亚马逊AWS官方博客
使用角色链限制 Amazon Redshift IAM 角色和组对 Amazon Redshift Spectrum 外部表访问
在Amazon Redshift Spectrum的助力之下,我们可以利用AWS Glue存储的元存储,对Amazon Simple Storage Service (Amazon S3)数据湖中的数据进行查询。这项功能将帮助大家将PB级别的Amazon Redshift数据仓库扩展为几乎不存在上限的数据存储体系,以经济且高效的方式将数据处理能力提升至EB级别。与Amazon EMR一样,Redshift Spectrum同样为用户带来开放数据格式与低廉的存储成本,并通过可拓展至数千个的Redshift Spectrum节点实现数据的提取、过滤、投射、聚合、分组以及排序。与Amazon Athena类似,Redshift Spectrum也是一项无服务器服务,不会带来任何基础设施配置或管理负担。每扫描1 TB数据,您只需要支付5美元成本。在本文中,我们将探讨如何实现Amazon Redshift的安全性配置、如何使用角色链接(role chaining)实现细粒度访问控制,以及如何实现以用户为基础的高保真权限管理。
在最初使用湖边小屋方法(lake house,即通过Redshift Spectrum将Amazon Redshift与Amazon S3数据湖集成起来)并对集群上不同外部Schema的访问进行权限分配时,我们必然需要更高的灵活性。我们假设有这样一个用例,AWS Glue数据目录中的两个Redshift Spectrum schema分别为SA与SB,其各自映射于数据库A与数据库B。我们希望在该数据目录中允许以下来自Amazon Redshift的查询请求:
- 仅允许IAM用户组
Grp1访问数据库SA。 - 仅允许IAM用户组
Grp2访问数据库SB。 - 不允许IAM用户组
Grp3访问数据库SA及SB。
在默认情况下,我们需要在分配给Amazon Redshift集群IAM( AWS Identity and Access Management,简称IAM)角色用于管理Redshift Spectrum表访问活动。这些策略也将被集群内的所有用户及组所继承。与集群关联的IAM角色无法被轻易转移至其他用户及组内。通过本文,我们将详细介绍如何为Amazon Redshift集群中的不同用户建立细粒度授权策略,以及如何使用IAM角色链接控制不同Redshift Spectrum schema与表的访问活动。角色链接可以直接使用,无需对集群做出任何修改。大家可以在IAM端完成所有修改。添加新角色时,同时不需要对Amazon Redshift做出任何修改。截至本文撰稿之时,本文介绍的细粒度、高度隔离化Redshift Spectrum schema/表访问控制能力仍然无与伦比(即使是配合AWS Lake Formation也无法实现)。关于跨账户查询的更多详细信息,请参阅如何为Amazon S3中的AWS KMS加密数据启用跨账户Amazon Redshift COPY与Redshift Spectrum查询。
先决条件
本文使用保存在Amazon S3当中的TPC-DS3TB公共数据集,使用AWS Glue数据库元数据,外加一套零售业示例数据集。要进行此轮演练,大家需要满足以下先决条件。受篇幅所限,本文无法就前两项条件做出详尽解释,但大家可以使用保存在Amazon S3数据湖内的自有集群与数据集。
- 创建一套Amazon Redshift集群(有无IAM角色皆可)。
- 使用Amazon S3中数据湖提供的数据(数据可以来自AWS Glue爬取程序、Amazon EMR、AWS Glue或者Athena)创建一套带有数据库的AWS Glue数据目录。该数据库应该拥有一份或者多份指向不同Amazon S3路径的表。本文将使用行业标准TPC-DS 3 TB数据集,大家也可以根据需求选择使用自己的数据集。
- 创建IAM用户与组,以供后续在Amazon Redshift内使用:
- 创建名为
grpA与grpB的新IAM组,暂不添加任何策略。 - 创建用户
a1与b2,并将其分别添加至组grpA与grpB当中。请使用小写用户名。 - 将以下策略添加至您创建完成的各个组内,允许IAM用户使用临时凭证完成Amazon Redshift身份验证:
- 创建名为
大家也可以只为集群内的特定用户与组分配此项策略,从而严格控制访问权限以提高安全水平。
- 在Amazon Redshift集群本地上创建IAM角色与组,暂不设置任何密码。
- 要创建用户
a1,请输入以下代码:
- 要创建用户
-
- 要创建
grpA,请输入以下代码:
- 要创建
-
- 重复上述步骤创建用户
b1,并将该用户添加至grpB。
- 重复上述步骤创建用户
- 在客户设备上安装一款jdbc sql查询客户端,例如SqlWorkbenchJ。
用例
在以下用例中,我们使用一个包含 tpcds3tb数据库的AWS Glue数据目录。该数据库中的表指向Amazon S3中的单一存储桶,但各表映射至存储桶内的不同前缀。以下截屏所示,为各个表的不同位置。

我们使用tpcds3tb数据库,创建一个名为schemaA的Redshift Spectrum外部schema。我们还需要创建grpA与grpB组,以及与各组映射的不同IAM角色。这里的目的,是在schemaA中针对各外部表为grpA与grpB分配不同的访问权限。
本文将提供两种解决方案实现选项:
- 在
schemaA当中,使用Amazon Redshiftgrant usage语句授权grpA访问外部表的权限。这些组可以访问schema所定义的数据湖内的所有表,无论各表在Amazon S3具有怎样的映射位置。 - 为Amazon S3外部schema配置角色链接,用于将组访问范围隔离至数据内的特定位置,同时拒绝访问schema内指向其他Amazon S3位置的表。
通过授予使用权限隔离用户与组访问
我们可以在schemaA上使用Amazon Redshift授予使用权限,该权限将允许grpA访问当前schema下的所有对象。这里我们还没有向grpB授权任何使用权限,因此该组中的用户在查询时将收到拒绝访问提示。
- 为Amazon Redshift集群创建一个名为
mySpectrum的IAM角色,配合以下策略允许Redshift Spectrum读取Amazon S3对象: - 在Amazon Redshift中添加信任关系,允许各用户获取分配给该集群的角色。详见以下代码:
- 选择您的集群名称。
- 选择 Properties。
- 选择Manage IAM roles.
- 在Available IAM roles部分,选择您的新角色。如果角色未正确列出,请选择Enter ARN并输入该角色的ARN。
- 选择Done,您将看到以下截屏内容。

- 使用包含AWS SDK的Amazon Redshift JDBC驱动程序,大家可以从Amazon Redshift控制台处下载该驱动程序(详见以下截屏),并使用IAM连接字符串通过SqlWorkbenchJ等SQL客户端接入该集群。以下截屏所示,为选择jar文件类型的步骤。



以下截屏所示,为使用WOrkbenhJ时的连接配置。
- 以Amazon Redshift管理员用户的身份使用
schemaA创建映射至AWS Glue数据库tpcds3tb的外部schema(大家可以使用之前创建的IAM角色,以允许Redshift Spectrum访问Amazon S3)。详见以下代码: - 使用以下代码在Amazon Redshift目录中验证此schema:
- 为
grpA授予使用权限,详见以下代码:
- 使用SQL客户端以
grpA组内用户a1的身份查询schemaA中的表,详见以下代码:
以下截屏所示,为成功执行后的查询结果。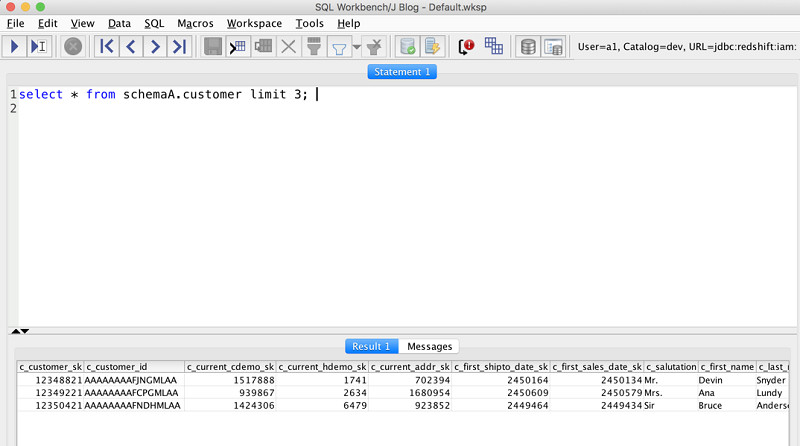
- 以
grpB组内用户b1的身份查询schemaA中的表。以下截屏所示,为您收到的错误提示信息。

此选项能够以极高的灵活性帮助我们隔离Redshift Spectrum schema中的用户访问活动。但如果需要授权用户b1访问该schema中的一个或者多个表,而非全部表,又该如何实现?下面我们将使用另一种方案选项,创建粗粒度的访问控制策略。
使用IAM策略与角色链接隔离用户与组访问
大家可以使用带有信任关系的IAM角色,并把IAM策略映射到该IAM角色,借此根据集群内的Amazon S3位置为用户及组指定访问权限。在本用例中,我们授权grpB仅可访问位于s3://myworkspace009/tpcds3t/catalog_page/上的catalog_page表,并授权grpA可访问位于s3://myworkspace009/tpcds3t/*上除catalog_page之外的全部表。要实现这一安全控制目标,我们需要完成以下操作步骤。
以下示意图为整个角色链接的工作方式。
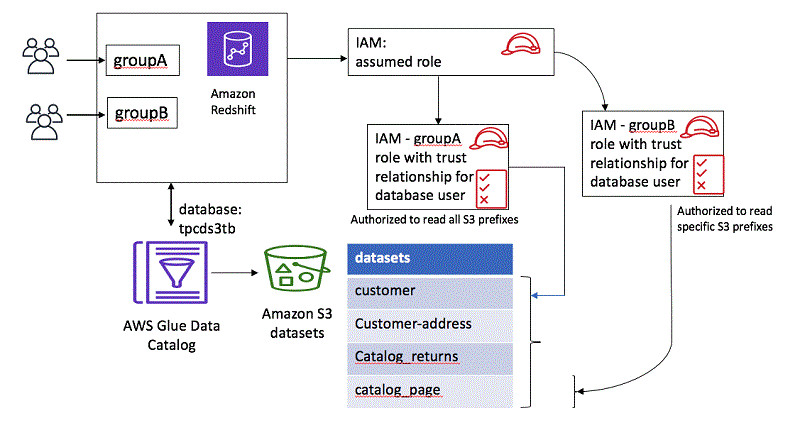
首先,根据指向grpA与grpB的策略创建IAM角色。第一个角色为通用集群角色,允许用户使用角色中定义的信任关系获取角色身份。
- 在IAM控制台上创建一个新角色。详见以下代码:
- 为此角色添加以下两项策略:
- 添加一项名为
AWSAWS GlueConsoleFullAccess的管理策略。大家可以考虑使用符合最低权限原则的内联策略,借此替代托管角色以更严格地限制安全需求。 - 使用以下规则添加一条名为
myblog-redshift-assumerole-inline的内联策略:
- 添加一项名为
- 添加一条信任关系,允许集群内的各用户使用该角色。大家可以根据需要限制可使用此角色的具体用户。详见以下代码:
- 创建一个指定
grpA组的Redshift定制新角色,在策略中仅允许其访问grpA组有权访问的Amazon S3位置。请注意去掉catalog_page表所对应的Amazon S3位置;我们要保证grpA组无法访问此表中的数据。- 将此角色命名为
myblog-grpA-role。
- 将此角色命名为
- 向此角色添加以下两项策略:
- 向此角色添加名为
AWSAWS GlueConsoleFullAccess的托管策略。(注意:出于更严苛的安全需求,大家可以考虑使用最低权限内联策略以替代此托管角色。) - 使用以下规则添加名为
myblog-grpA-access-policy的内联策略(您可以根据实际安全需求修改此策略以满足最低权限原则):
- 向此角色添加名为
- 添加一条信任关系,显式罗列
grpA组内的所有用户,且仅允许各用户使用当前角色(选择Trust relationships选项卡,通过编辑添加以下策略以更新相关账户详情):必须为添加至此角色的每位用户更新信任关系,或者为每位用户构建新的角色。大家可以轻松使用脚本自动为各新用户更新此信任关系。 - 创建另一个指向
grpB组的Redshift-customizable角色,附带策略要求各角色只能访问该组有权访问的Amazon S3位置。- 将此角色命名为
myblog-grpB-role。
- 将此角色命名为
- 向此角色添加以下两项策略。在创建过程中保证各托管策略正确反映各数据库组的数据访问权限,并将其添加至集群上的已有角色中。
- 向该角色添加一项名为
AWSAWS GlueConsoleFullAccess的托管策略。出于更严苛的安全需求,大家可以考虑使用最低权限内联策略以替代此托管角色。 - 使用以下规则添加名为
myblog-grpB-access-policy的内联策略(您可以根据实际安全需求修改此策略以满足最低权限原则):
- 向该角色添加一项名为
- 添加一条信任关系,显式罗列
grpB组内的所有用户,且仅允许各用户使用当前角色(选择Trust relationships选项卡,通过编辑添加以下策略以更新相关账户详情):必须为添加至此角色的每位用户更新信任关系,或者为每位用户构建新的角色。大家可以轻松使用脚本自动为各新用户更新此信任关系。 - 将这三个角色添加至Amazon Redshift集群,同时移除其他映射至该集群的其他一切角色。如果您在下拉菜单中找不到现有角色,请使用角色ARN。
- 以管理员用户身份为
grpA与grpB组分别创建一个新的外部schema,同时使用您之前创建的两个角色的角色链接。- 对于
grpA组,请输入以下代码:
- 对于
-
- 对于
grpB组,请输入以下代码:
- 对于
- 在
grpA与grpB组内以用户身份查询该外部schema。- 要以
grpA组内用户a1的身份查询customer表与catalog_page表,请输入以下代码:
- 要以
以下截屏所示,为查询返回的结果;用户a1能够成功访问customer表。

以下截屏所示,为用户a1无法访问catalog_page表。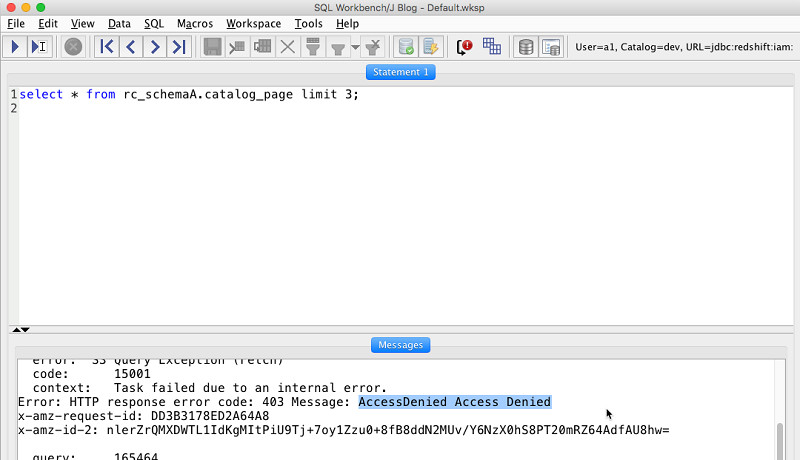
-
- 以
grpB组内用户b1的身份查询customer表与catalog_page表。
- 以
以下截屏所示,为用户b1能够成功访问catalog_page表。
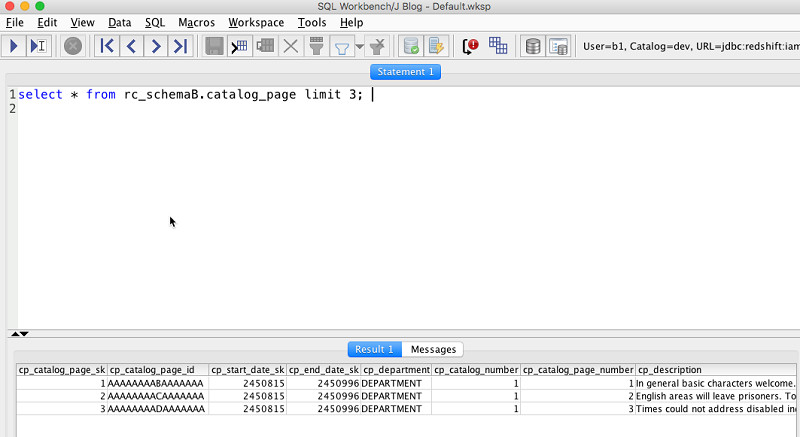
以下截屏所示,为用户b1无法访问customer表。
总结
本文展示了两种控制用户及组对外部schema及表执行访问的方法。在使用Grant usage语句的第一种方法当中,无论表指向哪一条Amazon S3数据湖路径,被授权的组都可以访问schema中的所有表。这种方法灵活性更强,可以轻松实现访问授权,但无法允许或拒绝访问该schema中的某一或某些特定表。
而在第二种选项里,大家可以立足Amazon S3对象的维度管理用户与组访问,从而更好地控制数据安全性并降低未授权数据访问风险。与第一种方法相比,后面这种方法会带来额外的配置开销,但与之对应的则是更可靠的数据安全性。
作为这两种方法的基础,大家应该建立起正确的治理模型,保证根据各用户组的实际需求授予其访问Amazon S3路径、外部schema以及表映射的能力,从而在保障安全性的同时降低运营开销。
这里特别鸣谢AWS同事Martin Grund为本文编撰提出的宝贵意见与建议。