亚马逊AWS官方博客
Apache Hudi 0.7.0 和 0.8.0 新功能已在 Amazon EMR 中可用
Apache Hudi 是一个开源事务性数据湖框架,通过提供记录级插入、更新和删除功能,极大地简化了增量数据处理和数据管道开发。如果您要在 Amazon Simple Storage Service (Amazon S3) 或 HDFS 上构建数据湖,此记录级别功能将非常有用。您可以使用它来遵守数据隐私法规,并简化处理来自流式处理数据源的迟到记录或更新记录的数据提取管道,或者使用更改数据捕获 (CDC) 从事务处理系统提取数据。Apache Hudi 支持与 Apache Spark、Apache Hive、Presto 和 Trino 等开源大数据分析框架集成。它允许您以开放格式(如 Apache Parquet 和 Apache Avro)维护 Amazon S3 或 HDFS 中的数据。
从发行版 5.28.0 开始,Amazon EMR 将在您安装 Spark、Hive、Presto 或 Trino 时默认安装 Hudi 组件。自从将 Apache Hudi 纳入 Amazon EMR 以来,Apache Hudi 已经添加了几项改进和错误修复。Apache Hudi 于 2020 年 6 月被评为顶级 Apache 项目。
在这篇文章中,我们总结了自 Apache Hudi 发行版 0.7.0 和 0.8.0 以来添加的一些关键新特性和功能。自 Amazon EMR 5.33.0 和 6.3.0 发布以来,已推出 Hudi 的以下新特性和功能:
- 聚类
- 基于元数据的文件列表
- Amazon CloudWatch 集成
- Optimistic Concurrency Control
- Amazon EMR 配置支持和改进
- Apache Flink 集成
- Kafka 提交回调
- 其他改进功能
聚类
我们看看更多需要将高吞吐量引入数据湖的使用场景。但是,更快的数据摄入通常会导致较小的数据文件大小,这往往会对查询性能产生不利影响,因为大量的小文件会增加返回结果所需的成本高昂的 I/O 操作。我们看到的另一个问题是,摄入期间的数据组织与查询数据时效率最高的组织不同。例如,通过 OrderDate 接收电子商务订单很方便,但是在查询时,最好将单个客户的订单存储在一起。
Apache Hudi 0.7.0 版本引入了一项新功能,允许您对 Hudi 表进行聚类。Hudi 中的聚类是一个框架,它提供了一种可插式策略来更改和重组数据布局,同时优化文件大小。借助聚类,您现在可以优化查询性能,而不必权衡数据摄入吞吐量。
您可以根据不同的使用场景要求,通过聚类使用不同的方法来重写数据:
- 利用数据本地性提高查询性能 – 这会通过对一个或多个用户指定列中的数据进行排序来更改磁盘上的数据布局。通过这种方法,我们可以使用 Parquet 文件格式执行谓词下推并跳过不需要的文件和 Parquet 行组,以提高查询性能。此策略还可以控制文件大小来避免小文件。
- 提高数据新鲜度 – 此要求假定数据本地性在摄取时并不重要或已得到处理。它非常适合于新鲜数据很重要的使用场景,在这种情况下,使用几个小文件提取数据,然后使用聚类框架进行拼接或合并。
您可以异步或同步运行聚类表服务。它还引入了新的操作类型 REPLACE,用于标识 Hudi 元数据时间轴中的聚类操作。
在以下示例中,我们使用 Amazon EMR 发行版 6.3.0 创建了两个写时复制 (CoW) Hudi 表:amazon_reviews 和 amazon_reviews_clustered。
我们使用 spark-shell 来创建 Hudi 表。通过在 Amazon EMR 主节点上运行以下命令来启动 Spark shell:
然后,我们在不启用聚类的情况下使用 BULK_INSERT 操作创建 Hudi 表 amazon_reviews:
然后,我们使用 BULK_INSERT 操作创建 Hudi 表 amazon_reviews_clustered 并内联按列 star_rating 和 total_votes 启用和排序的聚类:
让我们来查询这两个表并验证性能差异。为了验证性能,我们将使用 Spark SQL CLI,后者是一种方便的工具,可以在本地模式下运行 Hive 元存储服务并执行从命令行输入的查询。要启动 Spark SQL CLI,我们执行以下命令:
我们在每次运行之间重新启动 Spark SQL CLI (spark-sql) 会话,以避免可能会影响查询性能的缓存或热执行器。
让我们在 spark-sql 接口中运行以下命令,对非聚类 Hudi 表运行查询:
我们还从 spark-sql 接口对聚类表运行同样的查询:
我们比较两个不同 Hudi 表的基础文件扫描性能。以下屏幕截图是 Spark UI 的输出,其中显示了针对相同数量的输出行扫描的文件中的更改。首先,我们看到为非聚类 Hudi 表扫描的文件。
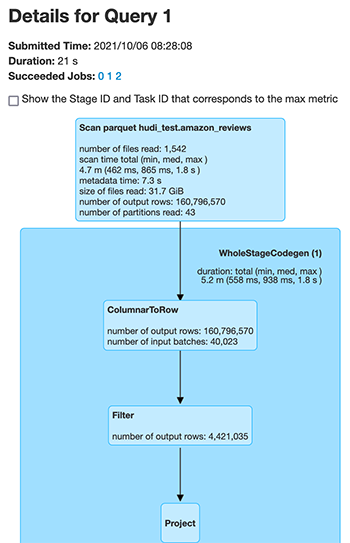
接下来,我们看看为聚类 Hudi 表扫描的文件。
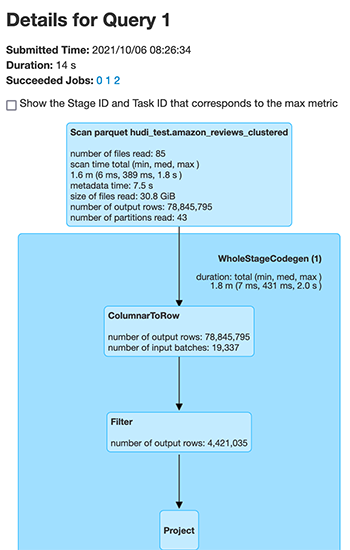
Spark 扫描的文件数量从 1,542 个文件(对于非聚类 Hudi 数据集)减少到 85 个文件(对于完全相同数据的聚类 Hudi 数据集)。此外,扫描的记录数量从 160,796,570 条减少到 78,845,795 条。
我们在 Spark SQL、Hive 和 PrestoDB 间针对 Spark SQL、Hive 和 PrestoDB amazon_reviews(非聚类)和 amazon_reviews_clustered(聚类)比较了上述查询的性能。使用的集群配置是 1 个 leader (m5.4xlarge) 和 2 个内核 (m5.4xlarge)。
以下图表提供了对 Hudi 表(非聚类)和 Hudi 表(聚类)使用不同引擎的查询性能比较。

我们发现,在为 Hudi 表启用聚类后,所有三个查询引擎的查询性能都有所提高,幅度从 28% 到 63% 不等。下表提供了 Hudi 表的查询性能的详细信息,包括启用和禁用聚类的情况。
| 查询引擎 | 非聚簇表 | 聚簇表 | 查询运行时改进 |
| 时间(以秒为单位) | 时间(以秒为单位) | ||
| Spark SQL | 21.6 | 15.4 | 28.7 % |
| Hive | 96.3 | 47 | 51.3 % |
| PrestoDB | 11.7 | 4.3 | 63.25 % |
基于元数据的文件列表
Hudi 写入操作(如压缩、清理和全局索引)以及查询都会执行文件系统列表,以获取数据集中分区和文件的当前视图。对于小型数据集,这应该不会对性能产生重大影响。但是,在处理大数据时,此列出操作可能会在读取文件时对性能产生负面影响。例如,如果将 HDFS 作为底层数据存储,大量文件或分区的列表操作会使 HDFS NameNode 不堪重负,并影响作业的稳定性。在将 Amazon S3 用作底层数据存储的情况下,包含大量文件的 N 个分区的 O(N) 调用非常耗时,还可能导致节流错误。
在 Apache Hudi 0.7.0 版本中,您可以通过为 Hudi 表启用基于元数据的列表来更改此行为。此分区和文件列表存储在内部元数据表中,该表是使用 Hudi Merge on Read (MoR) 表实现的。此元数据表可以充分利用 Hudi MoR 表的所有优势,其中包括低延迟更新功能,以及自动提交元数据更新并在写入失败时轻松回滚的功能。它还使元数据与 Hudi 表保持同步变得容易,因为两者都使用时间轴来实现可追溯性。此文件列表索引使用 HFiles 进行存储,并使用基本和日志文件格式进行增量更新。HFile 格式允许基于记录键对特定记录进行点查找。目标是将对 N 个分区的 O(N) 列表调用减少到 O(1) get 调用以读取元数据。
我们比较了启用元数据清单和未启用元数据清单的 Hudi 数据集的查询性能。在此示例中,我们在 Amazon EMR 发行版 6.3.0 中使用了更大的 3TB 数据集。我们使用以下代码段通过设置 HoodieMetadataConfig.METADATA_ENABLE_PROP (hoodie.metadata.enable) config 来创建已启用和未启用元数据的数据集:
在查询引擎方面,我们可以通过以下方法启用它:
- Spark 数据源:
- Spark SQL CLI:
- Hive:
- PrestoDB:
我们使用以下查询来比较通过 Hive 和 PrestoDB 的查询性能:
以下图表提供了查询性能比较。

我们发现,通过元数据清单,Hive 引擎的查询执行运行时间减少了约 25%,PrestoDB 减少了约 32%。下表提供了带和不带元数据清单的查询执行运行时的详细信息。
| 查询引擎 | 禁用元数据 | 启用元数据 | 查询运行时改进 |
| 时间(以秒为单位) | 时间(以秒为单位) | ||
| Hive | 415.28533 | 310.02367 | 25.35% |
| Presto | 72 | 48.6 | 32.50% |
元数据清单注意事项
对于 Hudi 0.7.0 和 0.8.0,您可能看不到通过 Spark SQL(含元数据清单)进行查询的明显改进,因为 Hudi 依靠 Spark 的 inMemoryFileIndex 来列出实际文件列表,并且无法使用元数据。您可能会观察到改进,因为 HoodieROPathFilter 使用元数据进行过滤。但是,在 Hudi 0.9.0 版本中,我们为 Hudi 引入了自定义 FileIndex 实现,以使用元数据来列出文件,而不是依赖 Spark。因此,从 0.9.0 开始,您将观察到 Spark SQL 查询的性能显著提高。
Amazon CloudWatch 集成
Apache Hudi 提供了 MetricsReporter 实现,例如 JmxMetricsReporter、MetricsGraphiteReporter 和 DatadogMetricsReporter,您可以使用它们将指标发布到用户指定的接收器。Amazon EMR(其发行版 6.4.0 具备 Hudi 0.8.0)推出了 CloudWatchMetricsReporter,供您向 Amazon CloudWatch 发布这些指标。它有助于发布 Hudi 写入器指标,例如提交持续时间、回滚持续时间、文件级指标(每次提交添加或删除的文件数)、记录级指标(每次提交插入或更新的记录)和分区级指标(每次提交插入或更新的分区)。这在调试 Hudi 作业以及制定集群扩缩决策时非常有用。
您可以通过以下配置启用 CloudWatch 指标:
下表总结了您可以根据需要更改的其他配置。
| 配置 | 描述 | 值 |
| hoodie.metrics.cloudwatch.report.period.seconds | 向 CloudWatch 报告指标的频率(以秒为单位) | 默认值为 60 秒,对于 CloudWatch 提供的默认 1 分钟分辨率来说,没有问题 |
| hoodie.metrics.cloudwatch.metric.prefix | 要添加到每个指标名称的前缀 | 默认值为空(无前缀) |
| hoodie.metrics.cloudwatch.namespace | 在其中发布指标的 CloudWatch 命名空间 | 默认值为 Hudi |
| hoodie.metrics.cloudwatch.maxDatumsPerRequest | 一次向 CloudWatch 发出的请求中包含的基准数上限 | 默认值为 20,与 CloudWatch 的默认值相同 |
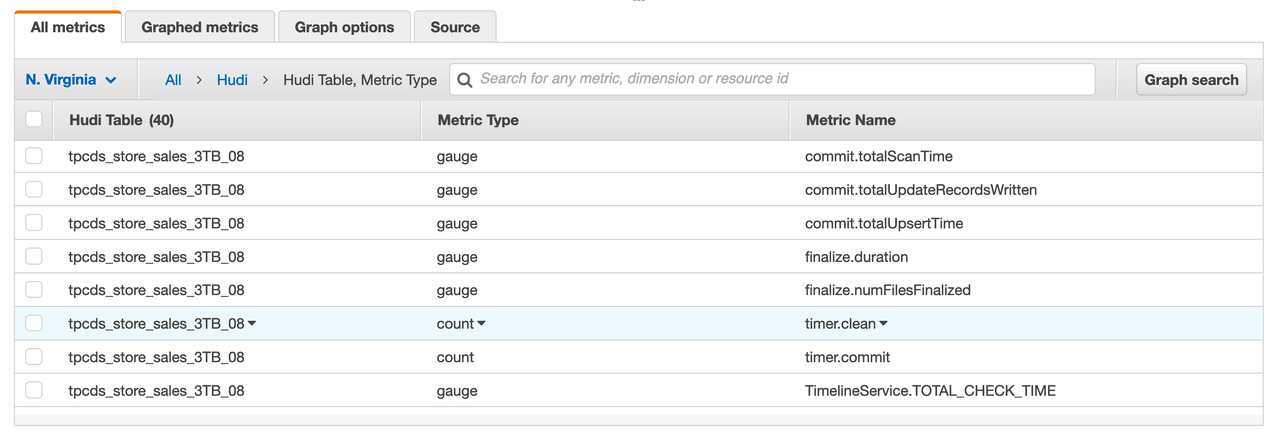
以下屏幕截图显示了针对特定 Hudi 表发布的一些指标,包括指标的类型及其名称。这些是 dropwizard 指标;gauge 表示某个时间点的精确值,而 counter 表示一个简单的递增或递减整数。
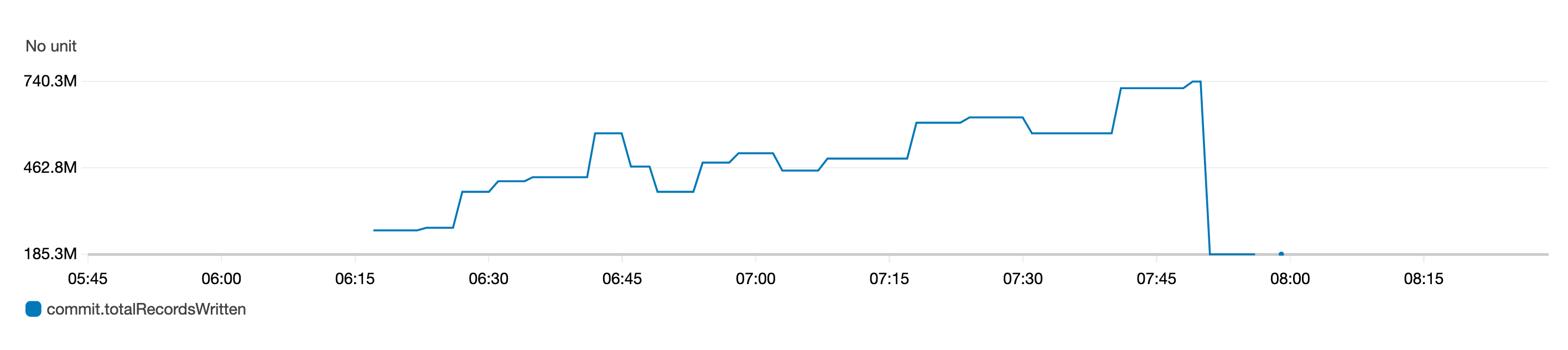
下面的 gauge 指标图表示一段时间内写入表的记录总数。
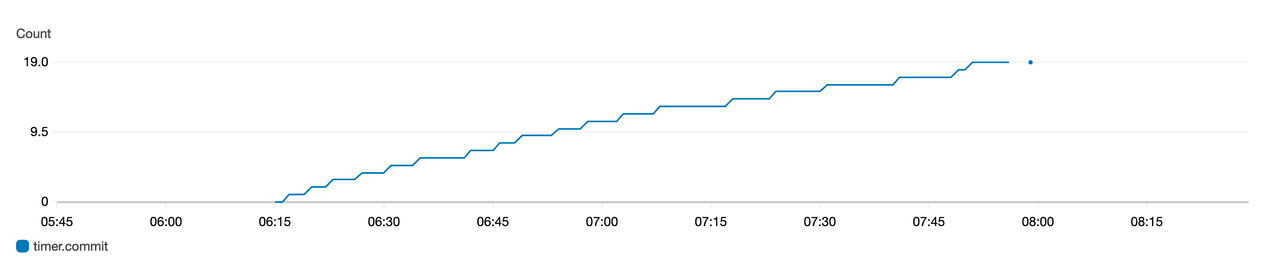
下面的 counter 指标图表表示随着时间的推移而增加的提交次数。
Optimistic Concurrency Control
在 Hudi 0.8.0 中引入的一项主要功能是 Optimistic Concurrency Control (OCC),它允许多个写入器同时将数据提取到同一 Hudi 表中,该功能自 Amazon EMR 6.4.0 版本以来一直可用。这是文件级 OCC,这意味着对于同时发生在同一个表中的任意两个提交(或写入器),如果这两个提交(或写入器)没有写入重叠的文件,则允许它们成功。该功能需要获取锁,为此您可以使用 Zookeeper 或 HiveMetaStore。有关所提供保证的更多信息,请参阅并发控制。
Amazon EMR 集群安装了 Zookeeper,您可以将其用作锁提供程序,从同一集群执行并发写入。为方便使用,Amazon EMR 在新推出的 /etc/hudi/conf/hudi-defaults.conf 文件(请参阅下一节)中通过以下属性预配置锁提供程序:
尽管锁定提供程序已预先配置,但用户仍然需要通过 Hudi 作业选项或在集群级别通过 Amazon EMR 配置 API 来处理 OCC 的启用:
Amazon EMR 配置支持和改进
Amazon EMR 发行版 6.4.0 引入了通过配置功能配置和重新配置 Hudi 的功能。现在,作业和表中所需的 Hudi 配置可在集群级别通过 hudi-defaults classification or /etc/hudi/conf/hudi-defaults.conf 文件进行配置,类似于 Spark 和 Hive 等其他应用程序。以下代码是启用基于元数据的列表和 CloudWatch 指标的 hudi-defaults 分类的示例。
Amazon EMR 会自动为一些配置设置合适的默认值,从而让客户无需传递这些值,以改善用户体验:
- HIVE_URL_OPT_KEY 已配置为集群的 Hive 服务器 URL,不再需要指定。这在 Spark 集群模式下运行作业时特别有用,在此模式下,用户以前必须确定并自己指定 Amazon EMR 主 IP。
- 特定于 HBase 的配置,这些配置对于将 HBase 索引与 Hudi 结合使用非常有用。
- 如并发控制部分所述,Zookeeper 锁定提供程序特定配置可让您更轻松地使用 OCC。
引入了其他更改,以减少用户需要传递的配置数量,并在可能的情况下自动推断:
- 现在可以使用 partitionBy API 来指定分区列。
- 启用 Hive Sync 时,不再需要传递 HIVE_TABLE_OPT_KEY、HIVE_PARTITION_FIELDS_OPT_KEY 或 HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY。这些配置可以从 Hudi 表名和分区字段本身推断出来。
- 如果您使用的是
SimpleKeyGenerator或ComplexKeyGenerator,KEYGENERATOR_CLASS_OPT_KEY 不是强制传递的,并且可以根据有单个还是多个记录键列来推断。
Apache Flink 集成
Apache Hudi 一开始就与 Apache Spark 进行了非常紧密的集成。在 0.7.0 版本中,我们现在利用集成使用 Apache Flink 提取数据。它需要将 Spark 与内部表格格式、写入器和表服务代码分离,以供业内其他不断发展的引擎(如 Flink)使用。
Hudi 0.7.0 通过 HooodieFlinkStreamer 提供初始 Flink 支持,借助它,您可以使用 Apache Flink 流式传输来自 Kafka 主题的数据以编写 CoW 表。例如,您可以使用以下 Flink 命令开始阅读在端口 9092 上运行的 Kafka 代理 broker-1、broker-2 和 broker-3 中的 ExampleTopic 主题:
在 Hudi 0.8.0 中,Flink 集成性能和可扩展性有了重大改进,并且引入了新功能,例如用于源和接收器的 SQL 连接器、用于 MoR 的写入器、用于 CoW 和 MoR 的批处理读取器、用于 MoR 的流式传输读取器以及带 Bootstrap 框架支持的状态支持的索引。有关 Flink 集成设计的更多信息,请参阅 Apache Hudi 遇见 Apache Flink。要开始使用 Flink SQL,请参阅 Flink 指南。
Kafka 提交回调
以前的 Apache Hudi 版本 (0.6.0) 引入了写入提交回调功能。有了此功能,Hudi 可以在每次成功提交到 Hudi 数据集时发送回调消息。在以前的版本中,写提交回调支持 HTTP 方法。在 Apache Hudi 0.7.0 版本中,Hudi 现在也支持 Kafka 的写入提交回调。现在,使用 Kafka 为每次成功提交发送回调消息,可以让您在每次 Hudi 数据集看到新提交时构建异步数据管道或业务处理逻辑。现在,您可以构建增量 ETL 管道来处理到达 Hudi 数据湖的新事件。
Kafka 提交回调的实现使用 HoodieWriteCommitKafkaCallback 作为 the hoodie.write.commit.callback.class。除了设置提交回调类之外,您还可以为 Kafka Bootstrap 框架服务器和主题配置设置额外的参数。
以下是一个代码段,写入 Hudi 数据集时,提交回调消息会发布到托管在 Kafka 代理 b-1.demo-hudi.xxxxxx.xxx.kafka.us-east-1.amazonaws.com、b-2.demo-hudi.xxxxxx.xxx.kafka.us-east-1.amazonaws.com 和 b-3.demo-hudi.xxxxxx.xxx.kafka.us-east-1.amazonaws.com 上的 Kafka ExampleTopic 主题:
以下是这些消息在 Kafka 主题中的显示方式:
下游管道现在可以轻松地从 Kafka 查询这些事件,并将增量数据处理到派生的 Hudi 表中。
其他改进功能
除了上述改进之外,还有一些其他的变化值得一提。在写入器方面,有以下改进:
- 支持 Spark 3 – 支持使用 Apache Spark 3 写入和查询数据,从 Apache Hudi 0.7.0 开始提供。这适用于
hudi-spark-bundle的 Scala 2.12 捆绑。 - 插入覆盖和插入覆盖表写入操作 – Apache Hudi 0.7.0 引入了两个新操作:
insert_overwrite和insert_overwrite_table以支持整个表或分区在每次执行时会被覆盖的批处理 ETL 作业。您可以使用这些操作而非upsert操作,而且运行成本必须更低。 - 删除分区 – 从 0.7.0 开始,新的 API 现在可用于删除整个分区。这有助于避免使用记录级删除。
- Java 写入器支持 – Hudi 0.7.0 通过
HoodieJavaWriteClient类引入了基于 Java 的写入支持。
同样,在查询集成方面,也进行了以下改进:
- 结构化串流读取 – Hudi 0.8.0 通过
HoodieStreamSource类引入了 Spark 结构化串流源实现。您可以使用它来支持从 Hudi 表中进行串流读取。 - MoR 上的增量查询 – 从 Hudi 0.7.0 开始,我们现在有了对 MoR 表的增量查询支持,您可以使用该查询通过下游应用程序以递增方式提取数据。
结论
借助 Apachi Hudi 中引入的新功能,您能够结合使用 Kafka 提交回调以及 Flink 与 Apache Hudi 的集成和 Amazon EMR 等功能来构建分离的解决方案。您还可以通过使用聚类表和元数据表的功能来提高 Hudi 数据湖的整体性能。
关于作者
 Udit Mehrotra 是 Amazon Web Services 的一名软件开发工程师和 Apache Hudi PMC 成员/提交者。他致力于开发 Amazon EMR 前沿功能,并参与了 Apache Hudi、Apache Spark、Apache Hadoop 和 Apache Hive 等开源项目。闲暇之余,他喜欢弹吉他、旅行、刷剧以及和朋友一起出去玩。
Udit Mehrotra 是 Amazon Web Services 的一名软件开发工程师和 Apache Hudi PMC 成员/提交者。他致力于开发 Amazon EMR 前沿功能,并参与了 Apache Hudi、Apache Spark、Apache Hadoop 和 Apache Hive 等开源项目。闲暇之余,他喜欢弹吉他、旅行、刷剧以及和朋友一起出去玩。
 Gagan Brahmi 是一名解决方案构架师,在 Amazon Web Services 主要从事大数据和分析工作。Gagan 拥有超过 16 年的信息技术行业从业经验。他帮助客户在 AWS 上设计和构建高度可扩展、高性能且安全的基于云的解决方案。
Gagan Brahmi 是一名解决方案构架师,在 Amazon Web Services 主要从事大数据和分析工作。Gagan 拥有超过 16 年的信息技术行业从业经验。他帮助客户在 AWS 上设计和构建高度可扩展、高性能且安全的基于云的解决方案。