亚马逊AWS官方博客
用于 Kubeflow Pipelines 的 Amazon SageMaker Components 介绍
Original URL: https://aws.amazon.com/cn/blogs/machine-learning/introducing-amazon-sagemaker-components-for-kubeflow-pipelines/
今天,我们正式公布用于Kubeflow Pipelines的Amazon SageMaker Components。本文将向大家讲解如何通过Kubeflow Pipelines SDK
Kubeflow是一款流行的开源机器学习(ML)工具包,适用于希望构建自定义机器学习管道的Kubernetes用户。Kubeflow Pipelines属于Kubeflow提供的附加组件,可帮助您构建并部署具备良好可移植性与可扩展性的端到端机器学习工作流。但在使用Kubeflow Pipelines时,数据科学家往往需要耗费不少精力以实现各类生产力工具,例如数据标记工作流与模型调优工具。
另外,在使用Kubeflow Pipelines的过程中,MLOps团队还需要管理Kubernetes集群中的CPU与GPU实例,考虑如何保持资源的高利用率,最终实现最佳投资回报。在数据科学团队当中,充分利用集群资源是一项极为艰巨的挑战,同时也极大增加了MLOps团队的运营压力。例如,我们需要保证仅使用GPU实例处理深度学习训练及推理等性能要求较高的任务,并将CPU实例用于执行数据预处理以及Kuberflow管道控制平面等性能要求相对较低的任务。
作为备选方案,Amazon SageMaker Components能够帮助我们在Kubeflow Pipelines上实现强大的Amazon SageMaker功能,以全托管服务的形式支持数据标记、大规模超参数调优以及分布式训练作业、一键式安全可扩展模型部署,以及通过 Amazon Elastic Compute Cloud (Amazon EC2)竞价实例进行高成本效益训练等目标。
面向Kubeflow Pipelines的Amazon SageMaker Components
您可以在Kubeflow Pipelines中使用SageMaker Components,立足机器学习工作流中的各个阶段调用相应SageMaker作业,且无需担心其在后台的具体运行方式。作为数据科学家或机器学习开发人员,我们可以借此将精力集中在通过可移植、可扩展管道内构建及运行机器学习实验身上。所谓管道组件,是指能够在容器化应用程序中实现复用的代码,大家可以根据需求进行代码共享以提高生产效率。
如果您希望使用Amazon SageMaker中的超参考调优功能,则可以使用超参数优化组件。在管道作业的运行过程中,相应的超参数调优步骤将在Amazon SageMaker全托管基础设施之上进行。在下一节中,我们将具体介绍其工作方式;在本节,我们先来介绍Amazon SageMaker Components的基本原理。
在一条典型的Kubeflow管道当中,各个组件负责将您的逻辑封装在容器镜像当中。作为开发人员或者数据科学家,您需要将训练、数据预处理、模型服务或者其他逻辑打包在Kubeflow Pipelines ContainerOp函数当中,由该函数将代码构建至新容器内。或者,您也可以将代码放置在自定义容器镜像中,而后将镜像推送至容器注册表(例如Amazon Elastic Container Registry,简称Amazon ECR)。在管道运行时,负责运行Kubeflow的Kubernetes集群将指定一个工作节点对组件容器进行实例化,进而执行相关逻辑。管道组件可读取先前组件的输出,并生成管道中下一组件可以使用的输出。下图所示,为此管道工作流的基本架构。
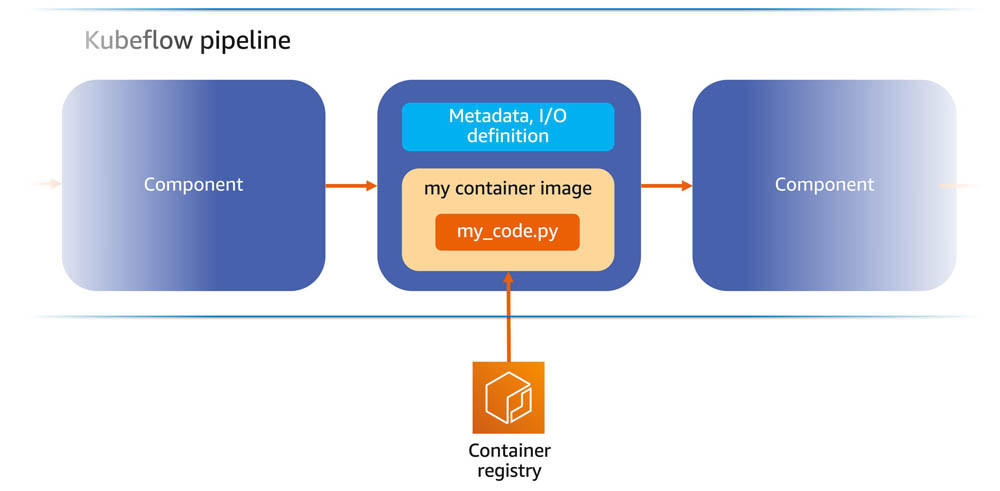
在Kubeflow Pipelines中使用Amazon SageMaker Components时,大家不再需要将逻辑封装在自定义容器之内,而可以直接加载对应组件并使用Kubeflow Pipelines SDK描述您的管道。在管道运行时,其中的指令将被转换为Amazon SageMaker作业或部署。而后,工作负载将在Amazon SageMaker全托管基础设施之上运行,保证我们充分享受Amazon SageMaker的各项典型优势——包括Managed Spot Training、端点自动规模伸缩等。下图为这类增强管道的基本架构。

在启动的同时,管道即可支持以下Amazon SageMaker功能:
- Amazon SageMaker Ground Truth
- 创建标记工作流
- 训练作业
- 模型部署
- 批量转换作业
随着时间推移,AWS将继续推出更多功能,这里建议大家在官方Kubeflow Pipelines GitHub repo中收收藏Amazon SageMaker Components目录链接。
面向Kubeflow Pipelines的Amazon SageMaker Components使用入门
为了说明如何在Kubeflow当中使用Amazon SageMaker Components,让我们按下图所示构建一条小型管道。

实际场景中的管道往往更为高级,而且涉及数据摄取、数据预处理、数据转换等其他步骤。但为简便起见,这里只使用最简单的管道设计。
您可以在YouTube上观看本演练的视频版本,《在Kuernetes与Kubeflow上使用SageMaker实现机器学习规模扩展》(Scaling Machine Learning on Kubernetes and Kubeflow with SageMaker)。
下面来看管道中各个步骤的具体作用:
组件1:超参数调优作业
第一个组件,负责运行Amazon SageMaker超参数调优作业以优化以下超参数:
- 学习率 – [0.0001, 0.1] log scale
- 优化器 – [sgd, adam]
- 批次大小– [32, 128, 256]
- 模型类型 – [resnet, custom model]
输入: N/A
输出: 最佳超参数
组件2:选择最佳超参数
在上一步的超参数搜索过程中,模型只需要训练10个轮次即可确定最佳性能超参数。而在第二步中,为了获取最佳超参数,我们需要进行80轮更新,以保证最佳超参数能够进一步提升模型准确率。
输入:最佳超参数
输出:经过80轮更新的最佳超参数
组件3:使用最佳超参数执行训练作业
第三个组件将使用轮次最高的最佳超参数运行Amazon SageMaker训练作业。
输入:经过80轮更新的最佳超参数
输出:训练作业名称
组件4:创建一套待部署模型
第四个组件将创建一套Amazon SageMaker模型工件。
输入:训练作业名称
输出:模型工件名称
组件5:部署推理端点
最终组件将使用Amazon SageMaker完成模型部署。
输入:模型工件名称
输出:N/A
先决条件
要运行以下用例,大家需要做好如下准备:
- Kubernetes集群——您可以直接使用现有集群,或者创建一个新集群。最快的启动与运行方式,是使用eksctl启动一个 Amazon Elastic Kubernetes Service (Amazon EKS)集群。关于具体操作说明,请参阅eskctl入门教程。在这里,我们创建一套包含双CPU节点的简单集群,节点类型为c5.xlarge。这一配置已经足以支持我们的Amazon SageMaker Component容器以及Kubeflow工作负载。训练与部署作业将运行在Amazon SageMaker托管基础设施之上。
- Kubeflow Pipelines——在集群上安装Kubeflow Pipelines。关于具体操作说明,请参阅部署Kubeflow Pipelines中的第一步。我们使用的Kubeflow Pipelines版本应为0.5.0或者更高。另外,您也可以根据需求选择安装Kubeflow完整版本,其中也将包含Kubeflow Pipelines。
- Amazon SageMaker Components先决条件——关于设置AWS身份与访问管理(AWS Identity and Access Management,简称IAM)角色与权限的操作说明,请参阅面向Kubeflow Pipelines的Amazon SageMaker Components。您需要以下两个IAM角色:
- Kubeflow管道pod,用于访问Amazon SageMaker并启动作业与部署。
- Amazon SageMaker,用于访问Amazon Simple Storage Service (Amazon S3)及Amazon ECR等其他AWS资源。
选择一个网关实例以启动Amazon EKS集群
您可以通过笔记本电脑、台式机、EC2实例或者Amazon SageMaker notebook实例启动Amazon EKS集群。无论如何选择,我们通常将该实例称为“网关实例”。这是因为Amazon EKS提供完全托管的控制平面,您只需要使用网关实例即可与Kubernetes API以及工作节点进行交互。在本示例中,我们使用一个c5.xlarge EC2实例作为网关实例。
GitHub上提供本文中使用的代码、配置文件、Jupyter notebooks以及Dockerfiles。我们将通过以下演示逐步解释其中涉及的各项核心概念。请不要在各步骤中复制代码,我们建议您直接运行GitHub上提供的现成Jupyter notebooks。
步骤1:克隆示例repo
打开终端并通过SSH接入我们用于创建Amazon EKS集群的Amazon EC2网关实例。在登录之后,克隆该示例repo以访问示例Jupyter notebook。详见以下代码:
步骤2:在网关实例上打开示例Jupyter notebook
要在网关实例上打开Jupyter notebook,请完成以下操作步骤:
- 在网关实例上启动Jupyter,并使用以下代码通过本地设备访问Jupyter:
如果大家是在EC2实例上运行Jupyterlab服务器,请设置一条指向该EC2实例的通道,借此通过本地笔记本或者台式机访问Jupyterlab客户端。详见以下代码:
如果您使用的是Amazon Linux而非Ubuntu,则必须使用ec2-user这一用户名。更新EC2实例的IP地址,并使用对应的密钥对。
现在,大家可以在本地设备上通过http://localhost:8888访问Jupyterlab了。
- 在网关实例上运行以下代码以访问Kubeflow仪表板:
现在,大家可以通过http://localhost:8081访问Kubeflow仪表板了。
- 打开示例Jupyter notebook。
Amazon SageMaker支持两种训练作业模式(GitHub repo 中分别为两种模式提供对应的Jupyter notebook):
-
- 自带Docker容器镜像——在这种模式下,您可以提供自己的Docker容器以执行训练。使用训练脚本构建容器,而后将其推送至Amazon ECR容器注册表。Amazon SageMaker会提取该容器镜像,进行实例化,而后开始训练。
kfp-sagemaker-custom-container.ipynbJupyter notebook采用的即是这种方法。 - 自带训练脚本(即脚本模式)——在这种模式下,我们无需使用Docker容器。只要将机器学习训练脚本导入TensorFlow、PyTorch、MXNet或者XGBoost等流行框架中,而后将框架上传至Amazon S3即可。Amazon SageMaker会自动提取适当容器、下载训练脚本而后加以运行。如果您不想使用Docker容器,那么这种模式明显更为适用。
kfp-sagemaker-script-mode.ipynbJupyter notebook采用的就是这种方法。
- 自带Docker容器镜像——在这种模式下,您可以提供自己的Docker容器以执行训练。使用训练脚本构建容器,而后将其推送至Amazon ECR容器注册表。Amazon SageMaker会提取该容器镜像,进行实例化,而后开始训练。
以下示例主要探讨第一种方法(自带Docker容器镜像)。本演练将带大家了解kfp-sagemaker-custom-container.ipynb Jupyter notebook中的各个重要步骤。在将其打开后,我们即可轻松完成后续操作。
以下截屏所示,即 kfp-sagemaker-custom-container.ipynb notebook。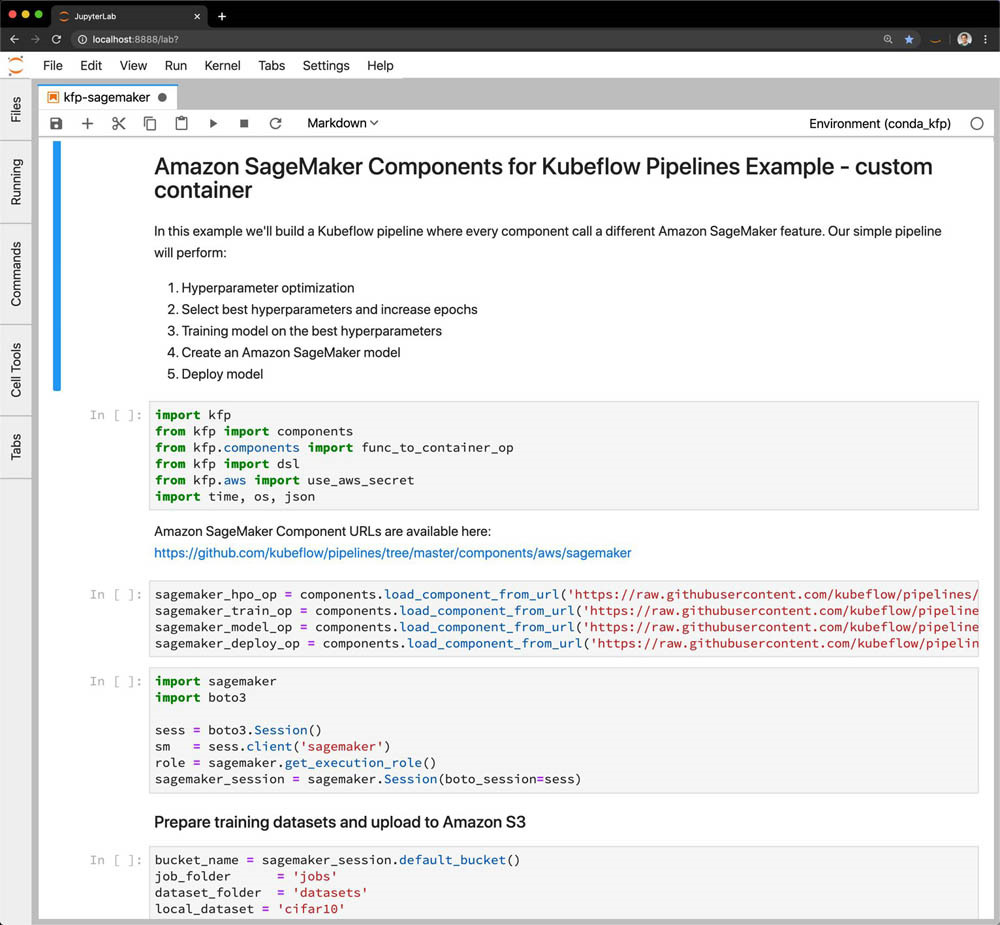
步骤3:安装Kubeflow Pipelines SDK并加载Amazon SageMaker管道组件
要安装SDK并加载各管道组件,请完成以下操作步骤:
- 使用以下代表安装Kubeflow Pipelines SDK:
- 使用以下代码在Python中导入Kubeflow Pipelines软件包:
- 使用以下代码在Python中加载Kubeflow Pipelines Components:
sagemaker_hpo_op = components.load_component_from_url(‘https://raw.githubusercontent.com/kubeflow/pipelines/master/components/aws/sagemaker/hyperparameter_tuning/component.yaml’)sagemaker_train_op = components.load_component_from_url(‘https://raw.githubusercontent.com/kubeflow/pipelines/master/components/aws/sagemaker/train/component.yaml’)sagemaker_model_op = components.load_component_from_url(‘https://raw.githubusercontent.com/kubeflow/pipelines/master/components/aws/sagemaker/model/component.yaml’)
sagemaker_deploy_op = components.load_component_from_url(‘https://raw.githubusercontent.com/kubeflow/pipelines/master/components/aws/sagemaker/deploy/component.yaml’)
在生产工作流中,我们建议大家将组件固定至特定提交操作当中,而非直接使用master。这样可以保证任何可能导致兼容性破坏的变更都不会对生产流程造成影响。
例如,要使用特定的提交版本,请在各加载组件中使用提交哈希替换掉master部分:
sagemaker_train_op = components.load_component_from_url(‘https://raw.githubusercontent.com/kubeflow/pipelines/cb36f87b727df0578f4c1e3fe9c24a30bb59e5a2/components/aws/sagemaker/train/component.yaml’)
步骤4:准备训练数据集,将数据集上传至Amazon S3
要准备并上传数据集,请输入以下代码:
import sagemakerimport boto3 sess = boto3.Session()account = boto3.client(‘sts’).get_caller_identity().get(‘Account’)sm = sess.client(‘sagemaker’)role = sagemaker.get_execution_role()sagemaker_session = sagemaker.Session(boto_session=sess) bucket_name = sagemaker_session.default_bucket()job_folder = ‘jobs’dataset_folder = ‘datasets’local_dataset = ‘cifar10′ !python generate_cifar10_tfrecords.py —data-dir {local_dataset}datasets = sagemaker_session.upload_data(path=’cifar10′, key_prefix=’datasets/cifar10-dataset’)
在以上代码中,我们首先导入sagemaker 与 boto3 软件包,借此访问当前计算机的IAM角色与默认的S3存储桶。Python脚本generate_cifar10_tfrecords.py使用TensorFlow下载相应数据,将其转换为TFRecord格式,而后上传至Amazon S3。
步骤5:构建Docker容器并将其推送至Amazon ECR
build_docker_push_to_ecr.ipynb Jupyter notebook负责执行创建容器并将其推送至Amazon ECR的全部操作步骤。
Docker目录中还包含Dockerfile、训练与推理Python脚本,以及保存在需求文件中的各依赖项。以下截屏所示,为Docker文件夹的具体内容——Dockerfile以及build_docker_push_to_ecr.ipynb Jupyter notebook。
关于如何使用Amazon SageMaker运行自定义容器的更多详细信息,请参阅在Amazon SageMaker中使用您的自有算法或模型。
如果您不打算构建自己的容器,可以指定由Amazon SageMaker替您管理容器。在这种方法下,您可以将训练脚本上传至Amazon S3,如kfp-sagemaker-script-mode.ipynb notebook中所示。
步骤6:使用Amazon SageMaker Components创建Kubeflow管道
我们可以将Kubeflow管道表示为由@dsl.pipeline装饰的函数,参见以下代码及kfp-sagemaker-custom-container.ipynb所示。关于更多详细信息,请参阅Kubeflow Pipelines概述。
@dsl.pipeline( name=’cifar10 hpo train deploy pipeline’, description=’cifar10 hpo train deploy pipeline using sagemaker’)def cifar10_hpo_train_deploy(region=’us-west-2′, training_input_mode=’File’, train_image=f'{account}.dkr.ecr.us-west-2.amazonaws.com/sagemaker-kubernetes:latest’, serving_image=’763104351884.dkr.ecr.us-west-2.amazonaws.com/tensorflow-inference:1.15.2-cpu’, volume_size=’50’, max_run_time=’86400′, instance_type=’ml.p3.2xlarge’, network_isolation=’False’, traffic_encryption=’False’, …
在本文的示例代码中,我们创建一项名为cifar10_hpo_training_deploy() 的新函数,由其定义管道中各步骤间共通的参数。在该函数内,我们还将定义以下五项管道组件。
组件1:Amazon SageMaker超参数调优作业
此组件描述了超参数调优作业中的相关选项。详见以下代码:
hpo = sagemaker_hpo_op( region=region, image=train_image, training_input_mode=training_input_mode, strategy=’Bayesian’, metric_name=’val_acc’, metric_definitions='{“val_acc”: “val_acc: ([0-9\\\\.]+)”}’, metric_type=’Maximize’, static_parameters='{ \ “epochs”: “1”, \ “momentum”: “0.9”, \ “weight-decay”: “0.0002”, \ “model_dir”:”s3://’+bucket_name+’/jobs”, \ “sagemaker_region”: “us-west-2” \ }’, continuous_parameters='[ \ {“Name”: “learning-rate”, “MinValue”: “0.0001”, “MaxValue”: “0.1”, “ScalingType”: “Logarithmic”} \ ]’, categorical_parameters='[ \ {“Name”: “optimizer”, “Values”: [“sgd”, “adam”]}, \ {“Name”: “batch-size”, “Values”: [“32”, “128”, “256”]}, \ {“Name”: “model-type”, “Values”: [“resnet”, “custom”]} \ ]’, channels=channels, output_location=f’s3://{bucket_name}/jobs’, instance_type=instance_type, instance_count=’1′, volume_size=volume_size, max_num_jobs=’16’, max_parallel_jobs=’4′ …
这些选项包括调优策略(贝叶斯)、优化指标(验证准确率)、连续超参数(学习率)、分类超参数(优化器、批次大小与模型类型)以及保持不变的静态超参数(例如轮次数=10)。
我们将作业数量指定为16。Amazon SageMaker会配置16个GPU实例以运行这项超参数调优作业。
组件2:用于更新轮次数的自定义组件
组件1的输出将被捕捉在hpo变量当中。组件2则采用最佳超参数并更新轮次数,具体参见以下代码:
training_hyp = get_best_hyp_op(hpo.outputs[‘best_hyperparameters’])
为此,我们需要定义一项自定义函数,由其获取此项输出并将轮次数更新为80。这意味着我们需要经历更长的训练时间,但可以凭借最佳超参数提升训练效果。具体参见以下代码:
def update_best_model_hyperparams(hpo_results, best_model_epoch = “80”) -> str: import json r = json.loads(str(hpo_results)) return json.dumps(dict(r,epochs=best_model_epoch)) get_best_hyp_op = func_to_container_op(update_best_model_hyperparams)
组件3:Amazon SageMaker训练作业
此组件负责描述Amazon SageMaker训练作业,此作业将使用最佳超参数与先前步骤中经过更新的轮次数。详见以下代码:
training = sagemaker_train_op( region=region, image=train_image, training_input_mode=training_input_mode, hyperparameters=training_hyp.output, channels=channels, instance_type=instance_type, instance_count=’1′, volume_size=volume_size, max_run_time=max_run_time, model_artifact_path=f’s3://{bucket_name}/jobs’, network_isolation=network_isolation, traffic_encryption=traffic_encryption, spot_instance=spot_instance, role=role, )
组件4:Amazon SageMaker模型创建
此组件负责创建一套Amazon SageMaker模型工件,供大家作为推理端点进行部署与托管。详见以下代码:
create_model = sagemaker_model_op( region=region, model_name=training.outputs[‘job_name’], image=serving_image, model_artifact_url=training.outputs[‘model_artifact_url’], network_isolation=network_isolation, role=role )
组件5:Amazon SageMaker模型部署
最后,此组件负责模型部署,详见以下代码:
prediction = sagemaker_deploy_op( region=region, model_name_1=create_model.output, instance_type_1=’ml.m5.large’ )
管道编译与运行
使用Kubeflow管道编译器,大家可以编译此管道、创建实验并运行管道。详见以下代码:
kfp.compiler.Compiler().compile(cifar10_hpo_train_deploy,’sm-hpo-train-deploy-pipeline.zip’)client = kfp.Client()aws_experiment = client.create_experiment(name=’sm-kfp-experiment’) exp_name = f’cifar10-hpo-train-deploy-kfp-{time.strftime(“%Y-%m-%d-%H-%M-%S”, time.gmtime())}’my_run = client.run_pipeline(aws_experiment.id, exp_name, ‘sm-hpo-train-deploy-pipeline.zip’)
步骤7:结果
以下截屏所示,为Kubeflow管道执行完成之后的结果(带有注释)。除了“自定义函数以更新轮次(Custom function to update epochs)”步骤之外,其余所有步骤皆由Amazon SageMaker在Kubeflow管道中实现。
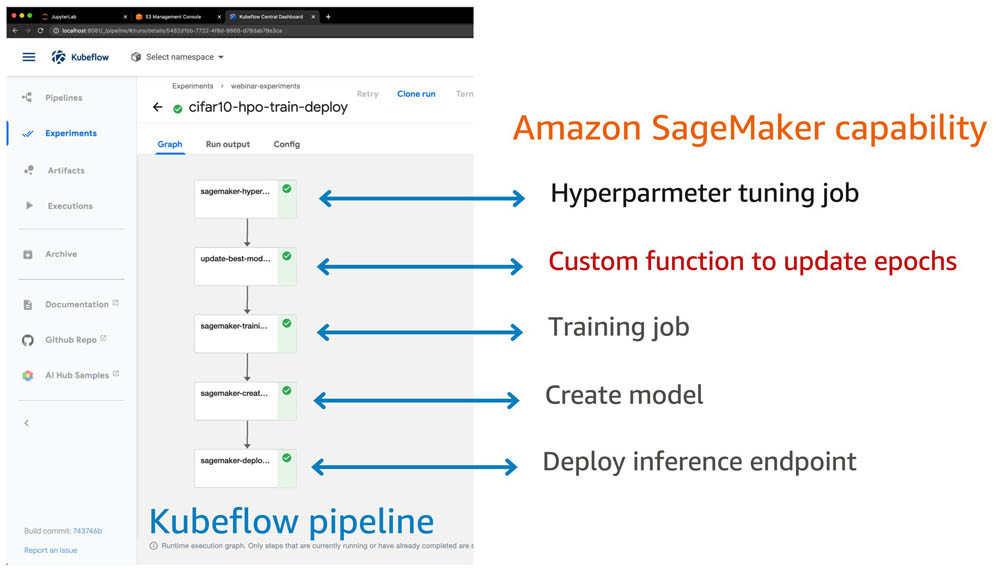
您还可以在Amazon SageMaker控制台上监控各个步骤的当前进度。以下截屏所示,为用于执行超参数调优作业的Amazon SageMaker控制台。
端点测试
在管道整体运行完毕之后,我们的模型将作为推理端点接受托管,如以下截屏所示。

要测试该端点,请复制端点名称并使用boto3 SDK获取预测结果:
import json, boto3, numpy as npclient = boto3.client(‘runtime.sagemaker’) file_name = ‘1000_dog.png’with open(file_name, ‘rb’) as f: payload = f.read() response = client.invoke_endpoint(EndpointName=’Endpoint-20200522021801-DR5P’, ContentType=’application/x-image’, Body=payload)pred = json.loads(response[‘Body’].read())[‘predictions’]labels = [‘airplane’,’automobile’,’bird’,’cat’,’deer’,’dog’,’frog’,’horse’,’ship’,’truck’]for l,p in zip(labels, pred[0]): print(l,”{:.4f}”.format(p*100))
在对包含小狗的图片进行分析时,我们应得出如下输出结果:
airplane 0.0000automobile 0.0000bird 0.0001cat 0.0115deer 0.0000dog 99.9883frog 0.0000horse 0.0000ship 0.0000truck 0.0000
总结
本文介绍了如何配置Kubeflow Pipelines以通过Amazon SageMaker运行机器学习作业。Kubeflow Pipelines是一套开源机器学习编排平台,在希望立足Kubernetes构建并管理自定义机器学习工作流的开发者群体中广受欢迎。但不少开发人员及MLOps团队在Kubeflow Pipelines的实际运营中遭遇挑战,发现自己难以管理Kubernetes集群的机器学习优化工作,无法获得良好的投资回报率或者承担极高的总体拥有成本。
在面向Kubeflow Pipelines的SageMaker Components的帮助下,您可以继续在Kubeflow Pipelines中管理自有管道,并依靠Amazon SageMaker的托管功能执行具体的机器学习任务。数据科学家与机器学习开发人员还可以使用Amazon SageMaker中的最新创新成果,例如全托管超参数调优、分布式训练、Managed Spot Training、自动规模伸缩等功能。我们还展示了如何使用Amazon SageMaker Components创建并运行一条端到端Kuberflow示例管道。完整示例请参阅GitHub。
如果您喜欢边看边学,不妨在YouTube上观看《在Kuernetes与Kubeflow上使用SageMaker实现机器学习规模扩展》(Scaling Machine Learning on Kubernetes and Kubeflow with SageMaker)视频。其中概述了面向Kubeflow Pipelines的Amazon SageMaker Components,同时也涵盖本文所讨论的演练示例。
如果您对Amazon SageMaker Components或者本文内容仍有疑问或意见,请在Kubeflow Pipelines GitHub repo上发表评论或创建新问题。