亚马逊AWS官方博客
使用 Amazon SageMaker Hugging Face 估计器和模型并行库微调 GPT-J
在这篇文章中,我们将介绍使用 Amazon SageMaker 分布式模型并行库训练大型语言模型(LLM)的指南和最佳实践,以减少训练时间和成本。您将学习如何轻松地在 SageMaker 上训练 60 亿个参数的 GPT-J 模型。最后,我们将分享 SageMaker 分布式模型并行性的主要特征,这些特征有助于加快训练时间。
变换器神经网络
变换器神经网络是一种流行的深度学习架构,用于解决序列到序列的任务。该架构使用 attention 作为学习机制,以达到接近人类水平的表现。与前几代自然语言处理(NLP)模型相比,该架构的其他一些有用特性包括分布、扩展和预训练能力。在处理搜索、聊天机器人等文本数据时,基于变换器的模型可应用于不同的使用案例。变换器使用预训练的概念从大型数据集中获取情报。预训练的变换器可以按原样使用,也可以对数据集进行微调,这些数据集可以小得多,并且特定于您的业务。
SageMaker 上的 Hugging Face
Hugging Face 是一家开发一些最流行的开源库的公司,提供基于变换器架构的最先进的 NLP 技术。Hugging Face 的变换器、分词器和数据集库提供了 API 和工具,可使用多种语言的预训练模型进行下载和预测。SageMaker 可让您使用 SageMaker SDK 中的 Hugging Face 估计器,直接从 Hugging Face Model Hub 使用 Hugging Face 模型进行训练、微调和运行推理。这种集成使得在特定领域的使用案例中自定义 Hugging Face 模型变得更加容易。在后台,SageMaker SDK 使用 AWS 深度学习容器(DLC,Deep Learning Container),这些容器是一组预构建的 Docker 映像,用于训练和处理 SageMaker 提供的模型。DLC 由 AWS 和 Hugging Face 合作开发。这种集成还提供了 Hugging Face 变换器 SDK 与 SageMaker 分布式训练库之间的集成,使您能够在 GPU 集群上扩展训练作业。
SageMaker 分布式模型并行库概述
模型并行是一种分布式训练策略,该策略将深度学习模型划分到实例内部或实例之间的众多设备上。具有更多层和参数的深度学习(DL,Deep Learning)模型在计算机视觉和 NLP 等复杂任务中表现更好。然而,单个 GPU 内存中可存储的最大模型大小是有限的。在训练 DL 模型时,GPU 内存限制可能会在以下方面成为瓶颈:
- 限制可以训练的模型的大小,因为模型的内存占用量与参数的数量成正比
- 通过限制训练期间每个 GPU 的批量大小,降低 GPU 利用率和训练效率
SageMaker 包括分布式模型并行库,有助于在多个计算节点上有效地分发和训练 DL 模型,克服了在单个 GPU 上训练模型的相关限制。此外,该库还允许您利用 EFA 支持的设备获得最佳分布式训练,从而通过低延迟、高吞吐量和操作系统旁路来提高节点间通信性能。
由于像 GPT-J 这样的大型模型具有数十亿个参数,其 GPU 内存占用量超过了单个芯片,因此必须在多个 GPU 之间对这种模型进行分区。SageMaker 模型并行(SMP)库支持在多个 GPU 之间自动对模型进行分区。使用 SageMaker 模型并行功能,SageMaker 会代表您运行初始分析作业,以分析模型的计算和内存需求。然后,这些信息用于决定如何在 GPU 之间对模型进行分区,以最大限度地提高目标,如最大限度地提高速度或最大限度地减少内存占用量。
这项功能还支持可选的管道运行调度,以最大限度地提高可用 GPU 的总体利用率。前向传递期间的激活传播和后向传递期间的梯度传播需要顺序计算,这限制了 GPU 的使用量。SageMaker 通过将小批次拆分为微批次,以便在不同的 GPU 上并行处理,从而利用管道运行调度克服了顺序计算限制。SageMaker 模型并行支持两种管道运行模式:
- 简单管道 – 该模式下,每个微批次的前向传递结束后,才开始后向传递。
- 交错管道 – 该模式下,微批次的后向运行尽可能优先。这样可以更快地释放用于激活的内存,从而更有效地利用内存。
张量并行技术
各个层或 nn.Modules 利用张量并行技术划分到各个设备上,以便同时运行。下图是一个最简单的例子,说明该库如何将一个模型分为四层,以实现双向张量并行性("tensor_parallel_degree": 2)。每个模型副本的层被一分为二(分成两半),并分布在两个 GPU 之间。本例中的数据并行度为八,因为模型并行配置还包括 "pipeline_parallel_degree": 1 和 "ddp": True。该库管理张量分布式模型各副本之间的通信。
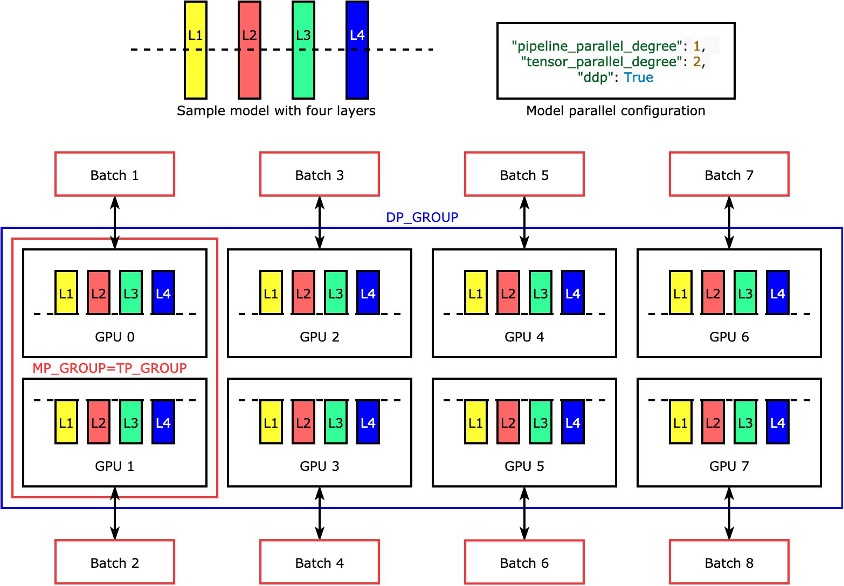
这一功能的好处是,您可以选择要将张量并行应用于哪些层或哪些层的子集。要深入了解 PyTorch 的张量并行性和其他节省内存的功能,以及如何设置管道和张量并行性的组合,请参阅 PyTorch 的 SageMaker 模型并行库的扩展功能。
SageMaker 分片数据并行性
分片数据并行性是一种节省内存的分布式训练技术,可以将模型的训练状态(模型参数、梯度和优化器状态)拆分到数据并行组中的多个 GPU 上。
将训练作业扩展到大型 GPU 集群时,可以通过在多个 GPU 上分片训练状态来减少模型的每 GPU 内存占用量。这样做有两个好处:一是可以适应更大的模型,否则标准数据并行性会耗尽内存;二是可以利用释放的 GPU 内存增加批次大小。
标准数据并行技术在数据并行组中的 GPU 之间复制训练状态,并根据 AllReduce 操作执行梯度聚合。实际上,分片数据并行在通信开销和 GPU 内存效率之间进行了权衡。使用分片数据并行会增加通信成本,但每个 GPU 的内存占用量(不包括激活导致的内存使用量)会被分片数据并行度除以,因此 GPU 集群可以容纳更大的模型。
SageMaker 通过 MiCS 实现分片数据并行性。有关更多信息,请参阅 AWS 上巨型模型训练的近线性扩展。
有关如何在训练作业中应用分片数据并行性的更多详细信息,请参阅分片数据并行性。
使用 SageMaker 模型并行库
SageMaker 模型并行库附带 SageMaker Python SDK。您需要安装 SageMaker Python SDK 才能使用该库,该工具包已经安装在 SageMaker notebook 内核上。要使 PyTorch 训练脚本利用 SMP 库的功能,需要进行以下更改:
- 首先使用
smp.init()调用导入和初始化smp库。 - 初始化后,使用
smp.DistributedModel封装器封装模型,并使用返回的DistributedModel对象代替用户模型。 - 对于优化器状态,在模型优化器周围使用
smp.DistributedOptimizer封装器,使smp能够保存和加载优化器状态。前向和后向传递逻辑可以抽象为一个单独的函数,并向该函数添加smp.step装饰器。从本质上讲,前向传递和后向传播需要在函数内部运行,上面放置smp.step装饰器。这样,smp就能在启动训练作业时,将输入函数的张量拆分为指定数量的微批次。 - 接下来,我们可以使用
torch.cuda.set_device然后调用.to()API,将输入张量移动到当前进程使用的 GPU。 - 最后,对于后向传播,我们替换了
torch.Tensor.backward和torch.autograd.backward。
请参阅以下代码:
SageMaker 模型并行库的张量并行为以下 Hugging Face 变换器模型提供了开箱即用的支持:
- GPT-2、BERT 和 RoBERTa(在 SMP 库 v1.7.0 及更高版本中可用)
- GPT-J(在 SMP 库 v1.8.0 及更高版本中可用)
- GPT-Neo(在 SMP 库 v1.10.0 及更高版本中可用)
使用 SMP 库进行性能调整的最佳实践
在训练大型模型时,请考虑以下步骤,以便模型能以合理的批次大小在 GPU 内存中运行:
- 为了提高性能,建议使用 GPU 内存更高、带宽互连更高的实例,如 p4d 和 p4de 实例。
- 在大多数情况下,可以启用优化器状态分片,当模型有多个副本(已启用数据并行性)时,优化器状态分片会很有用。可以通过在
modelparallel配置中设置"shard_optimizer_state": True来开启优化器状态分片。 - 使用激活检查点,这是一种通过清除某些层的激活并在模型中选定模块的后向传递期间重新计算来减少内存使用量的技术。
- 使用激活卸载,这是一项可以进一步减少内存使用量的附加功能。要使用激活卸载,请在
modelparallel配置中设置"offload_activations": True。当激活检查点和管道并行功能处于开启状态且微批次数大于一时使用。 - 启用张量并行并增加并行度,其中并行度是 2 的幂。通常,出于性能考虑,张量并行仅限于一个节点内。
我们在 SageMaker 上利用 SMP 库进行了多次实验,以优化 GPT-J 的训练和调整。我们成功地将 SageMaker 上 GPT-J 的训练时间从 58 分钟缩短到了不到 10 分钟 – 单次训练时间缩短了六倍。从 Amazon Simple Storage Service(Amazon S3)下载初始化、模型和数据集的时间不到 1 分钟,使用 GPU 作为跟踪设备进行跟踪和自动分区的时间不到 1 分钟,在一个 ml.p4d.24xlarge 实例上使用张量并行、FP16 精度和 SageMaker Hugging Face 估计器进行训练的时间为 8 分钟。
作为最佳实践,在 SageMaker 上训练 GPT-J 时,为了缩短训练时间,我们的建议如下:
- 将预训练模型存储在 Amazon S3 上
- 使用 FP16 精度
- 使用 GPU 作为跟踪设备
- 使用自动分区、激活检查点和优化器状态分片:
auto_partition: Trueshard_optimizer_state: True
- 使用张量并行
- 使用具有多个 GPU 的 SageMaker 训练实例,如 ml.p3.16xlarge、ml.p3dn.24xlarge、ml.g5.48xlarge、ml.p4d.24xlarge 或 ml.p4de.24xlarge。
利用 SMP 库在 SageMaker 上训练和调整 GPT-J 模型
Amazon SageMaker Examples 公共存储库中提供了有效的分步代码示例。导航到 training/distributed_training/pytorch/model_parallel/gpt-j 文件夹。选择 gpt-j 文件夹,并打开 train_gptj_smp_tensor_parallel_notebook.jpynb Jupyter notebook(用于张量并行示例)和 train_gptj_smp_notebook.ipynb(用于管道并行示例)。您可以在我们的 Amazon SageMaker 上的生成式人工智能研讨会上找到代码演练。
本 notebook 将引导您了解如何使用 SageMaker 模型并行度库提供的张量并行功能。您将学习如何在 GLUE sst2 数据集上使用张量并行和管道并行对 GPT-J 模型进行 FP16 训练。
小结
SageMaker 模型并行库提供了多种功能。您可以降低成本,加快在 SageMaker 上训练 LLM 的速度。您还可以在 Amazon SageMaker Examples 公共存储库中学习和运行 BERT、GPT-2 和 GPT-J 的示例代码。要详细了解使用 SMP 库训练 LLMS 的 AWS 最佳实践,请参阅以下资源:
要了解我们的一位客户如何在 SageMaker 上实现低延迟 GPT-J 推理,请参阅 Mantium 如何在 Amazon SageMaker 上利用 DeepSpeed 实现低延迟 GPT-J 推理。
如果您希望缩短 LLM 的上市时间并降低成本,SageMaker 可以提供协助。让我们知道您构建了什么!
关于作者
 Zmnako Awrahman 博士是 Amazon Web Services 全球能力中心的实践经理、机器学习专家和机器学习技术领域社区(TFC)成员。他协助客户利用云的力量,通过数据分析和机器学习从数据中提取价值。
Zmnako Awrahman 博士是 Amazon Web Services 全球能力中心的实践经理、机器学习专家和机器学习技术领域社区(TFC)成员。他协助客户利用云的力量,通过数据分析和机器学习从数据中提取价值。
 Roop Bains 是 AWS 的高级机器学习解决方案架构师。他热衷于协助客户利用人工智能和机器学习进行创新并实现业务目标。他协助客户训练、优化和部署深度学习模型。
Roop Bains 是 AWS 的高级机器学习解决方案架构师。他热衷于协助客户利用人工智能和机器学习进行创新并实现业务目标。他协助客户训练、优化和部署深度学习模型。
 Anastasia Pachni Tsitiridou 是 AWS 的解决方案架构师。Anastasia 居住在阿姆斯特丹,为比荷卢经济联盟区域的软件企业的云之旅提供支持。在加入 AWS 之前,她学习的是电气和计算机工程,主修计算机视觉。如今,她最喜欢的是处理非常大的语言模型。
Anastasia Pachni Tsitiridou 是 AWS 的解决方案架构师。Anastasia 居住在阿姆斯特丹,为比荷卢经济联盟区域的软件企业的云之旅提供支持。在加入 AWS 之前,她学习的是电气和计算机工程,主修计算机视觉。如今,她最喜欢的是处理非常大的语言模型。
 Dhawal Patel 是 AWS 的首席机器学习架构师。他一直就职于从大型企业到中型初创企业等组织,致力于解决与分布式计算和人工智能有关的问题。他专注于深度学习,包括 NLP 和计算机视觉领域。他协助客户在 SageMaker 上实现高性能模型推理。
Dhawal Patel 是 AWS 的首席机器学习架构师。他一直就职于从大型企业到中型初创企业等组织,致力于解决与分布式计算和人工智能有关的问题。他专注于深度学习,包括 NLP 和计算机视觉领域。他协助客户在 SageMaker 上实现高性能模型推理。
 Wioletta Stobieniecka 是 AWS Professional Services 的数据科学家。在她的职业生涯中,她曾为银行、保险、电信和公共部门等不同行业交付过多个分析驱动型项目。她在高级统计方法和机器学习方面的知识与敏锐的商业洞察力完美结合。她带来了最新的人工智能技术,为客户创造价值。
Wioletta Stobieniecka 是 AWS Professional Services 的数据科学家。在她的职业生涯中,她曾为银行、保险、电信和公共部门等不同行业交付过多个分析驱动型项目。她在高级统计方法和机器学习方面的知识与敏锐的商业洞察力完美结合。她带来了最新的人工智能技术,为客户创造价值。
 Rahul Huilgol 是 Amazon Web Services 的分布式深度学习领域的高级软件开发工程师。
Rahul Huilgol 是 Amazon Web Services 的分布式深度学习领域的高级软件开发工程师。