亚马逊AWS官方博客
十分钟轻松使用 Scala 在 Apache Spark 部署深度学习模型
文章概要
深度学习在大数据领域上的应用日趋广泛,可是在Java/Scala上的部署方案却屈指可数。亚马逊开源项目团队另辟蹊径,利用DJL帮助用户部署深度学习应用在Spark上。只需10分钟,你就可以轻松部署TensorFlow,PyTorch,以及MXNet的模型在大数据生产环境中。
前言
Apache Spark是一个优秀的大数据处理工具。在机器学习领域,Spark可以用于对数据分类,预测需求以及进行个性化推荐。虽然Spark支持多种语言,但是大部分Spark任务设定及部署还是通过Scala来完成的。尽管如此,Scala并没有很好的支持深度学习平台。大部分的深度学习应用都部署在Python以及相关的框架之上,造成Scala开发者一个很头痛的问题:到底是全用Python写整套spark架构呢,还是说用Scala包装Python code在pipeline里面跑。这两个方案都会增加工作量和维护成本。而且,目前看来,PySpark在深度学习多进程的支持上性能不如Scala的多线程,导致许多深度学习应用速度都卡在了这里。
今天,我们会展示給用户一个新的解决方案,直接使用Scala调用 Deep Java Library (DJL)来实现深度学习应用部署。DJL将充分释放Spark强大的多线程处理性能,轻松提速2-5倍*现有的推理任务。DJL是一个为Spark量身定制的Java深度学习库。它不受限于引擎,用户可以轻松的将PyTorch, TensorFlow 以及MXNet的模型部署在Spark上。在本blog中,我们通过使用DJL来完成一个图片分类模型的部署任务,你也可以在这里参阅完整的代码。
图像分类:DJL + Spark
我们将使用Resnet50的预训练图像分类模型来部署一个推理任务。为了简化配置流程,我们只会在本地设置单一cluster与多个虚拟worker node的形式来进行推理。这是大致的工作流程:
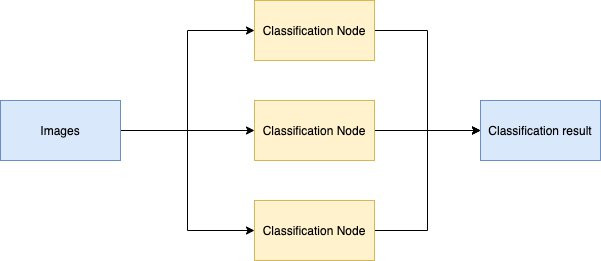
Spark会产生多个Executor来开启每个JVM进程,然后每一个处理任务(task) 都会发送給Executor执行。每一个Excutor拥有独立分配的内核以及内存。具体任务执行将会完全使用多线程来执行。在大数据处理中,这种架构可以帮助每个worker分配到合理的数据量。
第一步 建立一个Spark项目
通过使用sbt,我们可以轻松构建Scala项目。想了解更多关于sbt的介绍,请参考这里。可以通过下面的模版轻松设定:
项目使用MXNet作为默认引擎。你可以通过修改下面两行来更换使用PyTorch:
第二步 配置Spark
我们使用下面的配置在本地运行Spark:
MXNet多线程需要设置额外的 NaiveEngine 环境变量。如果使用PyTorch或者TensorFlow,这一行可以删除:
第三步 设置输入数据
输入数据是一个内含多张图片的文件夹。Spark会把这些图片读入然后分成不同的partition。每个partition会被分发给不同的Executor。那么我们配置一下图片分发的过程:
第四步 设置Spark job
在这一步,我们将创建一个Spark计算图用于进行模型读取以及推理。由于每一张图片推理都会在多线程下完成,我们需要在进行推理前设置一下Executor:
DJL引入了一个叫做ModelZoo的概念,通过Criteria来设置读取的模型。然后在partition内创建Predictor。在图片分类的过程中,我们从RDD中读取图片然后进行推理。这次使用的Resnet50模型是经过ImageNet数据集预训练的模型。
第五步 设置输出
当我们完成了Map数据的过程,我们需要让Master主节点收集数据:
运行上述两行代码会驱动Spark开启任务,输出的文件会保存在 output 文件夹. 请参阅 Scala example 来运行完整的代码。
如果你运行了示例代码,这个是输出的结果:
生产环境配置的建议
在这个例子里,我们用了RDD来进行任务分配,这个只是为了方便展示。如果考虑到性能因素,建议使用DataFrame来作为数据的载体。从Spark 3.0开始,Apache Spark为DataFrame提供了binary文件读取功能。这样在未来图片读取存储将会易如反掌。
工业环境中DJL在Spark上的应用
Amazon Retail System (ARS) 通过使用DJL在Spark上运行了数以百万的大规模数据流推理任务。这些推理的结果用于推断用户对于不同操作的倾向,比如是否会购买这个商品,或者是否会添加商品到购物车等等。数以千计的用户倾向类别可以帮助Amazon更好的推送相关的广告到用户的客户端与主页。ARS的深度学习模型使用了数以千计的特征应用在几亿用户上,输入的数据的总量达到了1000亿。在庞大的数据集下,由于使用了基于Scala的Spark处理平台,他们曾经一直在为没有好的解决方案而困扰。在使用了DJL之后,他们的深度学习任务轻松的集成在了Spark上。推理时间从过去的很多天变成了只需几小时。我们在之后将推出另一篇文章来深度解析ARS使用的深度学习模型,以及DJL在其中的应用。
关于DJL
DJL是亚马逊云服务在2019年re:Invent大会推出的专为Java开发者量身定制的深度学习框架,现已运行在亚马逊数以百万的推理任务中。如果要总结DJL的主要特色,那么就是如下三点:
- DJL不设限制于后端引擎:用户可以轻松的使用 MXNet, PyTorch, TensorFlow和fastText来在Java上做模型训练和推理。
- DJL的算子设计无限趋近于numpy:它的使用体验上和numpy基本是无缝的,切换引擎也不会造成结果改变。
- DJL优秀的内存管理以及效率机制:DJL拥有自己的资源回收机制,100个小时连续推理也不会内存溢出。
想了解更多,请参见下面几个链接:
https://github.com/awslabs/djl
也欢迎加入DJL的slack论坛。

*2-5倍基于PySpark在PyTorch Python CPU 与 Spark 在 DJL PyTorch Scala CPU上性能测试的结果。