亚马逊AWS官方博客
使用 Apache Parquet 格式的 VPC 流日志优化性能并降低网络分析成本
VPC 流日志可帮助您了解网络流量模式、识别安全问题、审计使用情况,以及诊断 AWS 上的网络连接问题。客户通常会将其 VPC 流日志直接路由到 Amazon S3,以便长期保留。然后,他们使用自定义格式转换应用程序以将这些文本文件转换为 Apache Parquet 格式,从而优化日志数据的分析处理,并降低日志存储成本。这种自定义格式转换步骤增加了 VPC 流日志流量分析的复杂性、获得洞察的时间和成本。以前,VPC 流日志一直是以 GZIP 格式的原始文本文件传输到 Amazon S3。
今天,我们很高兴地宣布推出一项新功能。该功能以 Apache Parquet 格式传输 VPC 流日志,从而能够更轻松、更快速、更经济实惠地分析存储在 Amazon S3 中的 VPC 流日志。您还可以使用按小时分区的 Hive 兼容的 S3 前缀将 VPC 流日志传输到 Amazon S3。
Apache Parquet 是一种开源文件格式,它以列式格式高效存储数据,提供不同的编码类型并支持谓词过滤。凭借良好的压缩比和高效的编码,存储在 Parquet 中的 VPC 流日志可以降低您的 Amazon S3 存储成本。使用分析框架查询以 Parquet 格式保存的流日志时,会跳过不相关的数据,这就减少了在 Amazon S3 上的读取次数,从而能够提高查询性能。为了减少 Amazon Athena 和 Amazon Redshift Spectrum 的查询运行时间和成本,Apache Parquet 是通常推荐的文件格式。
在这篇博客文章中,我们将探索这项新功能,了解它如何帮助您使用 Amazon Athena 对您的流日志运行性能查询。
创建 Parquet 文件格式的流日志
要利用此功能,只需使用 AWS 管理控制台、CLI 或 API 创建一个以 S3 为目标的新的 VPC 流日志订阅即可。在 AWS 管理控制台中,向 Amazon S3 创建新的 VPC 流日志订阅时,您可以选择以下一个或多个选项:
- 日志文件格式
- Hive 兼容的 S3 前缀
- 按时间划分的分区日志
现在,我们将探索这些选项中的每一项如何提高流日志的处理和存储效率
Apache Parquet 格式的文件
默认情况下,您的日志以文本格式传送。选择“Parquet”作为 Log File Format(日志文件格式)。这会以 Apache Parquet 格式将您的 VPC 流日志传输到 S3。

注意:
- 无法将现有流日志更改为以 Parquet 格式传输日志。您需要使用“Parquet”作为日志文件格式创建新的 VPC 流日志订阅。
- 在聚合流数据包时考虑使用更高的最大聚合间隔(10 分钟),以确保 Amazon S3 上的 Parquet 文件更大。
- 请参阅 Amazon CloudWatch Logs 定价页面,了解以 Apache Parquet 格式传输 VPC 流日志的定价。
Hive 兼容的分区
分区是一种组织数据以提高查询引擎效率的技术。与查询筛选器中经常使用的列对齐的分区可以显著缩短查询响应时间。现在,您可以指定以 Hive 兼容的格式组织您的流日志。这样,您就可以在 Amazon Athena 中运行 MSCK REPAIR 命令,以便在新分区传输到 Amazon S3 中时快速轻松地添加新分区。只需在 Hive 兼容的 S3 前缀下选择“Enable”(启用)即可进行设置。这会通过以下路径将流日志传送到 S3:
每小时分区
您还可以通过添加每小时分区,更精细地组织您的流日志。如果您经常需要以特定时间范围作为谓词查询大量日志,应启用此功能。仅在特定时段查询日志会减少扫描的数据,这意味着使用 Amazon Athena 和 Amazon Redshift Spectrum 等引擎可以降低每次查询的成本。
您也可以使用 create-flow-logs 中的 –destination-options 参数,通过 API 或 CLI 完成以上所有操作:
以下是存放在每小时存储桶中的流日志文件示例。默认情况下,Parquet 格式的流日志使用 Gzip 格式压缩。与其他压缩格式相比,此格式的压缩比最高。
使用 Amazon Athena 查询
您可以使用 AWS 管理控制台中的 Amazon Athena 集成 VPC 流日志,以在 S3 中自动执行 Athena 设置所需的 VPC 流日志查询。此集成现已扩展,以支持这些向 S3 传输新流日志的选项。现在,让我们对纯文本和 Apache Parquet 格式的 VPC 流日志运行 Amazon Athena 查询。
我们首先创建一个指向 Parquet 格式流日志的外部表。
请注意,此功能支持指定 Parquet 的本机数据类型的流日志字段。这样您就无需在查询流量日志时投射字段。
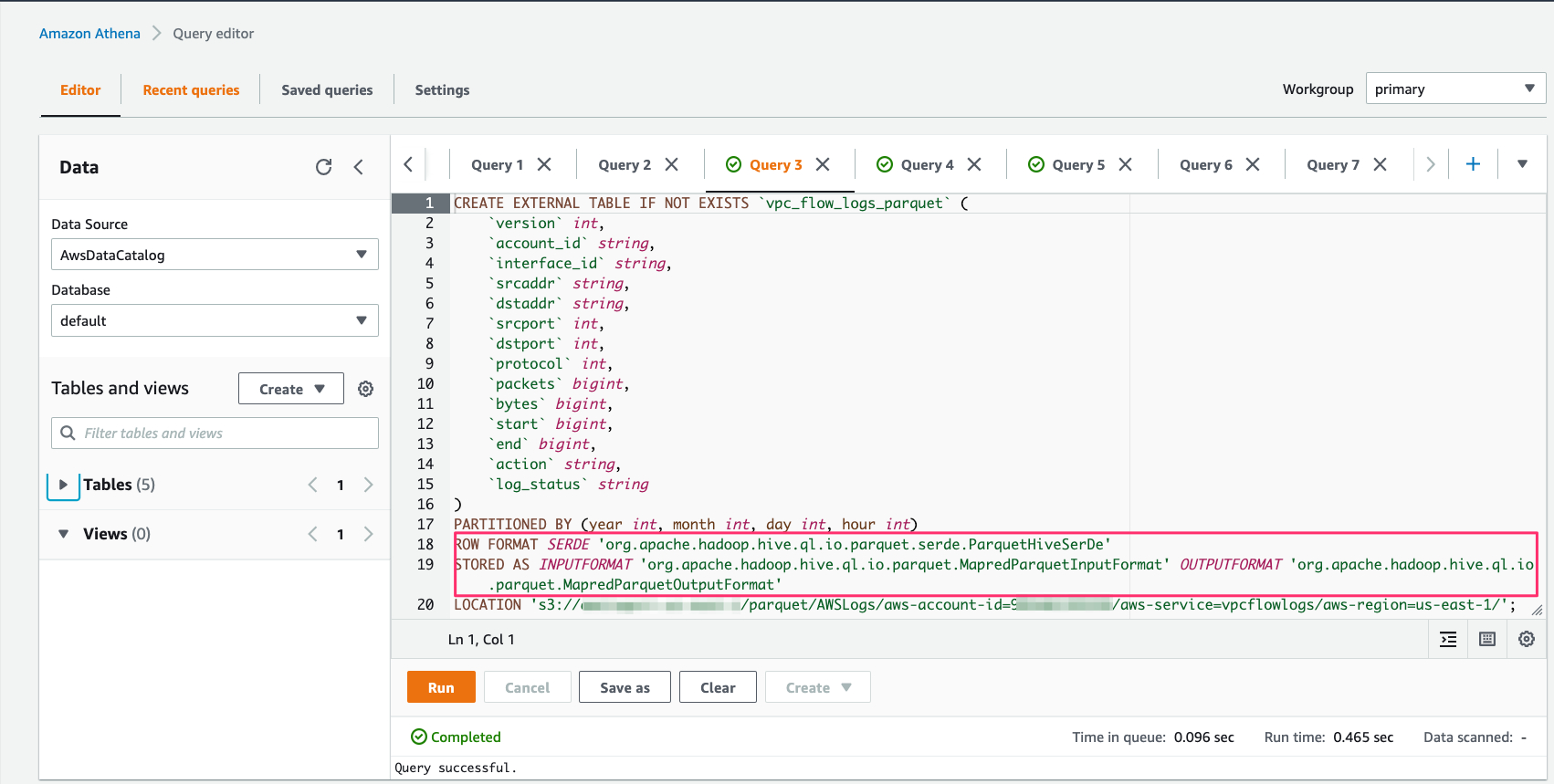
然后运行 MSCK REPAIR TABLE
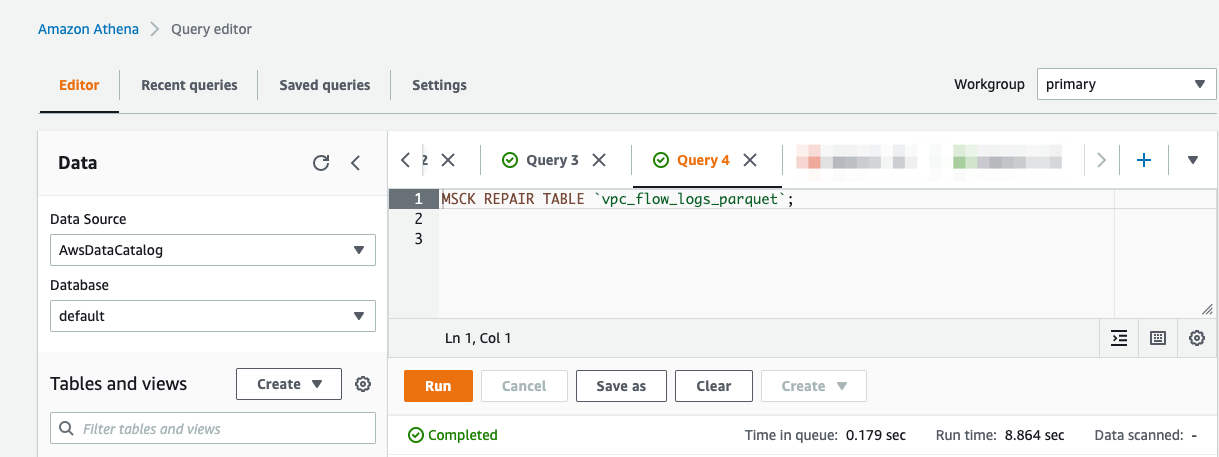
让我们对这些基于 Parquet 的流日志运行示例查询。

现在,让我们为以纯文本形式传输的流日志创建一个表。

我们使用 ALTER TABLE 语句在 Amazon Athena 中添加分区。

运行一个简单的流日志查询,并记下运行查询所用的时间。

请注意,对以 Parquet 格式的流日志运行 Amazon Athena 查询的运行时间(1.16 秒)远低于对纯文本格式的流日志运行此查询的时间(2.51 秒)。Amazon Athena 调优技巧博客提供了基准,这些基准进一步描述了在粒度分区中以 Parquet 格式持久存放数据所带来的成本节约和性能改进。
总结
您可以通过三个新选项将 VPC 流日志传输到 S3:
- 以 Apache Parquet 格式的文件
- 使用 Hive 兼容的 S3 前缀,以及
- 以按小时分区的文件
这些传输选项使存储 Amazon VPC 流日志并对其运行分析变得更快速、更轻松,并且更具成本效益。要了解更多信息,请访问相关文档。我们希望您能试用一下此功能,并与我们分享您的体验。请将反馈发送给 Amazon EC2 的 AWS 论坛,或通过您的常用 AWS Support 联系人发送反馈。
关于作者
Radhika Ravirala 是 Amazon Web Services 的首席流媒体架构师,她帮助客户使用 Amazon Kinesis 和 Amazon MSK 制作分布式流媒体应用程序。在空闲时间,她喜欢带着她的狗一起长时间散步,玩棋类游戏和广泛阅读。
Vaibhav Katkade 是 Amazon VPC 团队的高级产品经理。他对网络安全和云网络运营领域很感兴趣。工作之余,他喜欢做饭和户外活动。