亚马逊AWS官方博客
使用 Amazon Athena 和 Amazon S3 ,助力企业构建低成本高性能日志分析平台
在本篇文章中,我将介绍一个使用 Amazon Athena 和 Amazon S3 构建的日志分析平台。如果您的企业有大量日志数据,但是没有较多的费用投入,并且需要日志分析平台高性能、弹性、低运维、低开发等特性,那么可以参考这个方案。
案例介绍
我们以某电子票据 SaaS 公司 X 为例来介绍企业该日志分析方案的应用场景。公司 X 是一家专业的供应链信息协同及增值税发票管理云平台解决方案提供商。在“金税四期”和“全电发票”的过程中,公司 X 深度理解政策和行业,以结算协同(票税)为基础,布局供应链上下游协同,并向数据增值服务延伸,运用领先的技术平台和深厚的行业经验,为百余家 500 强企业提供了基于互联网和云创新的软件服务,连接上下游百万家优质供应商,提供近千亿元人民币的数据增值。
对于这样的企业,大概有上千个微服务应用,每天会产生 TB 级别的日志数据。对于这些数据,客户有如下几种使用需求:
- 应用线上运行情况追踪、监控、告警。
- 线上应用故障的技术调查与分析。
- 每日财务结算进行核对、复核的依据。
- 根据法律法规的合规要求,作为审计文档,供后续审计查询。
- 数据湖、数仓的源数据之一,为运营提供数据支持。
- 未来业务扩展,用于供应链金融的风险评估与风险管控。
挑战
公司 X SaaS 改造前的日志方案使用了一套全解决方案, 该方案初期使用确实友好,但是随着公司业务快速发展、业务需求越来越多样化,这种交钥匙式的全解决方案的短板越来越明显:
- 存储费用高。由于每天产生的日志量大,基于审计要求需要,至少保存 180 天以上,大量数据简单保存却要支付高价存储费。
- 数据分析费用高。需要创建数据索引才能使用相关的查询功能,而索引也会产生相应费用。
- 数据分析工具不弹性。先有解决方案,进行大数据分析时,需要提前购买相应的计算资源并支付相应的费用,空闲时也许支付高额资源费。
- 扩展性不强。由于是全解决方案,所有的功能由云平台提供,如果需要新功能只能寄期望于云厂商。
- 生态封闭。使用了该解决方案后,无法使用丰富的开源生态产品。
公司 X 在面对日志数据平台问题上,意识到必须基于更低的成本、更好的生态来构建自己的日志分析平台,才能支撑未来的业务发展与业务需求。于是客户进行了基于开源的多种尝试:
- 以 Elasticsearch 为核心的开源 ELK 方案。该方案的优点是成熟、生态丰富。但是,一样面临着存储成本高、弹性差。企业需要投入专门的人员进行 ELK 的运维管理。
- 以 Splunk 为代表的商业产品方案。这些产品功能丰富、扩展性强,也有良好的配套生态。但是,起步价格极高,后续还需要原厂持续的技术支持与技术服务。
在多种尝试后,客户发现,很难有产品,能满足他们成本低、可扩展、运维简单、生态开放的业务需求。于是客户与我们联系,寻求我们的专业支持。
经过我们的实践,基于 Amazon Athena + Amazon S3 可以很好的解决上诉问题,构建一套低成本高性能的日志分析平台。
方案架构

方案介绍
整个方案分成两部分,日志查询和日志建模。
日志查询非常简单,依托 Amazon Athena 提供的 API 可以轻松和多种 BI 工具集成。你也可以直接使用 Amazon Athena 提供的 web 界面查询,或者使用官方提供的 Amazon Athena 的 API SDK,实现自己的查询客户端。过程比较简单,不再赘述!
另一个部分是,日志数据建模,帮助我们实现以下目标:
- 加速查询。通过进行数据分区设计有助于提高查询速度和大幅降低查询成本。我们往往根据业务经验,或者统计高频查询条件来确定分区字段。
- 结构化数据。日志数据往往都是 JSON, 可能存在嵌套,不方便以后的 SQL 查询,Amazon Athena 需要以 SQL 的形式和数据交互。
- 清洗数据。日志中可能存在很多和业务不相关的信息,这些信息会增大查询扫描量从而增加查询费用。
我们选择了直接使用 Amazon Athena 进行数据建模,一方面是架构和开发都比较简单,只需要使用 SQL 不用学习其他复杂技术栈即可实现近实时的数据处理,另一方面是数据处理费用也比较低。
整体建模流程如下图:

- 日志文件从各个业务系统,三方平台投递到 Amazon S3。
- 文件投递到 Amazon S3 后触发 Amazon S3 Trigger,调用 Amazon Lambda。
- Amazon Lambda 一方面发起该日志文件的处理过程,将状态同步到 Amazon DynamoDB。另一方面从日志文件文件名、路径等元信息、提取部分业务信息,将这些信息打包后推送到 Amazon Simple Queue Service (SQS)。
- Amazon Fargate 部署的处理程序消费 Amazon SQS 推送过来的任务。
- 具体的 ETL 逻辑。具体关键流程如下:
- 根据业务信息对待处理任务进行分组。
- 根据业务对延迟行的要求,对任务进行累积。由于不同业务对延迟性的要求不同,所以根据不同业务的要求,对待处理任务进行累积。累积的好处是降低资源的消耗,坏处是带来一定的延迟。
- 调用 Amazon Athena SDK,分别将不同批次的任务插入到 Amazon Athena 表中。
- 将 a,b,c 中各个步骤的关键节点状态信息同步到 Amazon DynamoDB。
- Amazon Athena 最终负责将生成好的日志表写入 Amazon S3。
这里补充说明一下:
- 为了方便让 Amazon Athena 将文件中的信息提取,系统会提前创建一些临时表,我们将同一业务,同一批次的日志文件复制到这些临时表对应的底层存储。这样,Amazon Athena 能直接查询这些临时表,提取日志文件中的业务信息。
- 将 Amazon Athena 将查询后,转换好的信息插入到目标数据表中,并清理临时表。
- 将以上各个步骤的处理状态都同步到 Amazon DynamoDB 中。
以上处理过程完毕后,日志分析的前端就能通过调用 Amazon Athena 的 API ,通过 SQL 查询建好模的日志数据表。
方案实施
方案所有相关代码和文档请参考这里。
限于篇幅,具体的构建流程,请参考代码库中的部署文档,这里介绍如何根据自己的业务实施该方案。
用代码文件 etl.py 构建一个 Amazon Fargate 应用,负责执行具体的任务消费,编组 ETL 逻辑。它定义了一个抽象类,需要你继承并实现两个抽象函数。
- get_etl_sql 用来定义提取日志文件信息的sql。
- get_task_meta 用来定义如何根据业务逻辑分组。

demo_etl.py 提供了一个比较具体的例子,你可参考它实现你自己的日志提取逻辑。
我们还是以电子票据 SaaS 公司 X 为例,介绍如何处理日志逻辑。电子票据 SaaS 公司 X 会将各个业务系统的日志文件打包成 gzip 文件推送到 Amazon S3 存储桶中,例如保存在如下路径:
该文件中保存了大量如下 schema 的 json 对象:
业务上常常需要需要根据业务类型,服务类型,服务域等业务信息进行查询,而这些信息保存在了包括文件路径和 json 对象里,所我们可以实现 ETL class,并实现 get_etl_sql 方法。
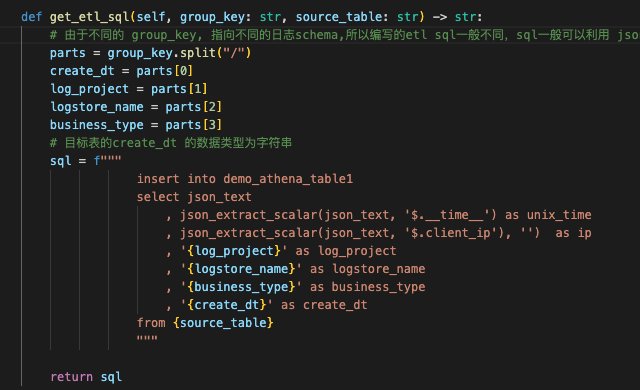
同时我们实现 get_task_meta, 对相同业务逻辑的日志文件进行编组,用统一的 group_key 来代表,这样可以实现多个日志文件的批量处理,节约 Amazon Athena 资源从而降低成本。

最终,日志数据将落入如下 schema 的表中:
接下来,你即可查询该表,进行日志的分析。
成本分析
我们结合电子票据 SaaS 公司 X 的实践,来进行成本分析:
目前公司 X 每日新增日志数据约 10G,平均每秒钟产生 10~50 个日志文件,在活跃的 12 个小时内,平均每秒 40 个文件,每个文件 12KB,日志数据在两个月后不再需要频繁访问,可进行数据归档,平均每天的日志查询量在 1000 次。由于经过来上诉建模过程,每次查询的平均扫描量在 1.2G。
| 费用原因 | 涉及服务名称 | 月度费用(单位:元) |
| 查询计算 | Athena | 1080 |
| ETL 计算 | Athena | 9 |
| 日志建模任务分发 | SQS | 166 |
| 日志建模 | Fargate | 158 |
| 文件监听及分发 | Lambda | 155 |
| 日志原始数据存储 | S3+S3 Glacier Flexible Retrieval | 384 |
| 日志建模后数据存储 | S3 | 174 |
| 总计 | 2126 |
总结
该方案能有效帮助客户完成自身对日志数据的诸多诉求,同时,这套方案兼具高性能,低运维成本的诸多优势,减少企业运营成本。另外,Amazon S3 亦作为现代智能湖仓的底座,可以无缝集成各种大数据、AI/ML 方案,进一步帮助企业挖掘日志数据中蕴含的价值,成为业务创新的动力!