亚马逊AWS官方博客
在 SageMaker 上运行基于 Colossal-AI 的分布式 finetune 任务
近年来,深度学习的发展呈指数级增长,机器学习算法和并行计算技术的进步推动了计算机视觉和自然语言处理等领域的突破。然而,训练大型数据集上的深度神经网络可能非常耗时和资源密集。分布式训练,即将计算分散到多个设备或机器上,可以显著加快这一过程。
作为当下最火热的 AI 大模型开源软件系统,Colossal-AI 提供了一系列并行组件和用户友好的工具,支持分布式深度学习模型的低成本开发和部署。它简化了构建和运行分布式深度学习模型的过程,使开发人员更容易利用并行计算的优势来完成他们的机器学习任务。Amazon SageMaker 是一个完全托管的服务,为开发人员和数据科学家提供了快速轻松地构建、训练和部署机器学习模型的能力。它支持各种深度学习框架,包括 TensorFlow、PyTorch 和 MXNet,并为大规模模型提供分布式训练环境。在这篇博客中,我们将以 Stable Diffusion 为例,阐述如何在 Amazon SageMaker 上运行基于 Colossal-AI 的分布式微调(finetune)任务。
源码解读
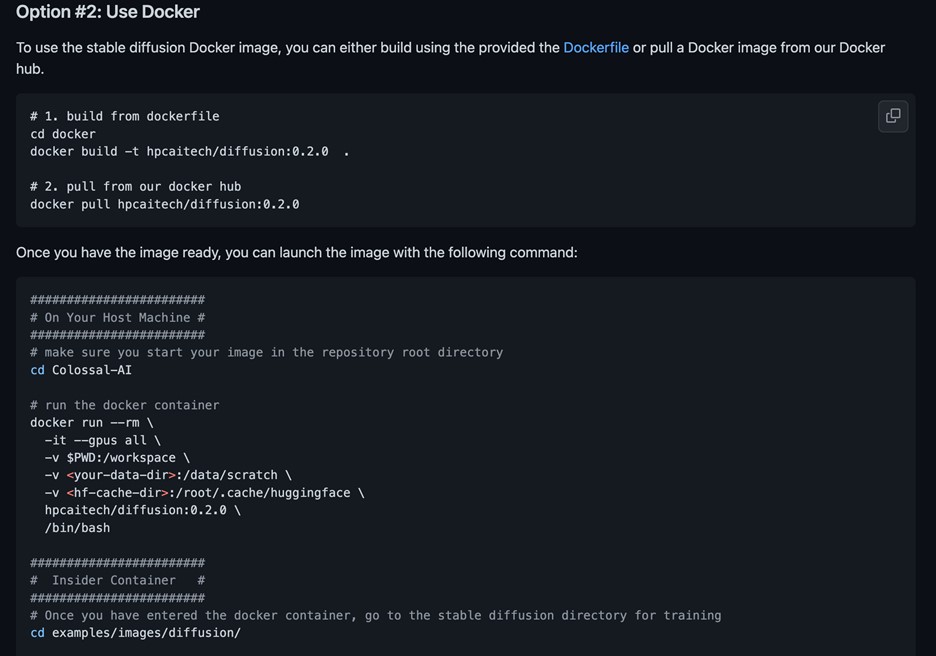
首先打开 https://github.com/hpcaitech/ColossalAI/tree/main/examples/images/diffusion,在 Use Docker 下,我们可以看到基于 Docker 的训练步骤如下:
- 从ColossalAI Docker Hub下指定基础镜像源;
- 下载checkpoint;
- 修改train_colossalai_teyvat.yaml,运行main.py;
- 此外,主页下提供了requirements.txt安装pip依赖。
 |
Amazon SageMaker Training Job 集成
基于 Colossal-AI 的官方陈述,基于 Amazon SageMaker 运行 Training Job 有额外更改:
- 增加系统运行环境变量/opt/ml 并指定该路径为 WORKDIR。
- Amazon SageMaker 通过在 image 名称之后指定 train 参数默认的 CMD 语句,即在 train 中指定 main.py 为 entrypoint。
- 改写 main.py,将输入与输出位置改为对应的 S3 数据/模型存储路径。
在本 blog 中,我们以 https://github.com/zhaoanbei/ColossalAI_sagemaker_byoc.git 为例解释集成流程。首先打开 Dockerfile 如下:
解释:
ENV PATH="/opt/ml:${PATH}":这个指令将 /opt/ml 目录添加到环境变量 PATH 中。
WORKDIR /opt/ml:这个指令设置当前工作目录为 /opt/ml。
RUN wget --no-verbose https://huggingface.co/stabilityai/stable-diffusion-2-base/resolve/main/512-base-ema.ckpt:这个指令运行(https://huggingface.co/stabilityai/stable-diffusion-2-base/resolve/main/512-base-ema.ckpt%EF%BC%9A%E8%BF%99%E4%B8%AA%E6%8C%87%E4%BB%A4%E8%BF%90%E8%A1%8C)wget 命令下载一个预训练的模型文件。
COPY requirements.txt.1 /opt/ml/ 和 COPY setup.py /opt/ml/:这些指令将 requirements.txt.1 和 setup.py 从 Dockerfile 所在目录复制到容器中的 /opt/ml 目录。
RUN pip install -r requirements.txt.1 && pip install lightning && pip install -e. :这个指令运行 pip 命令来安装所需的 Python 包,包括 requirements.txt.1 中列出的包,以及 lightning 和当前目录下的 Python 包。
RUN cd /opt/ml/ColossalAI && pip install -e .:这个指令进入 /opt/ml/ColossalAI 目录,并运行 pip 命令来安装 ColossalAI 的 Python 包。
COPY . /opt/ml:这个指令将 Dockerfile 所在目录中的所有文件复制到容器中的 /opt/ml 目录下。
RUN ls /opt/ml:这个指令运行 ls 命令来列出 /opt/ml 目录下的文件,以检查之前的复制操作是否成功。
RUN wget --no-verbose https://github.com/peak/s5cmd/releases/download/v2.0.0/s5cmd_2.0.0_Linux-64bit.tar.gz && tar -zxvf s5cmd_2.0.0_Linux-64bit.tar.gz :下载 s5cmd 运行文件,使用 s5cmd 可以高速地将训练完成的大模型文件上传到 S3,而无需依赖于 Training Job 自动打包模型的功能。
ENV HF_DATASETS_OFFLINE=0、ENV TRANSFORMERS_OFFLINE=1、ENV DIFFUSERS_OFFLINE=1:这些指令设置环境变量,包括 HF_DATASETS_OFFLINE、TRANSFORMERS_OFFLINE 和 DIFFUSERS_OFFLINE 的值为 “0” 或 “1”。
然后我们查看 train,这里确认 main.py 的参数以及输出 S3 路径。
然后在__main__中,我们调用_run 来运行 main_1.py。同时注意数据 input 默认在/opt/ml/input/data 路径下。
最后,我们打开 diffusion_byoc.ipynb,按照顺序运行:
用于构建位于 sagemaker notebook 所在区域的 ECR 镜像, repository 名称为 diffusion。
这段代码赋予脚本运行权限,指定训练实例为 ml.g5.xlarge,image_uri 为上一步所创建的 ECR repository url,volume_size 为 50G。在运行 estimator.fit 后,训练开始。
然后我们回到 SageMaker 控制台,在 Training—Training jobs—最新的 job ID 下—Output 可以看到 S3 model artifact。注意由于使用 s5cmd 进行模型同步,在 train 指定的 s3_path 变量路径会覆盖 sagemaker 默认的 S3 model artifact,在范例代码中,s3_path 为 s3://sagemaker-us-west-2-310850127430/df_model/,可以看到S3输出结果。
 |
本文介绍了如何在 AWS SageMaker 上使用 Colossal-AI 分布式深度学习平台进行分布式微调任务。作者以 Stable Diffusion 为例,详细讲解了如何基于 Docker 在 SageMaker 上运行 Colossal-AI 分布式微调任务,并提供了实际的代码示例供读者参考。