesis Stream时使用的是公网链路,但在实际场景中,可能我们需要通过私有IP来连接,这时候可以通过建立VPC Endpoint来满足需求。选择EC2所在的VPC以及对应的安全组。

2.使用Amazon Lambda处理日志
通过前面步骤我们已经将日志发送到日志缓冲区-Amazon Kinesis Stream中,下面我们来创建一个Amazon Lambda Function,用来消费Amazon Kinesis Stream,并将日志发送到Amazon OpenSearch Service中。创建之前,大家可以参考我们官方文档来创建一个通过VPC访问的OpenSearch Domain,并使用Nginx通过代理方式访问VPC内的OpenSearch 控制面板。为了简化,在选择VPC时我们可以选择EC2所在的VPC。
- 创建Amazon Lambda Function,并勾选启用网络,选择OpenSearch所处的VPC,以及相应的子网与安全组。因为我们的示例代码使用的是Python,所以函数的运行时请选择9。

关于访问OpenSearch的Python示例代码参考如下:
关于Lambda函数的部署,可以参考如下方式来生成部署的zip包:
- 为Lambda函数添加Kinesis触发器

- 为Lambda函数的执行角色添加Kinesis权限,策略文档参考如下
注意,请将<YOUR ACCOUNT ID>替换成您所使用的账户ID。
- 复制创建的Lambda函数执行角色的ARN:

登录OpenSearch的控制面板,设置Backend role,将Lambda的执行角色与OpenSearch的角色做一个映射,这样Lambda函数就拥有通过OpenSearch API创建索引以及更新、删除文档的权限。

3.配置Fluent Bit的Nginx Parser
经过前面的配置,登录Amazon OpenSearch Service的dashboard,并查看导入的Nginx日志数据,我们发现导入的日志还存在一些不足,没有将日志内容按多个字段保存,这种方式不利于我们后续的统计分析,那么如何做进一步优化呢?

- 配置Fluent Bit的Nginx Parser文件
在/etc/fluent-bit/conf目录下创建文件,参考内容如下:
修改/etc/fluent-bit/conf/fluent-bit.conf文件,添加Parser配置,参考截图如下

完整内容参考如下:
注意:parsers.conf文件中Name要与 Parser处设置的内容相同,如果有解析Apache的日志或其它类型日志的需求,可以参考https://raw.githubusercontent.com/fluent/fluent-bit/master/conf/parsers.conf链接文件。
- 重新启动Fluent Bit,验证索引文档
更改后,我们发现日志已经按照字段进行分类存储,参考截图如下:
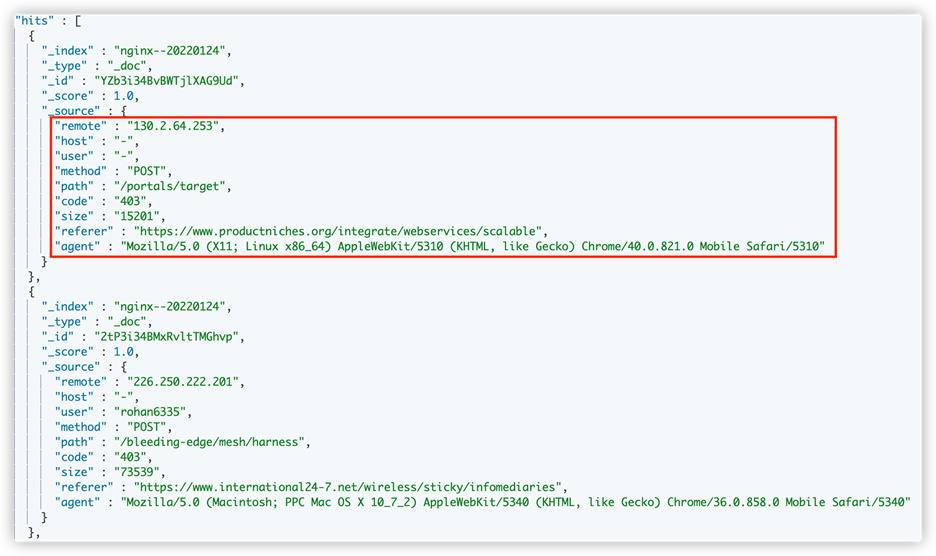
4.通过Fluent Bit将数据写入S3
上述场景我们已经看到EC2上的Nginx日志数据通过Fluent Bit写入Amazon Kinesis Data Stream后,经过Lambda处理后,写入Amazon OpenSearch Service。但是,有些场景下,我们还需要保存原始数据。下面,我们基于下图更改后架构图,讲解一下操作步骤:

- 修改
/etc/fluent-bit/conf/fluent-bit.conf文件,修改内容参考如下:
通过增加Fluent Bit的S3的output插件,我们即可将数据发送到指定的S3的bucket中,完整配置内容参考截图如下:
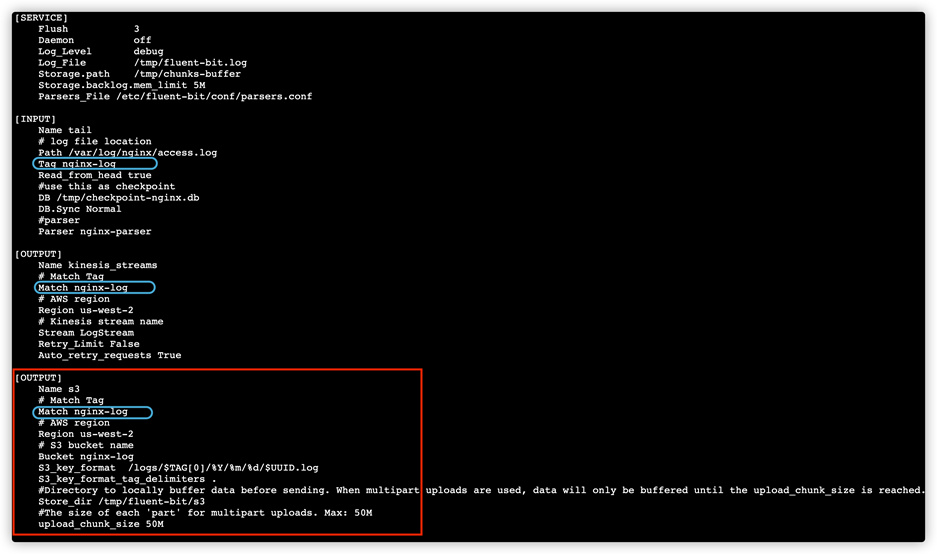
- 添加VPC Endpoint,使EC2上Fluent Bit通过内网访问S3的桶

- 为EC2上附加的角色添加匹配的S3桶权限。
再次重新启动Fluent Bit后,EC2的日志文件即可同时写入S3桶与Amazon Kinesis Data Stream中。
三.为Fluent Bit添加Prometheus监控
如果您已经使用Amazon Managed Grafana结合Prometheus用于日常监控,我们也可以为Fluent Bit添加Prometheus监控项,参考操作如下:
- 修改Fluent Bit配置文件,在“[SERVICE]”标签下添加Prometheus监控地址与端口,参考内容如下:
注意,请将http_listen 172.XXX.XXX.XXX替换成您所创建的EC2私有IP地址。修改完成后,重起Fluent Bit即可生效,重启命令如下。
- 在Prometheus的配置文件中添加如下内容,并重启Prometheus
- 添加安全组规则,允许来自于Prometheus的IP访问
- 为Amazon Managed Grafana添加Fluent Bit的dashboard,dashboard的下载链接如下:
https://grafana.com/grafana/dashboards/7752
设置完成后,您即看到Fluent Bit的监控信息

五.常见问题和优化方法
1.对于多行日志的处理,Fluent Bit是否支持?如Spring Boot日志。
支持,可以参考如下链接配置文件:
2.通过Fluent Bit向Kinesis Data Stream发送数据失败后怎么办?
Fluent Bit引擎有一个调度器,每隔一段时间会刷新一次数据,通过输入插件获取数据后,将数据传输到输出插件。在配置“kinesis_streams”插件时,可以通过Retry_Limit参数设置。该参数默认值
为1,当值设置为N时,代表尝试N次发送,N必须大于或等于1;当参数设置为False时,代表无限制尝试重试;如果发送失败,不想进行重试,可以设置为no_retries。在实际业务场景处理数据时,需要考虑因为重试产生的重复数据的处理。
3.如何通过Lambda调整消费Amazon Kinesis Data Stream的速度?
在配置Lambda function对应的Amazon Kinesis Data Stream trigger时,默认1个Kinesis Data Stream的shard对应1个Lambda function的并发,如果需要提高Lambda的并发,可以在配置trigger时可以在“其他设置”中进行如下图的设置:

如果这里设置的每个分片(shard)的并发批处理数是2,Kinesis 的分片(shard)数量是50, 那么Lambda function的并发就会有50*2 = 100个。
六.总结
在本文中,我们介绍了如何通过开源日志收集工具Fluent Bit结合Amazon Kinesis Data Stream、Amazon Lambda、Amazon OpenSearch Service快速搭建日志系统,以满足日常运维的需求。您可以根据具体的使用需求进一步修改Fluent Bit的配置以及Lambda的代码。如果您对本文有任何意见和建议,请与我们分享!
七.参考资料
- Amazon OpenSearch Service资料:https://docs.aws.amazon.com/zh_cn/opensearch-service/latest/developerguide/what-is.html
- Amazon Kinesis Data Streams资料:https://docs.aws.amazon.com/zh_cn/streams/latest/dev/introduction.html
- Fluent Bit资料:https://docs.fluentbit.io/manual/