亚马逊AWS官方博客
利用 AWS Comprehend 打造近实时文本情感分析
本篇博客为 2018年5月15日举办的在线研讨会 “Amazon Comprehend 服务介绍和应用” 的文字记录。视频回看及 PPT 下载地址请戳这里。
社交网络、用户评论等现在已经成为洞察用户体验反馈的重要来源,通过对这些文本的分析,迅速感知用户情绪和市场热点,快速作出主动响应。然而自然语言处理是一项复杂的工程,涉及到语料的收集、清洗,模型的训练与评估,上线后还涉及到模型迭代、系统升级及维护等一系列工作。Amazon Comprehend 是一项自然语言处理服务,它利用了深度学习技术,实现了文本的情绪、命名实体、关键短语的分析和文章的主题分类。它消除了上述从头构建自然语言处理工程的繁琐过程,直接以API形式提供Comprehend的各类自然语言处理服务。使用户能专注于业务功能的实现,快速和轻松得构建文本分析应用。
本文以实际的应用场景出发,介绍如何通过使用 Comprehend 的服务,结合 Kinesis Firehose 服务和 Lambda 来分析用户评论中的命名实体、关键短语和情绪,并利用 Elastic Search 和 Kibana 打造近实时的仪表盘,通过 Kibana 的过滤和聚合从多个维度进一步分析。整个方案没有使用任何 EC2 资源,是一个无服务器架构的实现。
我们首先看一下最终的展示效果:

下面我们来看下方案的架构:
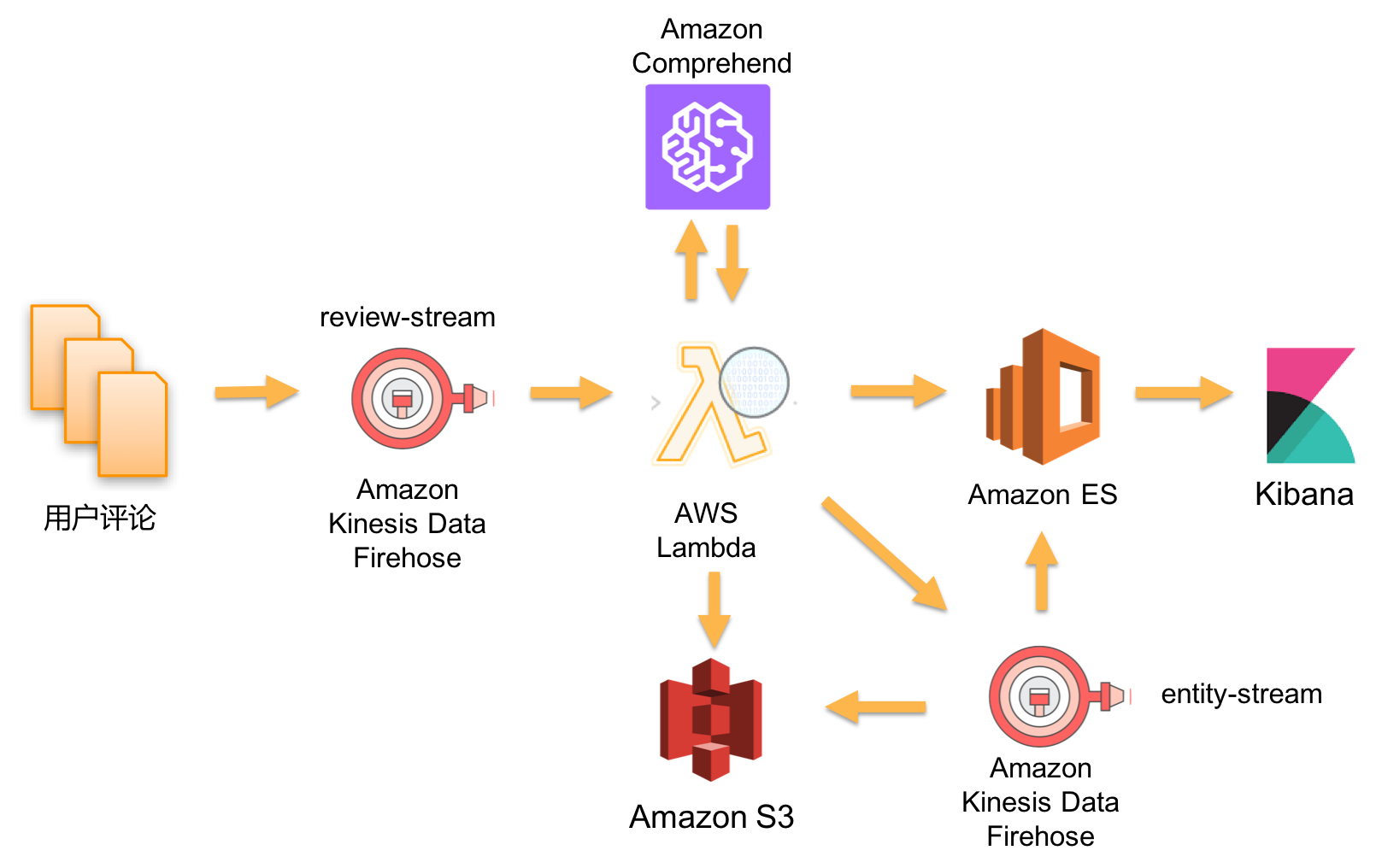
在上述架构图中:
- 用户评论及其相关数据通过 Kinesis Firehose API 持续将用户评论流数据输出到 Kinesis Firehose 中。在这个例子中,我们将以下数据传入 Kinesis Firehose:
- text: 用户评论文本
- title: 电影名称
- ip_addr: 用户提交评论时所用的ip
- geoip: 根据 ip_addr 的到地理位置信息,包括洲、国家、区域、城市、时区、经纬度
- 在 Kinesis Firehose 中定义 Transformation Lambda,调用 Comprehend API 对用户评论文本进行分析
- 分析完成以后的数据有三条路径:
- 用户情绪、关键短语等输出到 Elasticsearch
- 同时保存一份到 S3,以备其他应用做分析
- 命名实体作为新的数据流输出到另外的 Kinesis Firehose,最终输出到 Elasticsearch 和 S3
- 利用 Kibana 创建仪表板,近实时监控用户评论的热点命名实体和情绪分布,通过过滤来进一步洞察诸如特定热点命名实体类型对应的评论情绪和地理分布等
看到这里,您可能会问:一个用户评论的信息流,为什么用到两个 Kinesis Firehose?要解释清楚这个问题,我们需要从需求出发。我们在 Kibana 展现的仪表盘中,有一个需求是这样的:点击仪表盘中某个视图中的项目,其他视图要做相应过滤。

如上图所示,假设我要关注所有命名实体类型为 PERSON 的评论,当我点击 Top Entity Type 视图中的 PERSON 这个项目时,其他所有视图都要做相应过滤,只显示命名实体类型为 PERSON 的记录聚合结果。
我们知道一条评论中的命名实体会有多个,也就是说评论和命名实体是一对多的关系。例如我们有一个评论通过 Comprehend 分析以后到如下命名实体:

对于这样的数据结构,如何存入 Elasticsearch,我们有几种设计方案:
方案一
我们很自然的想到使用 nested 类型来描述一对多的关系,schema 定义如下:

数据存放在 Elastic Search 的样例如下:

然而目前 Kibana 还不支持 nested 字段的聚合查询,详细信息参见这里。
因此方案一是不可行的。
方案二
命名实体文本和类型作为两个 List,schema 定义如下:

数据存放在 Elastic Search 的样例如下:

这个方案的缺陷在于:命名实体文本和类型之间的关联丢失,无法通过类型来过滤命名实体,因此此方案也不可行。
方案三
增加一个字段 doc_type 用来区分记录类型,schema 如下:

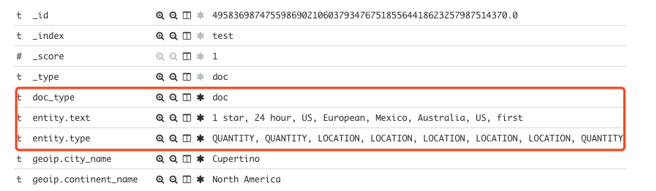
当 doc_type=’doc’ 时,我们存放的是完整的用户评论和文本分析的结果,这时候 entity 字段存放的数据和方案二一样,为两个列表,样例如下:
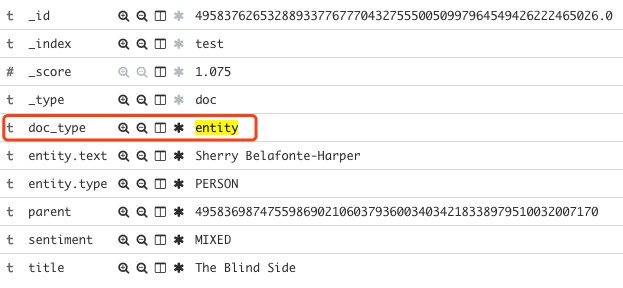
而当 doc_type=’entity’ 是,存放的是单个命名实体,同时存放了 sentiment, movie title 等需要关联过滤的字段。样例如下:
这样的设计用了一定的冗余来换取 Kibana 仪表盘中的关联过滤。因此除了需要一个用来接收用户评论的数据流以外,还需要一个接收命名实体的数据流。
在介绍完设计思路后,接下来一步一步介绍如何实现,主要分为以下几部分:
- 数据存储(Elasticsearch)
- 数据采集(Kinesis Firehose)
- 数据转换(Lambda + Comprehend)
- 数据展示(Kibana)
- 模拟产生演示数据
第一步 数据存储 – Elasticsearch
本文不再讨论如何创建 Elasticsearch 集群,详细文档请参考这里。
在创建完 Elasticsearch 集群以后,记下 Domain name,Endpoint 和 Kibana URL:
接下来我们使用 curl 命令创建一个 template,在这个 template 中,我们配置了 index pattern 和相应的字段类型,即今后 index 名称以 movie-review 开头的话,都应用我们定义好的 mapping。(请将 <ES endpoint> 替换为刚刚创建的 Elasticsearch Endpoint 中 https://之后的所有字符):
curl -XPUT "https://<ES endpoint>/_template/movie-review" -H 'Content-Type: application/json' -d'
{
"index_patterns": [
"movie-review*"
],
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"doc": {
"_source": {
"enabled": true
},
"properties": {
"@timestamp": {
"type": "date"
},
"doc_type": {
"type": "keyword"
},
"parent": {
"type": "keyword"
},
"text": {
"type": "text"
},
"title": {
"type": "keyword"
},
"entity": {
"properties": {
"text": {
"type": "keyword"
},
"type": {
"type": "keyword"
}
}
},
"key_phrase": {
"type": "text"
},
"sentiment": {
"type": "keyword"
},
"ip_addr": {
"type": "ip"
},
"geoip": {
"properties": {
"continent_name": {
"type": "keyword"
},
"country_name": {
"type": "keyword"
},
"country_iso_code": {
"type": "keyword"
},
"region_name": {
"type": "keyword"
},
"city_name": {
"type": "keyword"
},
"timezone": {
"type": "keyword"
},
"location": {
"type": "geo_point"
}
}
}
}
}
}
}
'其中 number_of_shards 和 number_of_replicas 根据实际数据量和容错要求来设计,这里两个参数的值只是为了演示。至此,Elastisearch 的配置完成,加下来我们创建 Lambda 函数,利用 Comrpehend API 分析用户评论。
第二步 数据转换(文本分析) – Lambda + Comprehend
在这部分我们将加下来我们创建 Lambda 函数,这个 Lambda 函数将被用于 Kinesis Firehose 来对传入的数据进行转换,我们利用 Comprehend API 分析用户评论,将结果输出到 Elasticsearch。首先进入 Lambda 服务主界面,点击 Create function。

在接下来的界面中,点击 Author from scratch,输入以下参数:
Name: text-analysis
Runtime: Python 2.7
Role: Create new role from template(s)
Role name: lambda-text-analysis
最后点击 Create function。

下载这个文件,或在浏览器中打开。
将该文件的代码复制粘贴到代码编辑框:

其中,ENTITY_STREAM_NAME 的值要和之后创建的用于接收 entity 流的 Kinesis Firehose 名字一直,REGION_NAME 为整个方案所部署在的区域代码。然后将 Timeout 改为5分钟:

最后点击右上角 Save。至此 Lambda 函数创建完成。由于我们在 Lambda 函数中调用了 Comprehend API 和 Kinesis Firehose API,因此 Lambda 函数需要有相应的权限。这些权限在 Role 中进行配置。打开 IAM 主界面,点击 Roles,在搜索框中输入我们刚刚创建的 role: lambda-text-analysis 并点击结果中的 lambda-text-analysis。
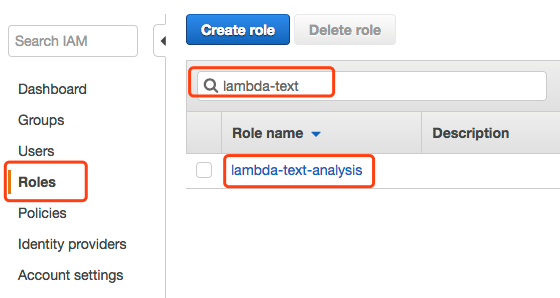
在 role 配置界面中点击 Attach policy

在接下来的界面中,选择以下两个 policy,并点击 Attach
- AmazonKinesisFirehoseFullAccess
- ComprehendReadOnly


出于演示目的,我们选择了AmazonKinesisFirehoseFullAccess,在实际应用中,应该遵循最小访问权限原则,请指定 Action 和 resource,在这个例子中,我们只对 entity-stream 这个 Firehose 使用了 PutRecord 动作,相应的 policy 样例如下:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"firehose:PutRecord",
"firehose:PutRecordBatch"
],
"Resource": " arn:aws:firehose:region:account-id:deliverystream/entity-stream"
}
]
}
根据实际情况替换 region 和 account-id。可以通过 Add inline policy 来加入以上 policy

第三步 数据采集 – Kinesis Firehose
创建review-stream
进入 Kinesis 服务主界面,点击 Create delivery stream

在 Step 1 界面中,输入 Delivery stream name: review-stream,并选择 Source 为 Direct PUT or other sources:

在 Step 2 界面中,选择 Record transformation为Enabled,Lambda function 中选择我们之前创建的 text-analysis,其他设置不用更改,点击 Next

在 Step 3 界面中,选择 Destination 为 Amazon Elasticsearch Service

接下来按照下图所示设置 Elasticsearch 相关的参数
- Domain: 已经创建好的ES Domain
- Index: movie-review
- Index rotation: Every day
- Type: doc
- Retry duration: 300 seconds

其中,Index rotation 在生产环境中根据实际产生的数据量来选择合适的滚动策略。这里我们选择 Every day,即每天会产生一个 index,产生的 index 名字后面会加上年月日,如 movie-review-2018-05-15。
在 S3 Backup 相关参数中,我们选择 Backup mode 为 All records,即备份所有的数据。然后选择相应的 S3 bucket 和 prefix。S3 bucket 和 Kinesis Firehose 在同一区域,避免跨区域传输数据。

在 Step 4 配置参数界面中,调整 Buffer Size 和 Buffer interval。在本实例中,我们需要尽量实时处理,因此将这两个参数调整至最小,分别是 1MB 和60秒。数值越小,实时性越高,会对 Elastisearch 产生更高的负载,需要根据实际情况设计。

其他参数根据实际需要做修改,最后点击 Create new, or Choose, 在之后的界面中点击 Allow 即可

最后确认一下所有设置,点击 Create delivery stream 完成创建。
接下来我们用同样的方法,再次创建一个 Kinesis Firehose,取名为:entity-stream。其中 Step 2 中,Record transformation 设为 Disabled
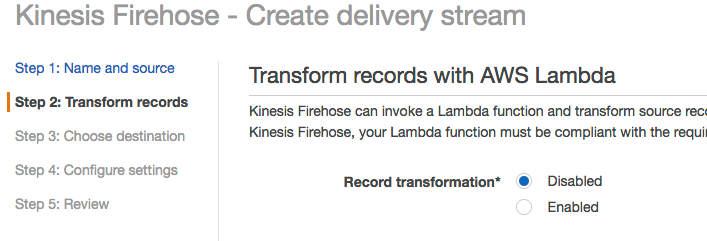
其他配置和 review-stream 配置一样。
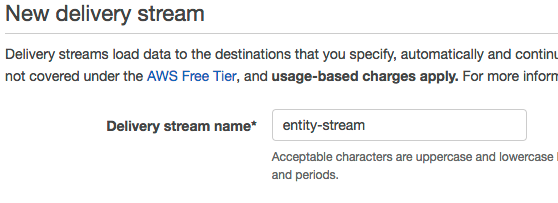
两个 Kinesis Firehose 创建完成以后,可以在 Data Firehose 中看到它们的状态。

至此 Kinesis Firehose 配置完成。接下来我们配置 Kibana 用来将 Elasticsearch 中的数据以图形化方式展示出来。
第四步 数据展示 – Kibana
在配置 Kibana 之前,我们首先要在浏览器中输入 Kibana URL,首次进入 Kibana 后,点击 Management 之后点击 Index Petterns
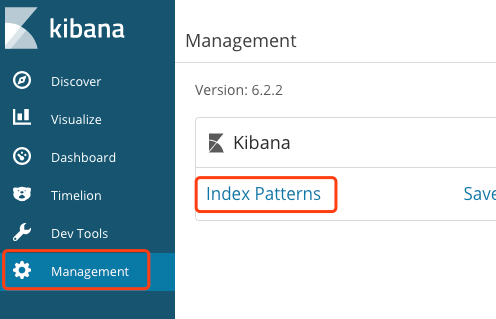
由于目前没有任何 Index 创建,我们在界面中看不到任何 Index。这时我们可以调用 Elasticsearch REST API 模拟插入一条数据。(请将 <ES endpoint> 替换为刚刚创建的 Elasticsearch Endpoint 中https://之后的所有字符):
curl -XPUT "https://<ES endpoint>/movie-review-2018-05-15/doc/1" -H 'Content-Type: application/json' -d'
{
"@timestamp": "1525523999877",
"text": "test review",
"title": "test title",
"ip_addr": "1.1.1.1",
"doc_type": "doc",
"sentiment": "POSITIVE",
"entity": {
"text": [
"entity-1",
"entity-2"
],
"type": [
"QUANTITY",
"LOCATION"
]
},
"key_phrase": [
"phrase-1",
"phrase-2"
],
"geoip": {
"continent_name": "North America",
"country_iso_code": "US",
"location": {
"lat": 37.751,
"lon": -97.822
}
}
}
'
curl -XPUT " https://<ES endpoint>/movie-review-2018-05-15/doc/2" -H 'Content-Type: application/json' -d'
{
"@timestamp": "1525523999877",
"title": "test title",
"doc_type": "entity",
"sentiment": "POSITIVE",
"parent": "1",
"entity": {
"text": "entity-1",
"type": "QUANTITY"
}
}
'
点击 Check for new data 后 Kibana 会自动识别新建的 Index。在 Index pattern 中输入:movie-review*,点击 Next step。
在接下的界面中,选择 @timestamp 字段作为时间戳,点击 Create index pattern

然后点击 Discover,我们可以看到刚才生成的一条文档已经能够正确被索引了。

有了 Index pettern 之后我们就可以建立可视化视图了。视图根据实际业务需求来建立。在方案中,我们创建以下视图:
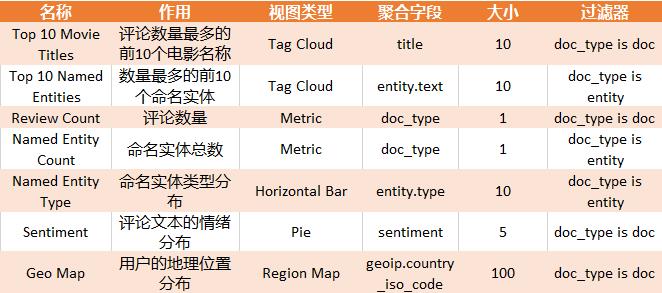
下面以 Top 10 Movie Titles 为例一步一步讲视图的创建过程,而其他视图请参考上表参数来创建:
点击 Visualize,选择 Other 中的 Tag Cloud

选择movie-review*
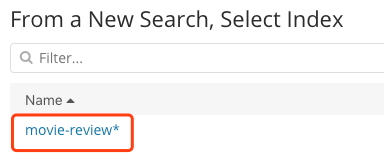
在接下来的界面中,如下图选择参数
Aggregation: Terms
Field: title
Size: 10
参数修改完成后,点击右上角的Apply settings
点击 Add a filter,按下图配置添加一个 filter,点击 Save

最后点击右上角的 Save,输入视图名称:Top 10 Movie Titles,点击 Save

可视化视图全部创建完成以后,创建一个 Dashboard,将之前创建的视图加入进来,调整大小和位置。最终生成如下图效果的仪表盘:

至此 Kibana 可视化效果都配置完成了
第五步 模拟生成用户评论 – Python
在真实的场景中,通常由应用将用户评论文本输出到 Kinesis Firehose。在本例中,为了展现仪表盘效果,我们准备了测试数据和模拟发送程序,请按以下步骤来做:
1. 下载测试数据
我们使用公开数据集 Large Movie Review Dataset v.1.0,该数据集包括5万条格式优化过的电影评论文本。下载这些数据到本地并解压。
解压以后,我们所要使用的文本文件在aclImdb/train/unsup中,每个文件对应一个评论:
以上评论数据集仅包括文本,为了展示电影名称,我们还需要电影名称公开数据集。下载这些文件并保存到 aclImdb/目录下。
2. 安装所需要的PIP包
评论生成程序使用 Python 3.6,其中用到了一些 pip 包生成 IP 和地理位置信息,请在 Python 3.6环境下安装一下 pip 包:
pip install maxminddb-geolite2, faker
3. 下载评论生成程序
评论生成程序使用 jupyter notebook 文件,下载地址。
使用 jupyter notebook 打开后,请根据实际情况修改以下参数:
REGION_NAME = ‘us-west-2’
STREAM_NAME = ‘review-stream’
FILE_RANGE_LOW = 1
FILE_RANGE_HIGH = 10
其中 FILE_RANGE_LOW和FILE_RANGE_HIGH 制定了发送给 Firehose 的评论文件范围,默认值是发送编号为1到10的评论,测试过程中可以先发送少量评论观察效果。如果需要发送全部5万条评论,则如下设置:
FILE_RANGE_LOW = 1
FILE_RANGE_HIGH = 50000
运行该程序后,即可发送评论数据,可通过 Kibana dashboard 观察数据的变化,并点击视图中的项目来进一步分析。
结论
使用 Amazon Comprehend 可以非常方便地对文本进行分析,结合 Kinesis Firehose、Lambda、Elasticsearch 和 Kibana 可以实现无服务器的近实时的用户评论分析仪表盘,清楚得掌握命名实体、关键短语、用户情绪及其分布。本方案经过扩展后,可以快速实现诸如产品评论、在线客服等场景的文本分析及近实时展现,同时还可以进一步扩展,对命名实体、情绪等做报警等其他处理。