亚马逊AWS官方博客
在中国区使用Amazon Step Functions Data Science SDK构建从AWS Glue(ETL)到Amazon SageMaker(推理)流水线
市场营销是金融领域的一个重要方向,在机构发展新客户的过程中,不容忽视老用户的流失情况。假如获得一个新客户的成本是保留一个老客户的成本的5倍,那么将其客户流失率降低5%,其利润就可能增加25%以上。
在本文中,我们将利用无服务器架构工作流,用于数据分析,模型部署,批量推理,从而实现提前发现可能的流失客户,及时维护避免流失。
方案概述
本文将以一个常见的使用案例,通过 Amazon Step Functions Data Science SDK创建基于无服务器架构的工作流,过程如下:
1.使用Amazon Glue进行ETL工作,生成样本数据集
2.使用SageMaker部署本地训练好的模型,用于机器学习推理
下图演示了上述Amazon Step Functions无服务器架构工作流:

后续操作使用了下列亚马逊云科技服务:
Amazon Step Functions ,是由多个离散步骤组成的状态机,其中每个步骤都可以执行任务、作出选择、启动并行执行或管理超时。其中一个步骤的输出作为下一个步骤的输入,并支持将错误处理嵌入到工作流中。
在Step Functions Data Science SDK诞生前,只能使用基于JSON的Amazon States Language定义Step Function;但现在可以借助此SDK使用Python代码轻松创建、执行和可视化Step Function工作流。
本文是以Step Functions Data Science SDK为主线,讨论如何创建Step Function步骤、使用参数、集成服务特定的功能以及将这些步骤关联在一起以创建和可视化工作流。
Amazon SageMaker可为开发人员和数据科学家提供构建、训练和部署不同类型机器学习模型时所需的工具。
Amazon Glue是一项完全托管的提取、转换和加载(ETL)服务,在分布式Apache Spark环境中运行,能够充分利用Spark而无需管理基础设施。将Glue指向受支持的数据存储,它将会生成代码以从指定的存储中提取数据并加载到目标存储中。
本文使用机器学习方法进行客户流失预测,采用模拟的数据(近期消费记录,在线时长等)为示例数据集,首先使用Amazon Glue进行数据处理,再使用Amazon SageMaker进行模型部署,并进行批量转换。
该场景的使用的算法为XGBoost (eXtreme Gradient Boosting),它是一种监督式学习算法, 尝试将一组较简单且较弱模型的一系列估计值结合在一起,从而准确地预测目标变量,可以用来处理回归、分类(二进制和多类)和排名问题。利用XGBoost预测客户是否会流失,以及早进行干预。
1. 创建Jupyter Notebook
1.1 创建Amazon SageMaker 笔记本实例,部署模型

1.2 创建一个笔记本实例,类型选择t2.medium。选择或者创建一个IAM角色(IAM Role)
1.3 其他部分选择默认选项,点击创建(Create)

1.4 在笔记本创建完成后,打开Jupyter,选择New,新建一个ipynb,选择内核为conda_python3
2. 使用Step Functions Data Science SDK创建和管理工作流
2.1 安装和加载所有必需的模块

2.2 按照代码中的注释要求,替换使用您自己的 S3 bucket/prefix
后面需要将数据上传到该项目的Amazon S3存储桶,用作训练模型的数据和Model Artifact的存储

2.3 按照代码中的注释要求,替换使用您自己的 S3 bucket/prefix
2.4 创建一个Role附加到Step Functions
关联的策略如下所示,可以根据实际使用的服务调整策略,并将策略附加到创建的Role

2.5 设置执行的Role
为确保SageMaker可以顺利运行相关的任务,这里获取笔记本实例的执行角色(创建SageMaker 笔记本实例的时候已经创建/选择的角色)。同理Step Function顺利运行的前提也是要有相应的执行角色,可参考上图中角色的关联资源。

3. 验证模型
3.1 安装和加载所有必需的模块
因为需要使用joblib来加载模型,需要使用sklearn版本为0.22.1。


3.2 读取样本数据
样本数据上传到Notebook后,可以看到共有1000行74列数据(列没有显示完),包括主键(cust_id)和用户按照时间维度统计的交易金额、在线换手率金额、在线赎回笔数等信息。

3.3 加载模型,返回预测标签
利用逻辑回归进行客户流失率建模,使用sklearn拆分测试集和训练集,提供回归的xgboost模型。
本文中的模型已在本地训练好,在Notebook中使用joblib加载模型。

4. 准备环境工作(执行一次)
4.1 打包容器&推送容器到ECR
编辑Dockerfile,准备镜像。
这个过程可能需要进行很多次,因为不可避免地要修改Dockerfile或者某类程序以使得它们可以正常工作。
建议使用官方镜像文件,在此基础上添加组件,国内镜像仓库地址参考如下链接:
https://docs.amazonaws.cn/sagemaker/latest/dg/sagemaker-algo-docker-registry-paths.html
在cn-north-1下使用sklearn的训练镜像和推理镜像的路径为:
450853457545.dkr.ecr.cn-north-1.amazonaws.com.cn


在拉取公共镜像之前,需要做基本身份验证

推送镜像到自有ECR镜像仓库

4.2 上传模型文件到S3
我们需要将本地已经训练好的模型放到之前创建的s3存储桶,prefix前缀是对象名称前的完整路径。比如一个对象model.tar.gz,存储路径BucketName/Project/Demo/model.tar.gz,则前缀是BucketName/Project/Demo/


4.3 推理脚本

4.3.1 打包代码并上传到s3


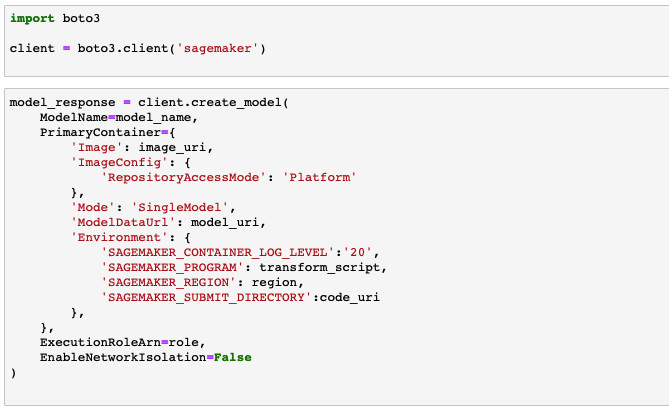
4.4 创建SageMaker模型对象
下图中的image_uri为4.1步骤中指定容器镜像地址,model_uri为4.2步骤中指定模型的s3路径,transform_script为4.3步骤中创建的推理脚本,code_uri为4.3.1步骤中上传在s3的代码路径。
5. 批量转换(模型推理)
5.1 使用SageMaker Batch Transform
要获得整个数据集的推理结果,可以使用批处理变换。使用批处理转换,可以使用训练好的模型和数据集创建批处理转换作业,这些数据必须存储在Amazon S3中。
Amazon SageMaker将推理保存在创建批处理转换作业时指定的S3存储桶中。
批量转换管理获取推理所需的所有计算资源,并在批处理转换作业完成后将其删除。
5.1.1 输出结果整合输入id

指定model_name,实例的数量和机型

6. 使用Data Science SDK创建Step Functions Step
6.1 创建Glue Step,指定glue job name
下图中名为glue-demo-job-0223的Glue job是已经创建好的作业,其目的是定期生成需要推理的样本数据。

6.2 创建Batch Transform Step,指定job name和 model_name

6.3 串联上述的步骤
导入fields模块,更改attrs属性,本文中需要更改glue和SageMaker对应的Step
(1)把resource: “arn:aws:states:::glue:startJobRun.sync”
替换为resource: “arn:aws-cn:states:::glue:startJobRun.sync”
(2)把resource: “arn:aws:states:::sagemaker:createTransformJob.sync”
替换为resource:”arn:aws-cn:states:::sagemaker:createTransformJob.sync”



7. 运行上述workflow,指定workflow name
7.1 操作步骤
新建名为MyInferenceRoutine01的工作流

生成图示

创建和执行work flow,可以看到图示不同的颜色代表不同的状态


可以列出失败的events,正在执行的workflow和执行成功的workflow



正常执行完成后的图示:

7.2 生成的文件
最后在s3对应的文件夹下,可以看到生成的推理文件:

客户ID和对应的分数,可以看到,分数越低的客户流失的可能性会更高。

8. 总结
本文讨论的是使用Amazon Step Functions Data Science SDK,从数据ETL,到模型部署,再到批量推理,创建一个基于无服务器架构的工作流。对于业务端的数据科学家来讲,这些步骤都可以在Notebook中完成,而且可以通过Step Functions监控每个任务的运行状态和日志记录,最终实现整个流程的自动化,减少数据科学家的人工重复工作,提高生产开发效率。
本文涉及的示例代码下载链接:https://github.com/hlmiao/sagemaker/tree/main/sklearn-xgboost
9. 参考资料
[1] aws-step-functions-data-science-sdk-python
[2] AWS Step Functions Data Science SDK – Hello World
[3] Build a machine learning workflow using Step Functions and SageMaker
[4] Using the SageMaker Python SDK