亚马逊AWS官方博客
从 Kudu 迁移到 Hudi
在构建本地数据中心的时候,出于Kudu良好的性能和兼备OLTP和OLAP的特性,以及对Impala SQL和Spark的支持,很多用户会选择Impala / Spark + Kudu的技术栈。但是由于Kudu对本地存储的依赖,导致无法支持的数据高可用和弹性扩缩容,以及社区的逐渐不活跃,越来越多的用户,开始迁移到云上的Trino / Spark + Hudi 技术栈,本文通过一个实际的例子,来看一下迁移过程中发生的代码的重构和数据的迁移。
1、现状
以下案例总结于真实场景: 假设我们在帮助一个典型的零售领域的数字营销软件ISV (简称 C公司) 进行迁移,他们的数字营销软件 (平台) 借助互联网大数据、人工智能等技术,帮助他们的企业用户构建贴近客户真实行为的画像洞察。通过营销自动化精准触达和交互,提升客户体验和实现业绩增长。
大部分公司在自建数据中心的时候,会采用Cloudera Distributed Hadoop (CDH) 作为数据开发的平台,它包含常用的技术栈例如Spark,Impala,Kudu等,具体的应用场景,可以参考后面的章节。我们先来看一下这些技术栈的特点。
先约定一下文中用到的几个称谓:
- 开发者:是指AWS服务的使用者和开发人员,在本文中即C公司的开发人员
- 商家:使用C公司的营销软件的企业用户,例如 S 公司,他们使用C公司的营销软件来服务他们的客户
- 客户:使用C公司的营销软件的企业用户 (例如 S 公司) 所服务的个体客户
本文中所有代码都采用TPCDS测试数据中的inventory表来作为测试数据。
1.1. CDH 介绍
CDH是Cloudera公司发行的Hadoop版本,包括Apache Hadoop生态下的常用组件,专为满足企业需求而构建。CDH提供开箱即用的企业开发所需的服务,通过将Hadoop与十几个其他关键的开源项目集成,CDH 为企业大数据开发提供了一套完整的技术栈。
同时,Cloudera创建了一个拥有集群自动化安装、中心化管理、集群监控、报警功能的一个管理软件,即 Cloudera Manager, 极大的提高了集群管理的效率。
由于CDH对原生社区的服务进行了大量的优化,明显提升了组件的稳定性和多个组件之间的兼容性,为开发人员提供了很大的方便,使得CDH成为搭建本地数据中心的首选平台。
1.2. Impala 介绍
Impala是Cloudera由C++编写的基于MPP (Massively Parallel Processing) 架构的查询引擎,由运行在CDH集群上的不同的守护进程组成,它可以使用Hive的Metastore里的Database和Table等信息。Impala可以读取Hive的表数据,也可以自己创建表,特别是可以创建数据位于Kudu的表。
Impala作为流行的SQL解析引擎,其面对即席查询 (Ad-Hoc Query) 类请求的稳定性和速度在业界得到过广泛的验证。
1.3. Kudu 介绍
Kudu和Impala都是Cloudera贡献给Apache基金会的顶级项目。Kudu作为底层存储,在支持高并发低延迟KV查询的同时,还保持良好的Scan性能,该特性使得其理论上能够同时兼顾OLTP类和OLAP类查询。Impala作为查询引擎,初期主要支持HDFS,Kudu发布之后,Impala和Kudu更是做了深度集成。
从下图可以看到,Kudu设计的初衷,就是想兼顾Parquet (列存,高吞吐) 和HBase (主键,低延迟) 的双重优势。

Kudu的存储架构设计,吸取了HBase的很多经验,可以参考: https://kudu.apache.org/docs/index.html. 基于Kudu的存储架构,Kudu提供了良好的Upsert功能,而不需要修改整个分区的数据,这是很多开发者喜欢的,例如在数仓建模的场景中,可以频繁地修改一个Partition里的少量数据,而不是把整个Partition都Overwrite.
同时Kudu也有一些限制,例如主键的限制、分片的限制、表大小的限制……这些可以参考:https://kudu.apache.org/docs/known_issues.html . 尤其是Kudu要依赖本地的存储,不能支持HDFS或者对象存储 (例如S3) 这些高可用的存储方式,导致了Kudu在容灾备份方面考虑不充分,同时本地存储也无法实现真正的存算分离和弹性计算。因此,我们向客户推荐Hudi来替代Kudu作为存储服务。
1.4. Hudi 介绍
Apache Hudi (发音为“hoodie”, 全称是:Hadoop Update Delete Incremental,以下简称为Hudi) ,作为新一代流式数据湖平台,得到了越来越广泛的应用。它是由Uber开源的项目,可以低延迟摄取数据保存到HDFS或者对象存储 (例如S3) 上。
Hudi充分利用了开源的列存储 (Parquet) 和行存储 (Avro) 的文件作为数据的存储格式,并在数据写入时生成索引,以提高查询的性能,具体请参考:https://hudi.apache.org/docs/indexing .
与Kudu类似的功能是,Hudi也支持记录级别的插入更新(Upsert) 和删除,这使得Hudi能适应Kudu的很多场景。
Aamzon EMR从 6.0.0 版本和5.28.0版本开始,就提供了Hudi 组件。我们推荐使用Hudi替换Kudu的理由和场景包括:
- Spark + Hudi能实现Spark + Kudu的大部分场景,例如Upsert
- Hudi 可以将数据保存在对象存储 (例如S3) 上,对于实现存算分离和容灾备份有得天独厚的优势,同时又降低了存储的成本(Kudu需要使用本地SSD存储才能发挥高吞吐的优势)
- Hudi表支持常用的查询引擎,可以使用Hive, Presto, Trino访问Hudi表
对于Hudi的其他优势,例如Clustering, Metadata Index等,我们在这次迁移中没有使用到,在这里不展开讨论。
笔者也做了很多性能相关的测试,在同样的资源,Impala + Kudu的性能,无论是即席查询 (Ad-Hoc Query) 还是通过JDBC随机查询,都要比Trino + Hudi好一些,不过性能的问题,可以通过Amazon EMR的弹性扩容来提升和调节。
在性能之外,也需要考虑迁移后的组件的通配性和适用性。例如与其它常用组件的集成使用,以及开发和运维过程中使用的技术栈是否通用,即不会要求开发者做大量的重构代码,也不会偏离常用的和主流的技术栈,我们会保留客户大部分的Spark代码。
接下来我们会从如下两个场景,来帮助客户从Spark / Impala + Kudu的代码,迁移到Spark / Trino + Hudi上来。
2、“客户档案” 场景
客户档案是使用C公司数据分析平台的商家S公司的一个常用场景,主要通过收集客户的行为统计数据,整理客户的行为统计信息,实现客户分群,为客户打标签做数据准备。
该场景下的数据特点:
- 客户档案由3~5张表组成,由商家创建的,系统为客户生成统一的主键
- 表的列数量为100个左右,可以自由的增加列
- 商家会以不固定的频率更新表,例如第一天第一个批次更新100万条,第二天第二个批次更新200万条
已有的架构图如下:
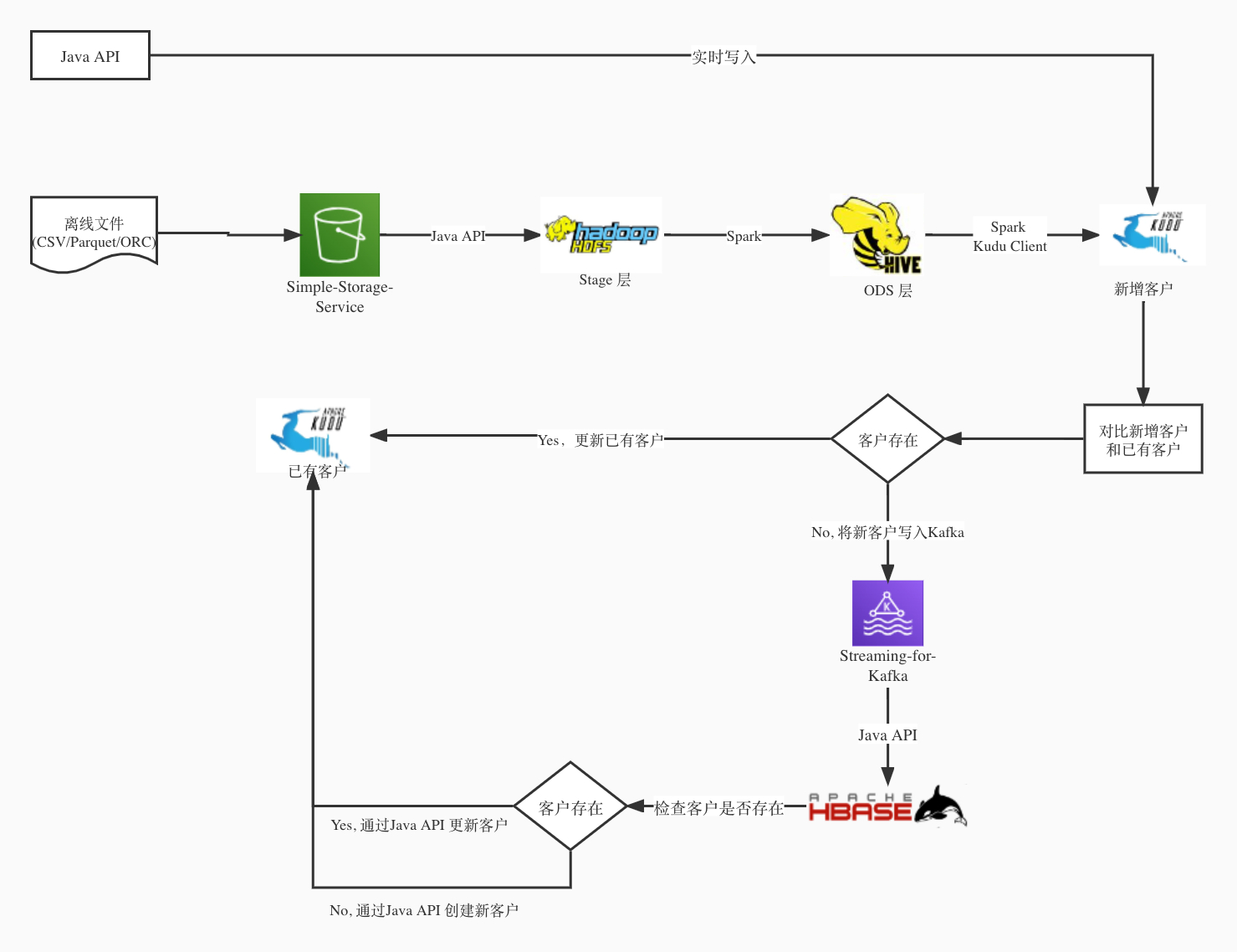
2.1. 在Kudu里的实现
我们重点关注两部分,一是用户通过Java API实时写入Kudu的实现,该部分功能的测试代码如下:
请注意,通过Java API写入Kudu表的时候,并不需要知道Kudu表完整的Schema.
另一部分就是通过Spark Kudu Client去批量操作Kudu表数据,该部分功能的测试代码如下:
完整的测试代码请参考: https://github.com/xudalei1977/cdh-example, 请注意,这些测试代码只是为了展示基本的功能,省略去了业务处理逻辑的部分。
2.2. 在Hudi里的实现
我们将客户档案的架构设计中的Kudu替换为Hudi.
修改后的架构图如下:

涉及的代码重构的部分有三块:
- Java API原来直接写入Kudu的,现在改成写入Kafka
- 添加Spark Streaming读取Kafka数据并写入Hudi的部分
- Spark 读写 Kudu的操作,改为Spark 读写 Hudi
其中1. 的代码可以参考:https://github.com/xudalei1977/cdh-example, 2) 和3)的代码可以参考:https://github.com/xudalei1977/emr-hudi-example .
2.3. 组件对比
在客户档案的场景下,Kudu和Hudi两种组件的对比如下:
| 对比内容 | Kudu | Hudi |
| 存储 | 本地存储,无法实现存算分离和容灾备份 | 可以存储在HDFS和对象存储 (例如S3) |
| 适配性 | 映射到Impala表,供其它组件访问 | 同步到Hive Metastore, 供其它组件访问 |
| JavaAPI | Kudu Master Server提供API | 需要借助Spark/Trino JDBC来访问 |
| Upsert | 通过JavaAPI执行Upsert,不需要Schema | 需要预先读取或者定义Schema |
3、“实时数仓” 场景
商户S公司要对客户的行为,包括点击访问、触达、订单等操作,建设数据仓库,挖掘数据价值,整理出营销活动需要的实时数据,实现提升转化率、精准投放和数据回溯。
该场景下的数据特点:
- 数据量较大,事实表 (Fact) 有时间维度
- 大部分是新增数据,数据来源包括离线和实时两部分
- 事实表 (Fact) 和维度表 (Dim) 的总数量为100个左右
架构图如下:
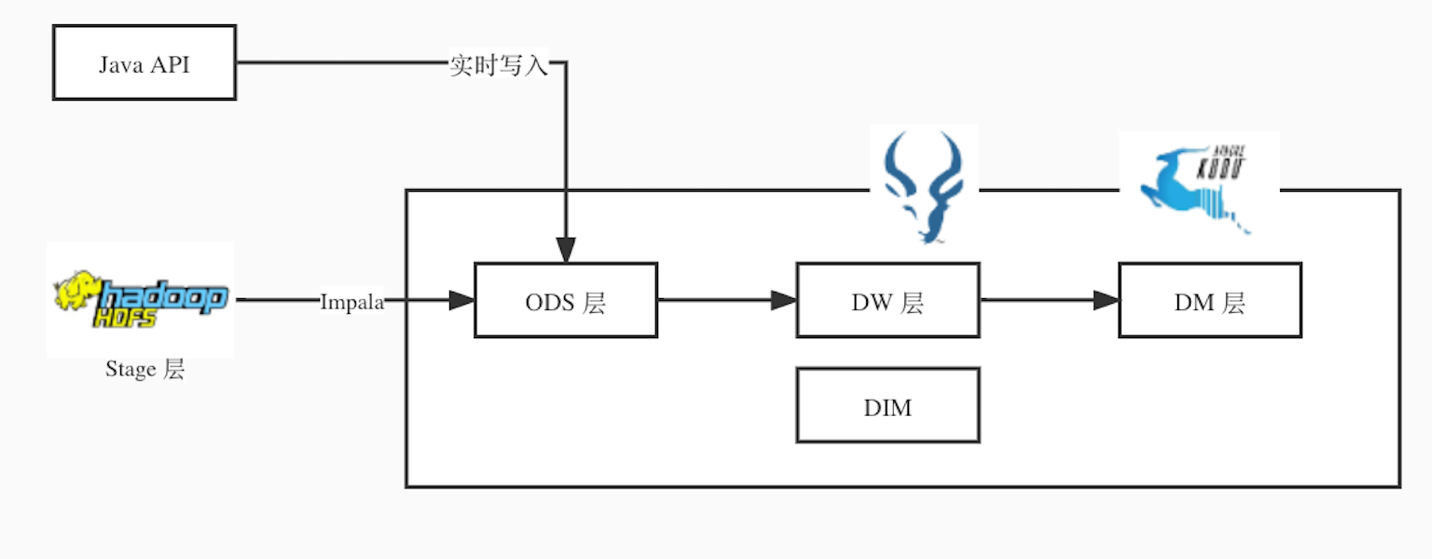
3.1. 在Kudu里的实现
从架构图上可以看出,对数据的操作分成两部分,Impala JDBC写入Kudu,这部分就是纯SQL语句; Java API实时写入Kudu, 这部分代码可以参考2.1章节中的例子。
3.2. 在Hudi里的实现
我们将实时数仓的架构设计中的Impala + Kudu替换为Spark + Hudi.
修改后的架构图如下:

涉及的代码重构的部分有三块:
- JavaAPI原来直接写入Kudu的,现在改成写入Kafka
- Spark Streaming 从Kafka 读取数据写入Hudi表
- 数据仓库各个层之间的数据ETL,原来是用Impala SQL操作Kudu实现,现在改为Spark Streaming读写 Hudi表数据
其中1.的代码可以参考:https://github.com/xudalei1977/cdh-example .
第2.部分里,从Kafka读取数据写入ODS层的测试代码如下:
第3.部分,从ODS层读取数据写入DW层的测试代码如下:
完整的测试代码请参考:https://github.com/xudalei1977/emr-hudi-example , 请注意,这些测试代码只是为了展示基本的功能,省略去了业务处理逻辑的部分。
3.3. 组件对比
在实时数仓的场景下,Kudu和Hudi两种组件的对比如下:
| 对比内容 | Kudu | Hudi |
| 存储 | 本地存储,无法实现存算分离和容灾备份 | 可以存储在HDFS和对象存储 (例如S3) |
| 弹性计算 | 无 | 可以通过Auto Scaling 实现 |
| 开发便捷 | Impala SQL开发比较简单 | Spark Dataframe 需要编程基础 |
| 增量查询 | 无,需要使用SQL从全量数据中过滤 | 提供基于Instant Time的增量查询 |
| 随机读写 | 可以把Kudu看作一个数据库,通过Java API查询即时写入的数据 | 需要借助Spark/Trino JDBC来实现随机读写 |
4、数据迁移
前面章节介绍了从Kudu到Hudi的相关代码的改造,同时还需要把现存的位于Kudu的数据,迁移到Hudi上来。
我们将根据不同的数据表类型,数据的量级,为客户推荐不同的迁移方案。
4.1. 迁移方案
首先,根据表的类型,选择不同的迁移方式:
- 事实表(Fact) : 初始数据的批量迁移,并通过写入Kafka的方式,实现增量数据迁移
- 维度表(Dim) : 数据变化不大,可以一次性全量迁移
- 聚合表(Aggregation) : 通过事实表和维度表计算得来,可以不用迁移,采用在目标数据库中重新计算的方式获取
其次,根据数据的量级,对于初始数据的批量迁移,可以选择不同的迁移方式:
| 数据量 | 专线 | Snowball | 采用Spark 直接读写 | 采用Kudu Export + Spark 读写 |
| < 1 TB | 推荐 | Spark读取Kudu表数据,写入 Hudi表 | ||
| < 1 PB | 推荐 | 推荐 | Spark读取Kudu表数据,写入 Hudi表 | Kudu把数据导出到Parquet文件, 迁移到S3上,使用Spark写入Hudi表 |
| > 1 PB | 推荐 | Kudu把数据导出到Parquet文件, 迁移到S3上,使用Spark写入Hudi表 |
实现数据迁移的流程图如下:
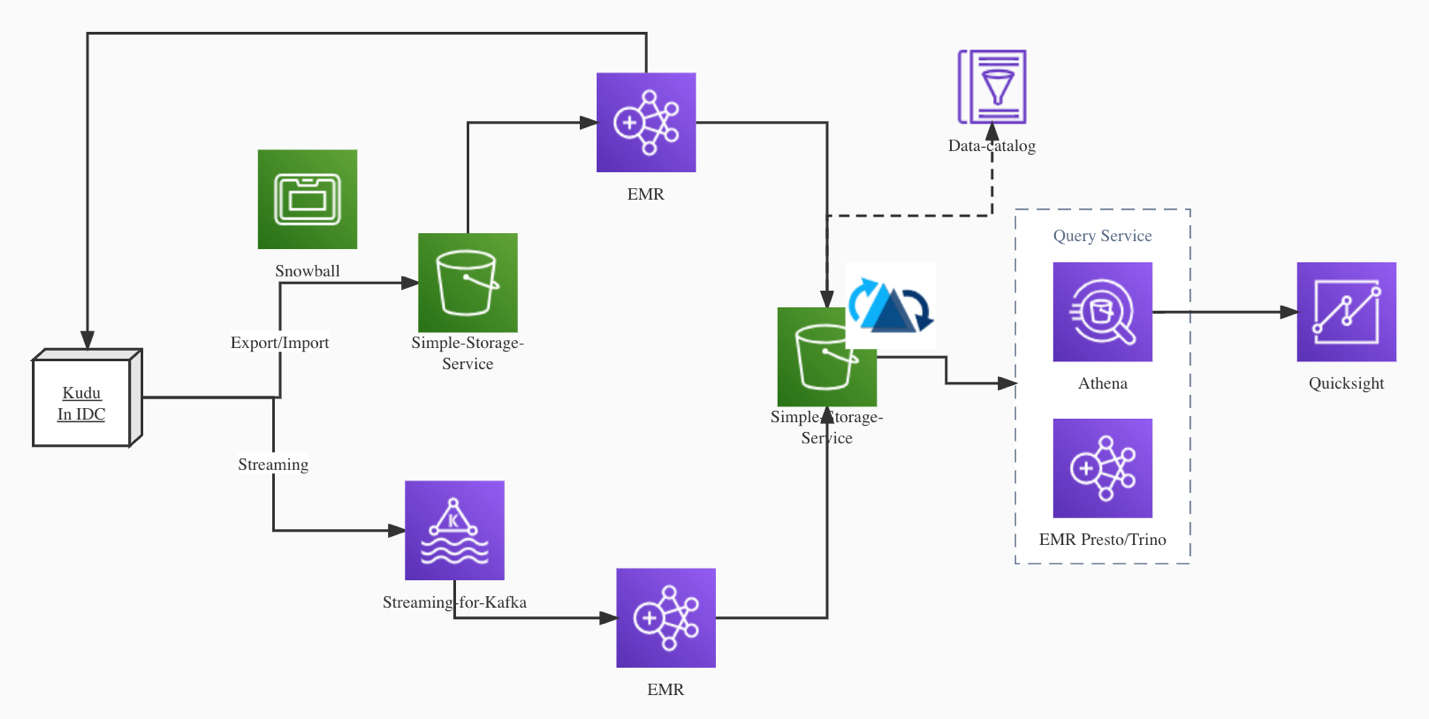
4.2. 具体例子
我们来看一个实际的例子,把Kudu里的TPCDS测试数据的24张表,迁移到位于S3上Hudi表里。由于测试数据的量级是100G,所以我们采用从EMR Spark直接读取Kudu表,并写入Hudi表的方式来迁移数据。整个迁移过程耗时2小时以内。
迁移的数据源和目标数据库的环境如下:
| 环境 | 数据源 | 目标数据库 |
| 组件版本 | Kudu 1.10.0 | Hudi 0.10.0 (通过代码中 –packages 指定) |
| 平台 | CDH 6.3.2 | EMR 5.35.0 |
| 其它组件 | Impala 3.2.0, Spark 2.4.5 | Presto 0.267, Spark 2.4.8 |
| 硬件资源 | 8 nodes m5.2xlarge | 8 core nodes, m6g.2xlarge |
在确定CDH和EMR之间的网络连通后,开始执行迁移,具体步骤包括:
- 初始数据的批量迁移,使用EMR 中Spark读取CDH 平台上的Kudu表,写入Hudi表
- 将Kudu表的增量数据写入Kafka, 使用 EMR中Spark读取Kafka数据,写入Hudi表
- 对聚合表启动实时计算
- 迁移完成后,对比数据源和目标数据库中的数据量
步骤1.中初始化迁移的代码片段如下:
在代码中,先把指定Kudu数据库里的表选出来,然后根据Kudu表的定义,来生成Hudi表的Schema, 包括主键和分区键。这里简单的把带分区的表看作Mor表,不带分区的表看作Cow表,读者可以自己添加更加复杂的逻辑。
在确定了Hudi表的类型、Schema后,调用包函数把数据写入Hudi表。
步骤2. 中把Kudu表的增量数据写入Kafka的代码片段如下:
开发者可以通过params.filterString 来筛选增量数据。
步骤2. 中从Kafka读取增量数据写入Hudi的代码片段如下:
上面的代码中,对Kafka的Topic采用了匹配模式,可以一次读取多个Kudu表的增量数据。
完整的测试代码请参考:https://github.com/xudalei1977/emr5-hudi-example .
4.3. 问题总结
4.3.1. 版本的问题
Spark 3.x 不能读取CDH 6.3.2 上 Kudu 1.10.0的数据,所以使用EMR 5.35.0来读取,写入Hudi的时候可以通过spark-submit命令的–packages选项来指定Hudi版本为0.10.
4.3.1. 执行错误: org.apache.hudi.exception.HoodieException: (Part -) field not found in record. Acceptable fields were…….
这是因为从Kudu读出的数据,不包含precombine key导致的,可以在代码中添加一个字段作为precombine key, 值可以取当前的时间。
4.3.1. 执行错误:Caused by: java.lang.IllegalArgumentException: Can not create a Path from an empty string…….
如果Kudu没有使用Partition, 这个错会出现在Spark 2.4.8 (EMR 5.35.0) 中。考虑到没有使用Partition的表都比较小,所以全量写入Kafka, 然后从Spark 3.1.2 (EMR 6.5.0) 中读取Kafka 并写入Hudi.
4.3.1. 执行错误:To_json does not include “null” value field
由于写入Kafka的数据 (value字段是json格式) 没有包含null值的字段,所以跟Hudi表的Schema对不齐,可以在从Kudu表写入Kafka的时候,指定包含null值的字段。也可以先从已有的Hudi表读取Schema来解析Kafka的数据,然后再写入Hudi表。
5、对于使用Kudu和Hudi的一些建议
5.1. 哪些场景适合使用Kudu?
适合Kudu的场景包括:
- 同时提供OLTP和OLAP 查询的场景
- 高并发随机查询,尤其是查询即时写入的数据的场景
- 用来做热数据的场景,不需要考虑数据丢失的问题
- 简单、自用的数据仓库开发
- 重度依赖SQL的业务人员的常用场景
5.2. 哪些场景适合使用Hudi?
适合Hudi的场景包括:
- 注重实现弹性计算和数据安全的场景
- 智能湖仓的场景
- 大量使用增量查询的场景,例如较复杂的实时数仓
- 将数据保存在对象存储 (例如S3) 上,实现多个服务组件之间数据共享的场景
- 使用主流开源技术栈的开发场景
5.3. 可以在EMR上直接部署Kudu吗?
可以在EMR上直接部署社区版本的Impala和Kudu, 但是不推荐这样做,这样不但增加了运维的工作,还会影响EMR节点的自动扩缩容。
5.4. EMR上使用Hudi的版本
EMR上提供的Hudi依赖的jar包,其版本可以参考 https://docs.aws.amazon.com/emr/latest/ReleaseGuide/Hudi-release-history.html , 通常来说,EMR上支持的Hudi版本会比社区稍晚一点,很多开发者喜欢在EMR使用社区的Hudi版本,这在EMR 6.5.0 以前是没有问题的。之后的EMR版本,修改了Spark操作PartitionedFile类的接口,导致与社区版本的Hudi不兼容,所以还是推荐使用EMR自带的Hudi依赖Jar包,而不是通过–packages来指定社区版本Hudi.
5.5. 总结一下迁移的好处
总的来说,从CDH上的Kudu迁移到EMR上的Hudi, 有如下好处:
- 云原生:存算分离,弹性扩缩,成本优化
- 稳定性:托管服务,高可用性,减少运维
- 开放性:社区开源组件
参考文档:
https://hudi.apache.org/docs/indexing
https://kudu.apache.org/docs/security.html
https://kudu.apache.org/docs/known_issues.html
{kind=link}
https://blog.cloudera.com/how-to-use-impala-with-kudu/
https://docs.aws.amazon.com/emr/latest/ReleaseGuide/Hudi-release-history.html
https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-hudi.html
https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-presto.html