互联网行业每天都有大量的日志生成,需要在固定时间段对数据进行ETL工作。用户常规的做法是启动一组长期运行的EMR集群,配置远程提交任务的服务器,结合自身的任务调度系统定期提交任务,但集群执行完成任务之后会闲置,造成不必要的开销。另一种方法是在需要执行任务的时候启动集群,任务完成之后关闭集群,但因为每次启动集群后,主节点与核心节点的IP都会发生分变化,导致每次都需要重新配置提交任务的服务器,造成额外的工作负担。本文介绍了一种通过Apache Airflow任务调度系统动态启停Amazon EMR集群的方法,并通过EMR内置的Livy远程提交作业,这样可以节省大量的成本并且无需进行过多的额外配置。
1. 相关技术介绍
在开始之前,请先对以下技术进行简单了解。
1.1 Apache Airflow
Apache Airflow是一款开源的任务调度系统,用户通过创建DAG(有向无环图)来定义任务的流程,图中的每个节点就是需要执行的任务,不同DAG之间的任务可以相互依赖。通过Airflow我们可以定时执行脚本,并且它提供了web界面供用户可视化地查看任务执行情况。
1.2 Apache Livy
Apache Livy是Hadoop生态圈中提供远程提交任务功能的应用程序。它以Rest API的方式提供了Session与Batches两种集群执行任务的方法。Session指的是将集群需要执行的代码写在对Livy请求中,目前支持spark、pyspark、sparkr与sql等四种方式与集群交互。Bathches指的是将代码存放在指定位置,在请求中提供路径,让集群执行代码。例如将jar包存放在S3上,在请求Livy的时候提供jar包的路径,从而让集群直接执行jar包,好处是无需在集群上配置执行代码所需的依赖。
2. 演练
通过本文示例,我将向您展示如何实现以下方案:
基于开源调度工具Airflow编排提交Spark Jobs到EMR做批处理,Job开始之前启动EMR集群,对集群节点采用Spot实例,所有Job结束后关闭EMR集群。
2.1 流程架构图与过程简介

(1)在一台EC2上配置Airflow;
(2)定义Airflow工作流,其中包含创建集群,Spark任务步骤与终止集群等任务;
(3)向Livy提交任务;
(4)EMR从S3中读取数据,对数据进行处理完成之后重新写入S3;
(5)工作完成,终止集群。
2.2 前提条件
(1)本文示例所使用的区域us-east-1;
(2)在该区域创建一台EC2,并确保与EC2绑定的IAM Role有EMR集群的Full Access;
(3)拥有创建EMR集群所需的默认角色:EMR_DefaultRole与EMR_EC2_DefaultRole;
(4)创建S3桶,下载jar包spark-examples_2.11-2.4.4和数据集emrdata.txt,并上传至s3。
2.3 实现过程
2.3.1 在EC2上配置Airflow
(1)登陆EC2,安装Airflow已经相关依赖
sudo yum update -y
sudo yum install -y python-pip gcc mysql-devel python-devel mysql
sudo pip install mysql-python
sudo yum install -y python3
sudo pip3 install boto3
sudo pip3 install requests
# 安装Airflow
sudo pip install apache-airflow
sudo pip install 'apache-airflow[celery]'
airflow initdb
(2)创建RDS for Mysql数据库供Airflow使用,对数据库性能要求不高,因此使用默认配置即可

(3)更改airflow.cfg配置文件,并测试是否能打开Airflow的web页面
cd airflow
vim airflow.cfg
# 找到sql_alchemy_conn等参数所在位置,替换为创建的数据库信息
sql_alchemy_conn = mysql://admin:12345678@database-for-airflow.cdtwa5j4xten.us-east-1.rds.amazonaws.com/airflowdb
# Exit vim, Update Airflow Database
airflow initdb
# 配置celery相关参数
vim airflow.cfg
# 找到executor位置,将执行器设置为celery,可保证不相互依赖的任务可以并行执行
executor = CeleryExecutor
# 找到broker_url与result_backend参数的位置
broker_url = sqla+mysql://admin:12345678@database-for-airflow.cdtwa5j4xten.us-east-1.rds.amazonaws.com:3306/airflowdb
result_backend = db+mysql://admin:12345678@database-for-airflow.cdtwa5j4xten.us-east-1.rds.amazonaws.com:3306/airflowdb
# 开启airflow的webserver,在网页上输入EC2的DNS,查看是否能打开网页(注意打开安全组,并且如果本地连上的是公司的vpn,可能会出现无法打开网页的情况)
airflow webserver -p 8080 &
# 启动worker
airflow worker &
# 启动flower,可对worker中的任务进行可视化(要看到网页注意打开5555端口)
airflow flower &
2.3.2 定义工作流
现定义如下两个Airflow的DAG:
dag_transform_calpi

(1)create_emr_cluster:创建EMR集群;
# -*- coding: UTF-8 -*-
import boto3
import time
emr_client = boto3.client('emr', region_name='us-east-1')
# 定义集群名称,集群名称不要与当前运行的集群重名
name = 'emr-cluster'
# 定义instance,可自定义实例的数量与类型
intances = {
'InstanceGroups': [
{
'Market': 'SPOT',
'InstanceRole': 'MASTER',
'InstanceType': 'm4.xlarge',
'InstanceCount': 1,
},
{
'Market': 'SPOT',
'InstanceRole': 'CORE',
'InstanceType': 'm4.xlarge',
'InstanceCount': 2,
}
],
'KeepJobFlowAliveWhenNoSteps': True
}
# 定义集群中的应用
applications = [
{
'Name': 'Hadoop'
},
{
'Name': 'Pig'
},
{
'Name': 'Livy'
},
{
'Name': 'Hive'
},
{
'Name': 'Hue'
},
{
'Name': 'Spark'
}
]
if __name__ == '__main__':
# 创建emr集群
emr_client.run_job_flow(
Name=name, ReleaseLabel='emr-5.12.0', Instances=intances, Applications=applications,
JobFlowRole='EMR_EC2_DefaultRole', ServiceRole='EMR_DefaultRole')
# 持续发送请求,直到创建的集群状态处于Waiting为止
flag = True
while flag:
time.sleep(20)
r = emr_client.list_clusters(ClusterStates=['WAITING'])
for i in r['Clusters']:
if i['Name'] == name:
flag = False
(2)create_livy_session:创建Livy会话;
# -*- coding: UTF-8 -*-
import requests
import json
import pprint
import boto3
# 获取集群的DNS,其中name为你的集群名称
name = 'emr-cluster'
emr_client = boto3.client('emr', region_name='us-east-1')
r = emr_client.list_clusters(ClusterStates=['WAITING'])
for i in r['Clusters']:
if i['Name'] == name:
cluster_id = i['Id']
r = emr_client.describe_cluster(ClusterId=cluster_id)
emr_dns = r['Cluster']['MasterPublicDnsName']
# livy_host为配置在emr集群上livy的url,无需修改代码
livy_host = 'http://' + emr_dns + ':8998'
data = {'kind': 'pyspark'}
headers = {'Content-Type': 'application/json'}
r = requests.post(livy_host + '/sessions',
data=json.dumps(data), headers=headers)
pprint.pprint(r.json())
(3)sleep:等待会话创建完成;
(4)calpi:以batches的方式执行spark任务计算pi值;
# -*- coding: UTF-8 -*-
import requests
import json
import textwrap
import pprint
import boto3
# 获取执行jar包任务的livy batch的url,其中name为你的集群名称
name = 'emr-cluster'
emr_client = boto3.client('emr', region_name='us-east-1')
r = emr_client.list_clusters(ClusterStates=['WAITING'])
for i in r['Clusters']:
if i['Name'] == name:
cluster_id = i['Id']
r = emr_client.describe_cluster(ClusterId=cluster_id)
emr_dns = r['Cluster']['MasterPublicDnsName']
batch_url = 'http://' + emr_dns + ':8998/batches'
headers = {'Content-Type': 'application/json'}
# 提交任务
data = {"file": "s3://xiaoyj/emr/spark-examples_2.11-2.4.4.jar",
"className": "org.apache.spark.examples.SparkPi"}
r = requests.post(batch_url, data=json.dumps(data), headers=headers)
pprint.pprint(r.json())
(5)query_completed:外部任务,依赖于第二个DAG(dag_query),即等待查询完成之后,执行下一个任务;
(6)终止集群。
# -*- coding: UTF-8 -*-
import boto3
import time
# 终止集群,其中name为你的集群名称
name = 'emr-cluster'
emr_client = boto3.client('emr', region_name='us-east-1')
flag = True
while flag:
time.sleep(120)
r = emr_client.list_clusters(ClusterStates=['WAITING'])
for i in r['Clusters']:
if i['Name'] == name:
emr_client.terminate_job_flows(JobFlowIds=[i['Id']])
flag = False
dag_query

(1)sleep_completed:外部任务,依赖于第一个DAG(dag_transform_calpi),即等待Livy会话执行下一个任务;
(2)transform:对之前上传到S3上的文本文件进行聚合、转换;
# -*- coding: UTF-8 -*-
import requests
import json
import textwrap
import pprint
import boto3
# 获取提交任务的livy_url,其中name为你的集群名称
name = 'emr-cluster'
emr_client = boto3.client('emr', region_name='us-east-1')
r = emr_client.list_clusters(ClusterStates=['WAITING'])
for i in r['Clusters']:
if i['Name'] == name:
cluster_id = i['Id']
r = emr_client.describe_cluster(ClusterId=cluster_id)
emr_dns = r['Cluster']['MasterPublicDnsName']
livy_url = 'http://' + emr_dns + ':8998/sessions/0/statements'
headers = {'Content-Type': 'application/json'}
# 提交任务,data中的code为在emr中执行的代码,对s3中的文件进行转化操作,完成后将结果存放回s3作为中间结果
data = {
'code': textwrap.dedent("""
import json
sc._jsc.hadoopConfiguration().set('fs.s3a.endpoint', 's3-us-east-2.amazonaws.com')
text_file = sc.textFile("s3a://xiaoyj/emr/emrdata.txt")
text_file = text_file.map(lambda x: x.split('::'))
text_file = text_file.map(lambda x: (int(x[0]), x[1:]))
text_file = text_file.groupByKey().map(lambda x: (x[0], list(x[1])))
text_file = text_file.sortByKey()
text_file = text_file.map(lambda x: {x[0]: x[1]})
text_file = text_file.map(lambda x: json.dumps(x))
text_file.coalesce(1).saveAsTextFile("s3a://xiaoyj/emr/middle_result")
print("Transform Complete!")
""")
}
r = requests.post(livy_url, data=json.dumps(data), headers=headers)
pprint.pprint(r.json())
(3)check_s3:检查S3中是否有上一步生成的中间结果;
# -*- coding: UTF-8 -*-
import boto3
import time
# 轮询s3,确认transform任务是否执行完成(即s3中是否有middle_result文件生成),name为你的s3桶名称
name = 'xiaoyj'
s3_client = boto3.client('s3', region_name='us-east-1')
flag = True
while flag:
time.sleep(60)
r = s3_client.list_objects(Bucket=name)
for i in r['Contents']:
if i['Key'] == 'emr/middle_result/part-00000':
flag = False
(4)query:对上一步生成的中间结果进行查询。
# -*- coding: UTF-8 -*-
import requests
import json
import textwrap
import pprint
import boto3
# 获取提交任务的livy_url,其中name为你的集群名称
name = 'emr-cluster'
emr_client = boto3.client('emr', region_name='us-east-1')
r = emr_client.list_clusters(ClusterStates=['WAITING'])
for i in r['Clusters']:
if i['Name'] == name:
cluster_id = i['Id']
r = emr_client.describe_cluster(ClusterId=cluster_id)
emr_dns = r['Cluster']['MasterPublicDnsName']
livy_url = 'http://' + emr_dns + ':8998/sessions/0/statements'
headers = {'Content-Type': 'application/json'}
# 提交任务,data中的code为在emr中执行的代码,对s3中的文件进行转化操作,完成后将结果存放回s3作为中间结果
data = {
'code': textwrap.dedent("""
import json
from pyspark.sql import HiveContext, Row
hiveCtx = HiveContext(sc)
input = hiveCtx.read.json("s3a://xiaoyj/emr/middle_result/part-00000")
input.registe rTempTable("tbn")
result = hiveCtx.sql("SELECT size(`9`) from tbn")
result = result.rdd.map(lambda row: row[0])
result.coalesce(1).saveAsTextFile("s3a://xiaoyj/emr/result")
print("Search Complete!")
""")
}
r = requests.post(livy_url, data=json.dumps(data), headers=headers)
pprint.pprint(r.json())
2.3.3 创建Airflow工作流
(1)在airflow文件夹中创建dags文件夹,并进入到文件夹中;
(2)定义工作流(注意开头的# — coding: UTF-8 –不要省略,并且bash_command需替换为自己任务所在的路径);
vim dag_transform_calpi.py
# -*- coding: UTF-8 -*-
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime, timedelta
from airflow.sensors.external_task_sensor import ExternalTaskSensor
default_args = {
'owner': 'Airflow',
'depends_on_past': False,
'start_date': datetime.now().replace(microsecond=0),
'email': ['756044579@qq.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 0,
'retry_delay': timedelta(minutes=5),
# 'queue': 'bash_queue',
# 'pool': 'backfill',
# 'priority_weight': 10,
# 'end_date': datetime(2016, 1, 1),
}
dag = DAG('dag_transform_calpi', default_args=default_args,
schedule_interval=timedelta(days=1))
# 创建emr集群
t0 = BashOperator(
task_id='create_emr_cluster',
bash_command='python3 /Users/xiaoyj/Desktop/emr_poc/create_emr_cluster.py',
dag=dag)
# 创建livy的会话
t1 = BashOperator(
task_id='create_livy_session',
bash_command='python3 /Users/xiaoyj/Desktop/emr_poc/create_session.py',
dag=dag)
# 等待会话创建完成
t2 = BashOperator(
task_id='sleep',
bash_command='sleep 20',
dag=dag)
# 计算pi值
t3 = BashOperator(
task_id='calpi',
bash_command='python3 /Users/xiaoyj/Desktop/emr_poc/calpi.py',
dag=dag)
# 终止emr集群
t4 = BashOperator(
task_id='terminate_cluster',
bash_command='python3 /Users/xiaoyj/Desktop/emr_poc/terminate_cluster.py',
dag=dag)
# dag_query中的spark sql任务
external_task = ExternalTaskSensor(
external_task_id='query', task_id='query_completed', external_dag_id='dag_query', dag=dag)
# 定义airflow的有向无环图
t0 >> t1
t1 >> t2
t2 >> t3
external_task >> t4
vim dag_query.py
# -*- coding: UTF-8 -*-
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime, timedelta
from airflow.sensors.external_task_sensor import ExternalTaskSensor
default_args = {
'owner': 'Airflow',
'depends_on_past': False,
'start_date': datetime.now().replace(microsecond=0),
'email': ['756044579@qq.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 0,
'retry_delay': timedelta(minutes=5),
# 'queue': 'bash_queue',
# 'pool': 'backfill',
# 'priority_weight': 10,
# 'end_date': datetime(2016, 1, 1),
}
dag = DAG('dag_query', default_args=default_args,
schedule_interval=timedelta(days=1))
# 对s3上的文本文件进行转化操作
t0 = BashOperator(
task_id='transform',
bash_command='python3 /Users/xiaoyj/Desktop/emr_poc/transform.py',
dag=dag)
# 轮询s3,查看中间结果是否生成
t1 = BashOperator(
task_id='check_s3',
bash_command='python3 /Users/xiaoyj/Desktop/emr_poc/check_s3.py',
dag=dag)
# spark sql任务
t2 = BashOperator(
task_id='query',
bash_command='python3 /Users/xiaoyj/Desktop/emr_poc/query.py',
dag=dag)
# dag_transform_calpi中的sleep任务
external_task = ExternalTaskSensor(
external_task_id='sleep', task_id='sleep_completed', external_dag_id='dag_transform_calpi', dag=dag)
external_task >> t0
t0 >> t1
t1 >> t2
(3)重制Airflow数据库;
(4)启动Airflow,-s为当前日期,-e是结束日期,均设置为当日的日期(若工作流执行失败并想重头开始执行工作,需要先执行airflow resetdb)
airflow backfill dag_transform_calpi -s 2019-12-02 -e 2019-12-02 & airflow backfill dag_query -s 2019-12-02 -e 2019-12-02
3. 展示
(1)打开AWS EMR控制台,可以观察到集群正在创建;

(2)待集群创建完成后,获取主节点DNS,并打开网页;

(3)观察到Livy上并行提交了两个任务分别是spark对文本的tansform操作和jar包计算pi值的任务;

(4)pi值计算完成;

(5)待Transform任务完成,Spark SQL任务开始执行;

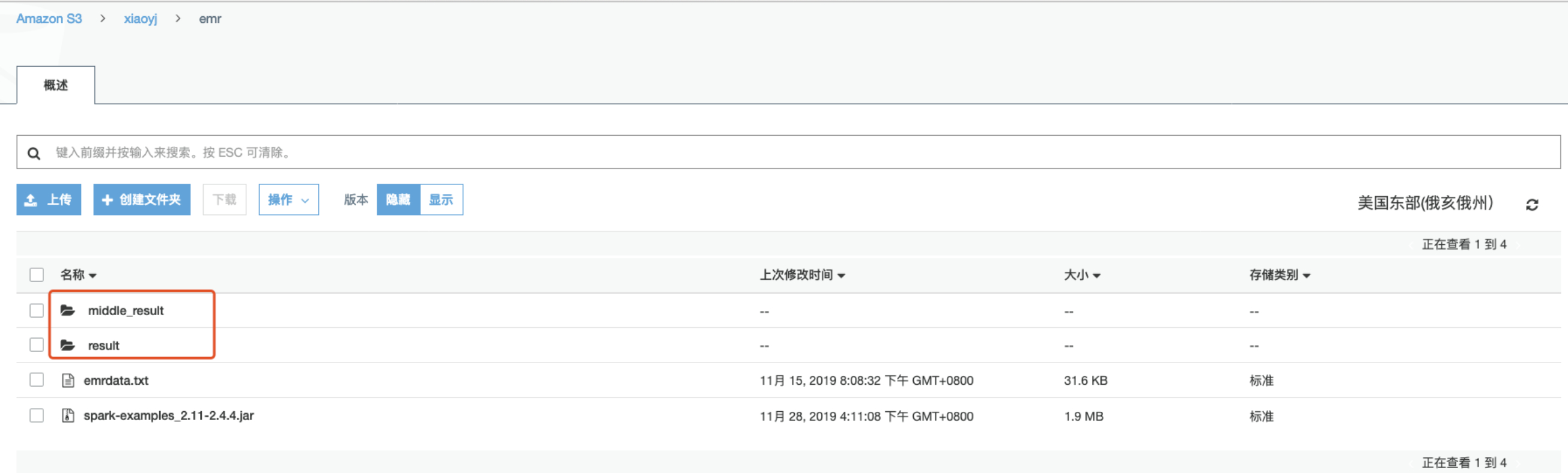
(6)执行完成后可以在s3上可以看到Transform任务生成的middle result和Spark SQL任务生成的最终结果;

(7)下载middle_result中的文件,可以看到聚合结果;

(8)下载result中的文件,可以查看到最终结果(统计编号为9的列表中包含53组数据,-1表示其他json文件没有编号为9的;

(9)任务执行完毕,发现集群自动终止;

(10)再查看远程服务器上Airflow的web界面,发现两个dag已经执行完毕。

4. 总结
本文展现了如何使用Airflow启动EMR集群,并通过Livy远程提交任务,在任务完成后终止集群。成本节省主要体现在两个方面:1)每天在需要执行ETL工作时启动集群,任务执行完成后终止集群,因此不会出现空闲的集群;2)EMR可以配合Spot实例使用,从而节省更多的成本。另一个好处是使用Livy无需额外配置远程提交任务的服务器,并且EMR集成了Livy的一键安装,造成了极大的方便。
本篇作者
本篇作者