亚马逊AWS官方博客
宣布推出开源时间序列建模工具包 Gluon Time Series
今天,我们宣布推出 Gluon Time Series (GluonTS),这是一种使用 Gluon API 的 MXNet 时间序列分析工具包。此工具包最初是为了满足在 Amazon 以及代表我们客户处理真实行业时间序列问题的应用科研人员的需求而构建,我们很高兴能将它贡献给处理时间序列数据的研究人员和从业者。GluonTS 作为开源软件在 Github 上提供,可以立即获取,它采用 Apache 版本 2.0 许可证。
时间序列应用无所不在
时间序列数据是以时间为索引的数据点的集合,它存在于各个领域和行业。零售行业的商品销售时间序列,来自监控设备、应用程序或云资源的指标,或者物联网传感器生成的测量时间序列等等,都是时间序列数据的例子。与时间序列有关的最常见机器学习任务,包括外推(预测)、内插(平滑处理)、侦测(例如界外值、异常点或变化点侦测)以及分类等。
在 Amazon,我们会在广泛的领域和应用程序中记录和利用时间序列数据。这包括预测供应链中的产品和劳动力需求,或确保我们能够为所有 AWS 客户弹性地扩展 AWS 计算能力和存储容量。通过检测系统和应用程序指标的异常,可让我们自动侦测基于云的应用程序何时遇到运行问题。
借助 GluonTS,我们将内部开发的工具包开源化,为这些以及类似的应用构建算法。机器学习科研人员可以借助它构建新的时间序列模型,尤其是基于深度学习的模型,并可以将这些模型与 GluonTS 中包含的先进模型进行比较。
GluonTS 亮点
借助 GluonTS,用户可以利用包含有用抽象的预构建块来构建时间序列模型。此外,GluonTS 还利用这些构建块构建了流行模型的参考实现,这些参考实现既可以作为模型探索的出发点,也可以用于模型的比较。我们在 GluonTS 中包含了多种工具,让研究人员不再需要重复实施数据处理、回测、模型比较和评估的方法。所有这些工作都极为消耗时间,也容易出错 — 毕竟,如果由于评估代码中的漏洞而错误定性模型的实际性能,其问题的严重性要远远高于算法中的漏洞(这可以在部署前发现)。
用于构建新时间序列模型的构建块
我们编写 GluonTS 的方式确保了能够以不同的方式组合和构建不同的组件,从而让我们可以快速构建和测试新的模型。也许最明显需要包含的组件是神经网络架构,GluonTS 提供了多种选择,例如序列到序列框架、自回归网络和因果卷积等等。此外,我们还包含了许多更加精细化的组件。例如,为了更好地支持最优决策,预测一般应是概率化的。在此方面,GluonTS 提供了多种典型的参数化概率分布,此外还提供了累积分布函数或分位函数的直接建模工具,这些都可以方便地包含在神经网络架构中。此外还包括了其他概率化组件,例如高斯过程和线性高斯状态空间模型(包括一种卡尔曼滤波器的实现),从而轻松创建神经网络与传统概率模型的组合。我们还包含了变量 Box-Cox 变换等数据变换工具,其参数可以与其他模型参数一起学习。
与先进的模型轻松比较
GluonTS 包含多种文献记载的基于深度学习的时间序列模型的参考实现,演示了如何使用不同的组件,以及如何将其作为模型探索的出发点。我们也包含了自己研究的多种模型,例如 DeepAR 和样条分位函数 RNN;此外还包含了来自其他领域的序列模型,例如 WaveNet(原本用于语音分析,在此处经过调整后用于预测性的使用案例)。借助 GluonTS 可以方便地与这些参考实现进行比较,此外还可方便地与来自其他开源库(例如 Prophet 和 the R 预测包)的其他模型进行基准比较。
工具
GluonTS 包含加载和转换输入数据所需的工具,从而确保可以使用和转换不同形式的数据,满足特定模型的要求。我们还包含了一个用于计算预测文献中讨论的许多准确度指标的评估组件,并且期待通过来自社区的贡献增加更多指标。由于这些指标的准确计算方式存在微妙的差异,拥有标准化的实现,对于在不同的模型之间进行有意义、可复制的比较无比珍贵。
指标当然非常重要,而探索、调试和持续改进模型的工作也往往是从利用受控数据绘制结果开始。在绘图方面我们采用 Matplotlib,并且包含了一个合成数据集生成器,它可以模拟具有若干可配置特征的时间序列数据。
GluonTS 与 Amazon Forecast 之间的关系是什么?
GluonTS 面向希望设计新颖的时间序列模型、从头构建模型或者需要适合特殊使用案例的自定义模型的研究人员(例如机器学习、时间序列建模和预测领域的专家)。对于生产使用案例以及不需要构建自定义模型的用户,Amazon 提供了 Amazon Forecast,这是一种完全托管的服务,借助机器学习来提供高度准确的预测。借助 Amazon Forecast,无需机器学习方面的专业知识即可构建基于机器学习的准确时间序列预测模型,因为 Amazon Forecast 使用的 AutoML 功能会帮助您完成正确选择、构建和优化模型等繁重的工作。
GluonTS 入门
GluonTS 现已在 GitHub 和 PyPi 上提供。完成安装之后,使用预构建的预测模型即可轻松完成您的第一次预测。收集好数据后,只需大约十行 Python 代码即可完成模型训练并生成如下的图形。
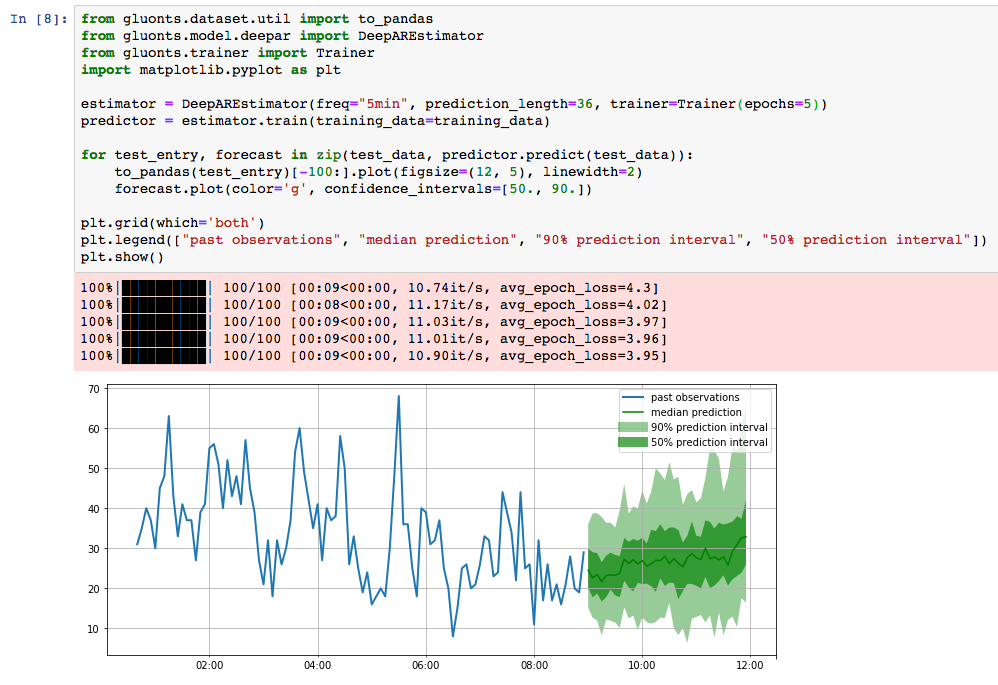
上图显示了对提及 AMZN 股票代码的推文量预测(每五分钟)。它是利用来自 Numenta Anomaly Benchmark 数据集的数据进行模型训练得出的。
我们和 GluonTS 都还处于发展的初期。预计随着时间推移,GluonTS 将会不断演变,在预测的基础上我们也将增加更多的应用。实现 1.0 版本还需要更多的工作。我们欢迎大家通过漏洞报告、特性增强建议、新功能和功能改进 pull 请求,当然还包括通过实现最新和最好的时间序列模型等方式,提供有关 GluonTS 的反馈和贡献。
相关文献和即将举行的活动
在 ICML 2019 时间序列研讨会上,我们将发表一篇关于 GluonTS 的文章,并且在 SIGMOD 2019 和 KDD 2019 上,我们将以 GluonTS 为例提供有关预测的教程。
下面是涉及 GluonTS 中模型的一些出版物:
- Probabilistic Forecasting with Spline Quantile Function RNNs
- A Multi-Horizon Quantile Recurrent Forecaster
- DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks
另外还可参阅 AWS Machine Learning 博客:Creating neural time series models with Gluon Time Series。
Lorenzo Stella、Syama Rangapuram、Konstantinos Benidis、Alexander Alexandrov、David Salinas、Danielle Maddix、Yuyang Wang、Valentin Flunkert、Jasper Schulz 和 Michael Bohlke-Schneider 亦为本博文和 GluonTS 做出了贡献。