亚马逊AWS官方博客
让你的数据库流动起来 – 利用MySQL Binlog实现流式实时分析架构
数据分析特别是实时数据分析,已经越来越多的成为各行各业的分析要求与标准 – 例如,(新)零售行业可能希望通过线下POS数据与实时门店客流流量的进行实时结合与分析,实现商品销售,销量,总类等等的实时预测; 在线广告平台期望通过广告(Impression)总类,数据量以及基于时间的点击(Click)量,计算实时的广告转化率(Conversion Rate);物联网的用户想通过实时分析线下的状态设备与设备采集的数据,进行后台的计算与预判 – 例如做一些设备维修的提前预警(Predicative Failure Analysis)与线下用户的使用习惯;电商平台或者是在线媒体需要给终端用户提供个性化的实时推荐等等。
纵观这些业务系统,从数据流的角度看,往往数据架构可以分为前后端两个部分 – 前端的业务数据与日志收集系统(其中业务数据系统一般都是利用关系型数据库实现 – 例如 MySQL,PostgreSQL)与后端的数据分析与处理系统 (例如ElasticSearch 搜索引擎,Redshift数据仓库,基于S3的Hadoop系统 等等,或者基于Spark Stream的实时分析后端)。
“巧妇难为无米炊”,实时数据分析的首要条件是实现实时数据同步,即从上述前端系统到后端系统的数据同步。具体来讲包含两个要求(根据业务场景的不同,实时性会有差异)- 1) 实时 2) 异构数据源的增量同步。实时的要求容易理解 – 无非是前后端系统的实时数据ETL的过程,需要根据业务需求,越快越好。所谓异构数据源的增量同步是指,前端产生的增量数据(例如新增数据,删除数据,更新数据 – 主要是基于业务数据库的场景,日志相对简单,主要是随时间的增量数据)可以无缝的同步到后端的数据系统 – 例如ElasticSearch,S3或者Redshift等。 显然,这里的挑战主要是来自于异构数据源的数据ETL – 直白一点,就是怎么把MySQL(或者其他RDBMS)实时的同步到后端的各类异构数据系统。因为,MySQL的表结构的存储不能简单的通过复制操作实现数据同步。 业界典型的做法大概可以归纳为两类 – 1)通过应用程序双写的架构 (application dual-writes) 2) 利用流式架构实现数据同步,即基于流式数据的Change Data Caputre (CDC) 。 双写架构实现简单,利用应用逻辑实现,但是要保证数据一致性相对复杂(需要通过二阶段提交实现 – two phase commit),而且,架构扩展相对比较困难 – 例如增加新的数据源,数据库等。 利用流式数据重构数据,越来越成为很多用户与公司的实时数据处理的架构演化方向。 MySQL的Binlog,以日志方式记录数据变化,使这种异构数据源的实时同步成为可能。 今天,我们主要讨论的是如何利用MySQL的binlog实现流式数据同步。
MySQL Binlog数据同步原理
讲了这么多,大家看张图。 我们先了解一下MySQL Binlog的基本原理。 MySQL的主库(Master)对数据库的任何变化(创建表,更新数据库,对行数据进行增删改),都以二进制文件的方式记录与主库的Binary Log(即binlog)日志文件中。从库的IO Thread异步地同步Binlog文件并写入到本地的Replay文件。SQL Thread再抽取Replay文件中的SQL语句在从库进行执行,实现数据更新。 需要注意的是,MySQL Binlog 支持多种数据更新格式 – 包括Row,Statement,或者mix(Row和Statement的混合)。我们建议使用Row这种Binlog格式(MySQL5.7之后的默认支持版本),可以更方便更加实时的反映行级别的数据变化。

如前所述,MySQL Binlog是MySQL主备库数据同步的基础,因为Binlog以日志文件的方式,记录了数据库的实时变化,所以我们可以考虑类似的方法 – 利用一些客户端工具,把它们伪装成为MySQL的Slave(备库)进行同步。
基于Binlog的流式日志抽取的架构与原理
在我们这个场景中, 我们需要利用一些客户端工具“佯装”成MySQL Slave,抽取出Binlog的日志文件,并把数据变化注入到实时的流式数据管道中。我们在管道后端对Binlog的变化日志,进行消费与必要的数据处理(例如利用AWS的Lambda服务实现无服务器的代码部署),同步到多种异构数据源中 – 例如 Redshift, ElasticSearch, S3 (EMR) 等等。具体的架构如下图所示。

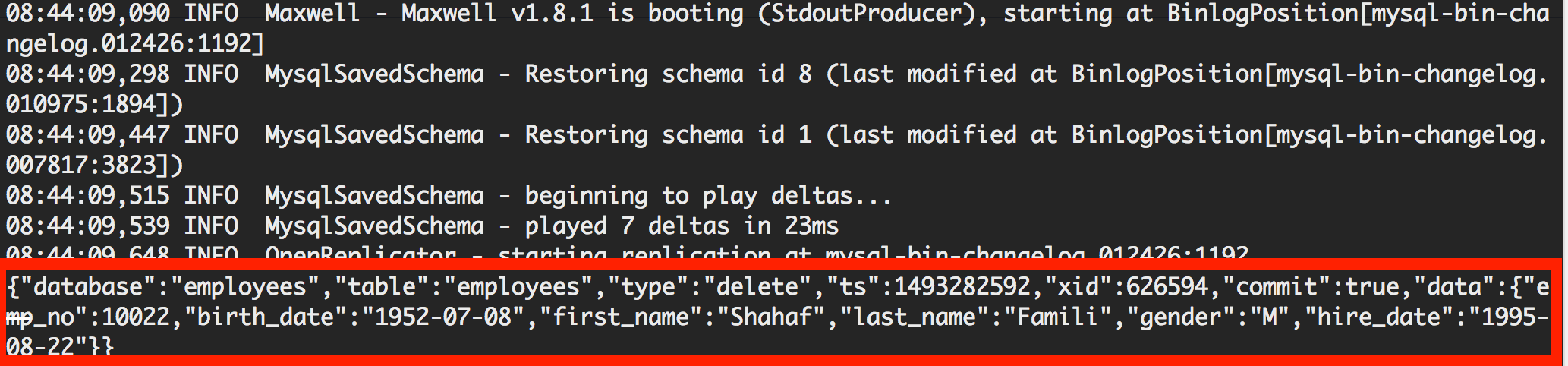
这里需要给大家介绍一个比较好的MySQL的Binlog的抽取工具 Maxwell’s Daemon。这款由Zendesk开发的开源免费(http://maxwells-daemon.io/) Binlog抽取工具可以方便的抽取出MySQL (包括AWS RDS)的变化数据,方便的把变化数据以JSON的格式注入到后端的Kafka或者Amazon Kinesis Stream中。我们把RDS MySQL中的Binlog输出到控制台如下图所示 – 下图表示从employees数据库的employees数据表中,删除对应的一行数据。
在上述架构中,我们利用Lambda实时读取Amazon Kinesis Stream中的MySQL Binlog日志,通过Kinesis Firehose实时地把MySQL binlog的结构数据自动化地同步到S3和Redshift当中。值得注意的是,整个架构基于高可用和自动扩展的理念 – Kinesis Stream( 高可用),Lambda(Serverless与自动扩展),Kinesis Firehose(兼具高可用与自动扩展)。Kinesis Stream作为统一的一个数据管道,可以通过Lambda把数据分发到更多的数据终点 – 例如,ElasticSearch或者DynamoDB中。
动手构建实时数据系统
好了,搞清楚上面的架构,我们开始动手搭建一个RDS MySQL的实时数据同步系统吧。这里我们将把MySQL的数据变化(包括具体的行操作 – 增删改)以行记录的方式同步到Redshift的一张临时表,之后Redshift会利用这种临时表与真正的目标表进行合并操作(Merge)实现数据同步。
1) 配置AWS RDS MySQL的Binlog同步为Row-based的更新方式: 在RDS的参数组中,设置binglog_format为Row的格式。如下图所示。

2) 另外,我们可以利用AWS RDS提供的存储过程,实现调整Binlog在RDS的存储时间为24个小时。我们在SQL的客户端输入如下命令:
call mysql.rds_set_configuration('binlog retention hours', 24)
3) 在这里我们通过如下的AWS CLI,快速启动一个stream(配置CLI的过程可以参考http://docs.aws.amazon.com/cli/latest/userguide/installing.html,并且需要配置AWS 的用户具有相应的权限,为了方便起见,我们在这个测试中配置CLI具有Administrator权限):这里我们创建了一个名为mysql-binlog的kinesis stream 同时配置对应的shard count为1。
aws kinesis create-stream –stream-name mysql-binlog –shard-count 1
4) Maxwell’s Daemon提供了Docker的封装方式,在EC2运行如下Docker command就可以方便的启动一个Maxwell’s Daemon的客户端。其中,蓝色字体部分代表对应的数据库,region与kinesis stream等。
docker run -it --rm--name maxwell-kinesis
-v `cd && pwd`/.aws:/root/.aws saidimu/maxwell sh -c 'cp /app/kinesis-producer-library.properties.example
/app/kinesis-producer-library.properties && echo "Region=AWS-Region-ID" >>
/app/kinesis-producer-library.properties && /app/bin/maxwell
--user=DB_USERNAME --password=DB_PASSWORD --host=MYSQL_RDS_URI
--producer=kinesis --kinesis_stream=KINESIS_NAME '
5) 有了数据注入到Kinesis 之后,可以利用Lambda对kinesis stream内部的数据进行消费了。Python代码示例如下。需要注意的是,我们这里设置Lambda的trigger是Kinesis Stream(这里我们对应的Kinesis Stream的名字是mysql-binlog),并且配置对应的Lambda访问Kinesis Stream的batch size 为1。这样,对应的数据实时性可能更快,当然也可以根据需要适度调整Batch Size大小。具体的配置过程可以参考 – http://docs.aws.amazon.com/lambda/latest/dg/get-started-create-function.html
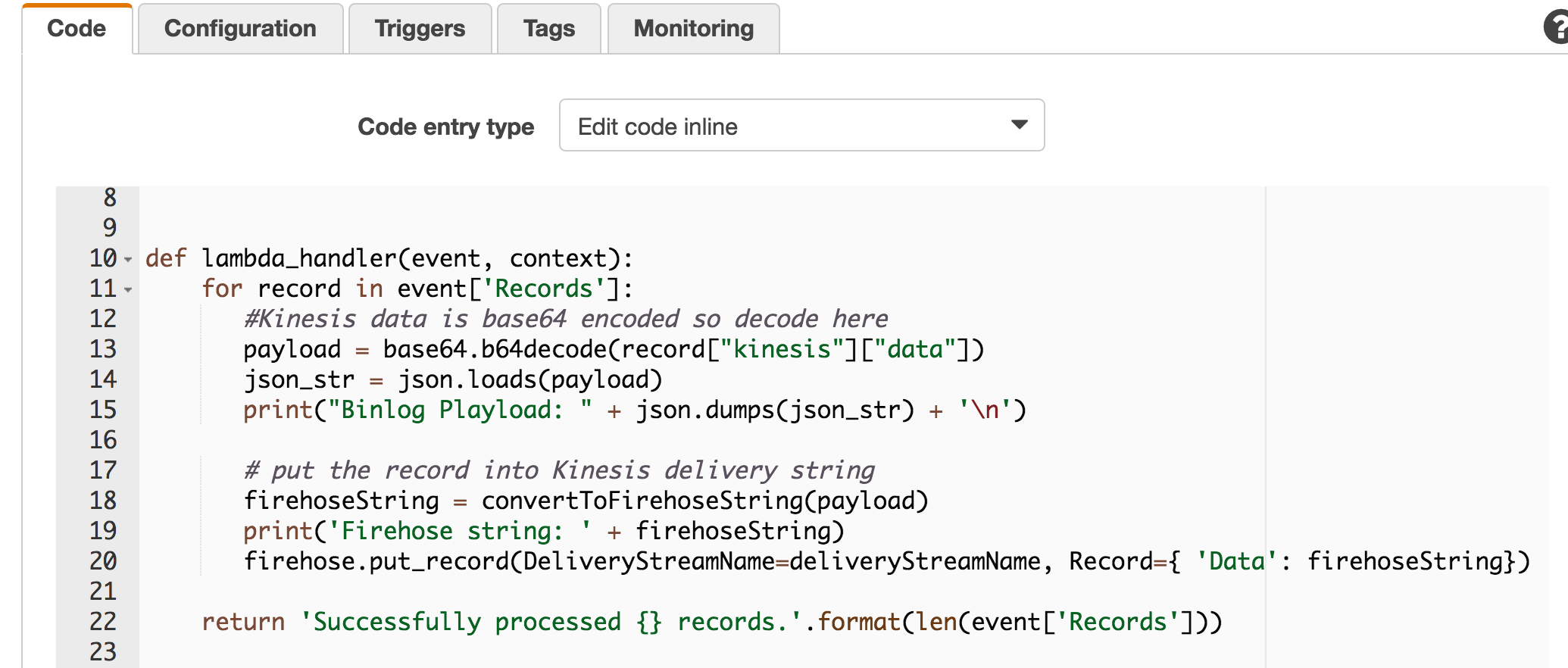
上述代码(Python 2.7 runtime)的主要功能实现从Kinesis Stream内部读取base64编码的默认binlog data。之后遍历Kinesis Stream中的data record,并直接写入 Kinesis Firehose中。
6) 接着,我们可以通过配置Kinesis Firehose把lambda写入的数据同步复制到S3/Redshift 中。具体的配置细节如下。配置细节可以参考 http://docs.aws.amazon.com/firehose/latest/dev/basic-create.html#console-to-redshift

其中,通过S3 buffer interval来指定往S3/Redshift中注入数据的平率,同时,Copy Command用来指定具体的Redshift的Copy的操作与对应的Options,例如(我们指定逗号作为原始数据的分隔符 – 在lambda内部实现)。
至此,我们已经可以实现自动化地从MySQL Binlog同步变量数据到Redshift内部的临时表内。好了,可以试着从MySQL里面delete 一行数据,看看你的Redshift临时表会发生什么变化?
还有问题? 手把手按照github上面的code 走一遍吧 – https://github.com/bobshaw1912/cdc-kinesis-demo
作者介绍

肖凌
AWS解决方案架构师,负责基于AWS的云计算方案架构的咨询和设计,同时致力于AWS云服务在国内和全球的应用和推广,在大规模并发后台架构、跨境电商应用、社交媒体分享 、Hadoop大数据架构以及数据仓库等方面有着广泛的设计和实践经验。在加入AWS之前曾长期从事移动端嵌入式系统开发,IBM服务器开发工程师。并负责IBM亚太地区企业级高端存储产品支持团队,对基于企业存储应用的高可用存储架构和方案有深入的研究。