场景概述
- 在医学报告整理和内容提取的场景中,从业人员往往需要花费大量的时间进行内容阅读和关键字的提炼;Amazon Textract 结合 Amazon Comprehend Medical 的解决方案整体采用无服务器化架构,全自动化也提高整体效率。采用该解决方案,可以以秒级的效率提取出需要的内容;除此之外,该架构也大大降低了整体成本,架构中包含的所有服务都以实际使用计费。
- Amazon Textract 是一个托管的 OCR(Optical Character Recognition) 服务,Amazon Comprehend Medical 是一个医疗语义分析的托管人工智能服务。通过 Amazon Textract 将医学报告和诊断报告的表单表格转化成序列化文档,通过 Amazon Comprehend Medical 对这些序列化文档进行分析并快速获取不同分类的信息。在 CRO(Clinical Research Organization) 等行业场景中,可以通过这个解决方案对医学研究、药物分析及诊断报告提供有效的帮助和补充。
服务架构
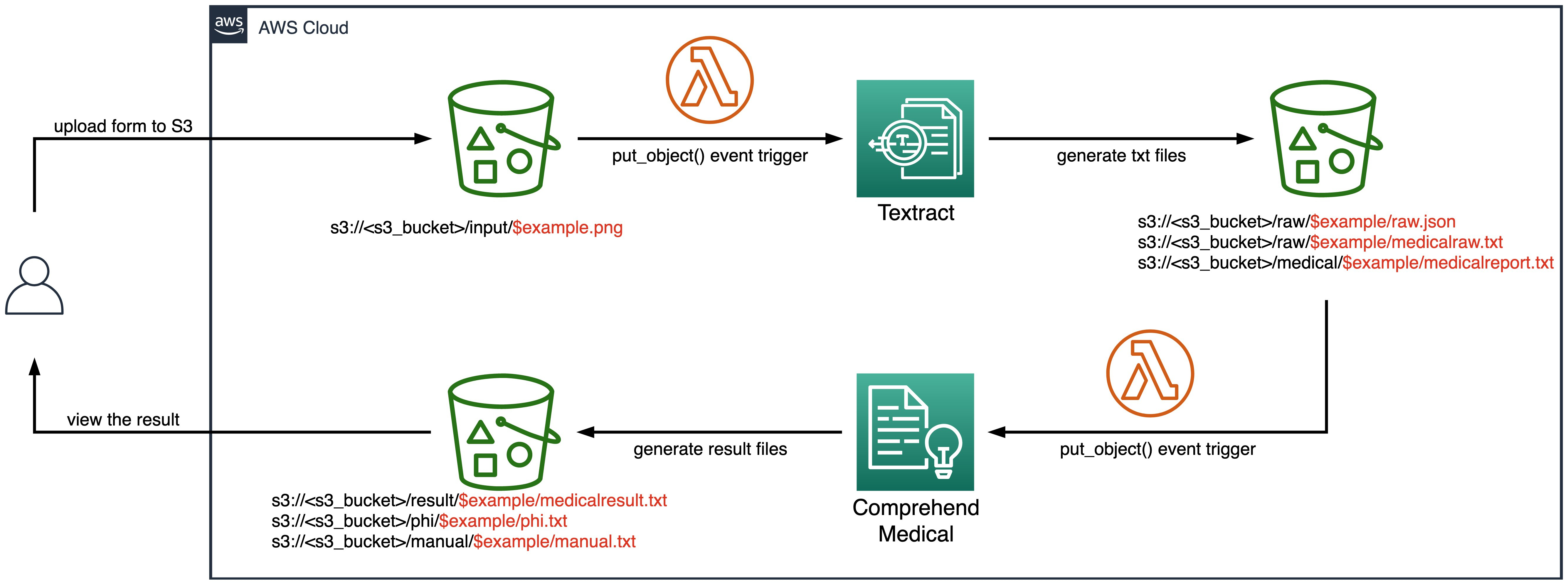
- 在这个架构中,我们需要创建:
- 一个 Amazon S3 存储桶用来存放输入的文档资料和输出的结果文件
- 一个用来调用 Amazon Textract API 的 AWS Lambda 函数
- 一个用来调用 Amazon Comprehend Medical API 的 AWS Lambda 函数

架构逻辑如下:
- 以用户向 Amazon S3 传入一个文档为例,上传成功后 AWS Lambda 函数会以该事件作为触发并调用 Amazon Textract API,将该文档内容提取成序列化的文档以及待分析的文本,并存入 Amazon S3 的相应路径
- 上述待分析文本传入 Amazon S3 后,又会触发下一个 AWS Lambda 函数,调用 Amazon Comprehend Medical API,对内容进行语义分析,并将分析后的结果写入 Amazon S3
- 完成以上自动化的操作后,用户即可查询读取提炼后的内容进行进一步的工作
具体实现
Amazon S3 存储桶配置
- 创建用于输入和输出医学分析报告的存储桶和桶下面相应目录,例如:
- 存储桶:s3://medical-report-analysis-<unique_identifier>
- 这里的<unique_identifier> 用以和其他用户的 S3 存储桶区分,因为 Amazon S3 存储桶的名称具有全球唯一性
- 文档输入目录:s3://medical-report-analysis-<unique_identifier>/input
- 手动检查目录:s3://medical-report-analysis-<unique_identifier>/manual
- 分析输入目录:s3://medical-report-analysis-<unique_identifier>/medical
- 保护数据目录:s3://medical-report-analysis-<unique_identifier>/phi
- 原始文档目录:s3://medical-report-analysis-<unique_identifier>/raw
- 分析结果目录:s3://medical-report-analysis-<unique_identifier>/result

AWS IAM 权限配置
由于整体技术实现会通过 AWS Lambda 作为粘合剂将几个服务串联起来,所以需要创建相应的 AWS IAM 角色以确保服务之间有权限进行相互调用;以下会创建用于串接 Amazon S3 和 Amazon Textract 的 AWS IAM Role,以及用于串接 Amazon S3 和 Amazon Comprehend Medical 的 AWS IAM Role:
- 创建用于串接 Amazon S3 和 Amazon Textract 的 AWS IAM Policy:
- 策略名称:LAMBDA_TEXTRACT_S3_RW
- 策略文档:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"textract:*",
"s3:*",
"cloudwatch:*",
"logs:*",
"iam:GetPolicy",
"iam:GetPolicyVersion",
"iam:GetRole"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "iam:CreateServiceLinkedRole",
"Resource": "arn:aws:iam::*:role/aws-service-role/events.amazonaws.com/AWSServiceRoleForCloudWatchEvents*",
"Condition": {
"StringLike": {
"iam:AWSServiceName": "events.amazonaws.com"
}
}
}
]
}
- 创建用于串接 Amazon S3 和 Amazon Textract 的 AWS IAM Role:
- 受信任实体:Lambda
- 绑定策略:LAMBDA_TEXTRACT_S3_RW
- 角色名称:LAMBDA_TEXTRACT_S3_RW_ALL
- 创建用于串接 Amazon S3 和 Amazon Comprehend Medical 的 AWS IAM Policy:
- 策略名称:LAMBDA_COMPREHENDMEDICAL_S3_RW
- 策略文档:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"comprehendmedical:*",
"s3:*",
"cloudwatch:*",
"logs:*",
"iam:GetPolicy",
"iam:GetPolicyVersion",
"iam:GetRole"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "iam:CreateServiceLinkedRole",
"Resource": "arn:aws:iam::*:role/aws-service-role/events.amazonaws.com/AWSServiceRoleForCloudWatchEvents*",
"Condition": {
"StringLike": {
"iam:AWSServiceName": "events.amazonaws.com"
}
}
}
]
}
- 创建用于串接 Amazon S3 和 Amazon Textract 的 AWS IAM Role:
- 受信任实体:Lambda
- 绑定策略:LAMBDA_COMPREHENDMEDICAL_S3_RW
- 角色名称:LAMBDA_COMPREHENDMEDICAL_S3_RW_ALL
AWS Lambda 函数 – textract_content_ingest
- 函数名称:textract_content_ingest
- 运行时:Python 3.8
- 执行角色:LAMBDA_TEXTRACT_S3_RW_ALL
- 内存分配:1024 MB
- 超时:1 分钟
- 代码如下:
import boto3
import json
def lambda_handler(event, context):
# File definition
s3Key = event['Records'][0]['s3']['object']['key']
keyName = s3Key.split('/')[1].split('.')[0]
outFile = '/tmp/output.json'
outputKey = 'raw/' + keyName + '/raw.json'
medicalRaw = "/tmp/medicalraw.txt"
medicalRawKey = 'raw/' + keyName + '/medicalraw.txt'
medicalReport = '/tmp/medicalreport.txt'
medicalReportKey = 'medical/' + keyName + '/medicalreport.txt'
# S3 and Textract Configuration
s3Bucket = event['Records'][0]['s3']['bucket']['name']
fileType = 'FORMS'
# Call Textract to convert form to json
textract = boto3.client('textract')
textractResponse = textract.analyze_document(
Document={
'S3Object': {
'Bucket': s3Bucket,
'Name': s3Key
}
},
FeatureTypes=[
fileType
]
)
with open(outFile, 'w') as outfile:
outfile.write(json.dumps(textractResponse, indent=4))
# Ingest content
for blocks in textractResponse['Blocks'][1:]:
if blocks['Confidence']:
if (blocks['Confidence'] >= 70) and (blocks['BlockType'] == 'LINE'):
with open(medicalReport, 'a') as medicalReportOut:
medicalReportOut.write(blocks['Text'] + "\r\n")
elif (blocks['Confidence'] >= 70) and (blocks['BlockType'] == 'WORD'):
with open(medicalRaw, 'a') as medicalRawOut:
medicalRawOut.write(blocks['Text'] + "\r\n")
else:
continue
else:
print("oops")
# Upload outputs to s3
s3 = boto3.resource('s3')
try:
s3.meta.client.upload_file(outFile, s3Bucket, outputKey)
s3.meta.client.upload_file(medicalReport, s3Bucket, medicalReportKey)
s3.meta.client.upload_file(medicalRaw, s3Bucket, medicalRawKey)
except Exception as e:
print(e)
print("Upload failed!")
else:
print("Upload done!")
AWS Lambda 函数 – comprehendmedical_analysis
- 函数名称:comprehendmedical_analysis
- 运行时:Python 3.8
- 执行角色:LAMBDA_COMPREHENDMEDICAL_S3_RW_ALL
- 内存分配:1024 MB
- 超时:1 分钟
- 代码如下:
import boto3
import json
def lambda_handler(event, context):
# Configure definition
s3Bucket = event['Records'][0]['s3']['bucket']['name']
s3Key = event['Records'][0]['s3']['object']['key']
keyName = s3Key.split('/')[1].split('.')[0]
localFinal = '/tmp/result.txt'
phiFinal = '/tmp/phi.txt'
manualFinal = '/tmp/manual.txt'
medicalResult = 'result/' + keyName + '/medicalresult.txt'
phiResult = 'phi/' + keyName + '/phi.txt'
manualResult = 'manual/' + keyName + '/manual.txt'
# Ingest medical report
try:
s3 = boto3.client('s3')
except Exception as e:
print(e)
print('connect S3 failed!')
else:
print('connect S3 successfully')
s3_object = s3.get_object(Bucket=s3Bucket, Key=s3Key)
body = s3_object['Body']
# Execute medical analysis
try:
comprehendMedical = boto3.client('comprehendmedical')
except Exception as e:
print(e)
else:
print('connect Comprehend Medical successfully')
detectEntities = comprehendMedical.detect_entities_v2(
Text=body.read().decode('utf-8')
)
detectOutputRaw = detectEntities['Entities']
# Categorize different types of information
report_ANATOMY = []
report_MEDICAL_CONDITION = []
report_MEDICATION = []
report_PROTECTED_HEALTH_INFORMATION = []
report_TEST_TREATMENT_PROCEDURE = []
report_MANUAL = []
for ctgy in detectOutputRaw:
if ctgy['Score'] >= 0.6:
if ctgy['Category'] == 'ANATOMY':
report_ANATOMY.append(ctgy)
elif ctgy['Category'] == 'MEDICAL_CONDITION':
report_MEDICAL_CONDITION.append(ctgy)
elif ctgy['Category'] == 'MEDICATION':
report_MEDICATION.append(ctgy)
elif ctgy['Category'] == 'PROTECTED_HEALTH_INFORMATION':
report_PROTECTED_HEALTH_INFORMATION.append(ctgy)
elif ctgy['Category'] == 'TEST_TREATMENT_PROCEDURE':
report_TEST_TREATMENT_PROCEDURE.append(ctgy)
else:
continue
else:
report_MANUAL.append(ctgy)
result_ANATOMY = []
result_MEDICAL_CONDITION = []
result_MEDICATION = []
result_PROTECTED_HEALTH_INFORMATION = []
result_TEST_TREATMENT_PROCEDURE = []
result_MANUAL = []
if report_ANATOMY:
for anatomy in report_ANATOMY:
result_ANATOMY.append(anatomy['Text'])
if report_MEDICAL_CONDITION:
for medical_condition in report_ANATOMY:
result_MEDICAL_CONDITION.append(medical_condition['Text'])
if report_MEDICATION:
for medication in report_MEDICATION:
result_MEDICATION.append(medication['Text'])
if report_PROTECTED_HEALTH_INFORMATION:
for protected_health_information in report_PROTECTED_HEALTH_INFORMATION:
result_PROTECTED_HEALTH_INFORMATION.append(protected_health_information['Text'])
if report_TEST_TREATMENT_PROCEDURE:
for test_treatment_procedure in report_TEST_TREATMENT_PROCEDURE:
result_TEST_TREATMENT_PROCEDURE.append(test_treatment_procedure['Text'])
if report_MANUAL:
for test_manual in report_MANUAL:
result_MANUAL.append(test_manual['Text'])
with open(localFinal, 'a') as localfile:
if result_ANATOMY:
localfile.write('Anatomy:\r\n' + '\r\n'.join(set(result_ANATOMY)))
if result_MEDICAL_CONDITION:
localfile.write('\r\n---\r\n')
localfile.write('Medical Condition:\r\n' + '\r\n'.join(set(result_MEDICAL_CONDITION)))
if result_MEDICATION:
localfile.write('\r\n---\r\n')
localfile.write('Medication:\r\n' + '\r\n'.join(set(result_MEDICATION)))
if result_TEST_TREATMENT_PROCEDURE:
localfile.write('\r\n---\r\n')
localfile.write('Test Treatment Procedure:\r\n' + '\r\n'.join(set(result_TEST_TREATMENT_PROCEDURE)))
localfile.close()
with open(phiFinal, 'a') as phifile:
if result_PROTECTED_HEALTH_INFORMATION:
phifile.write('Protected Health Information:\r\n' + '\r\n'.join(set(result_PROTECTED_HEALTH_INFORMATION)))
phifile.close()
with open(manualFinal, 'a') as manualfile:
if result_MANUAL:
manualfile.write('Manually Check:\r\n' + '\r\n'.join(set(result_MANUAL)))
manualfile.close()
# Upload outputs to s3
s3Upload = boto3.resource('s3')
try:
s3Upload.meta.client.upload_file(localFinal, s3Bucket, medicalResult)
s3Upload.meta.client.upload_file(phiFinal, s3Bucket, phiResult)
s3Upload.meta.client.upload_file(manualFinal, s3Bucket, manualResult)
except Exception as e:
print(e)
print("Upload failed!")
else:
print("Upload done!")
Amazon S3 事件与 AWS Lambda 集成
- 使用拥有 Amazon S3 管理权限的用户登录 AWS 管理控制台
- 进入到相应的 Amazon S3 存储桶 (medical-report-analysis-<unique_identifier>)
- 切换到“属性”选项卡,点开“事件”
- 点击“添加通知”,输入名称“upload_report”,事件勾选 “PUT”,前缀处输入 “input/”,发送到选择 AWS Lambda,选择函数 textract_content_ingest,然后选择保存
- 点击“添加通知”,输入名称“comprehendmedical_analysis”,事件勾选 “PUT”,前缀处输入 “medical/”,发送到选择 AWS Lambda,选择函数 comprehendmedical_analysis,然后选择保存
实际测试
Amazon Textract 接受三种数据类型:
通过 AWS 管理控制台上传
- 使用拥有 Amazon S3 上传权限的用户登录 AWS 管理控制台
- 进入到相应的 S3 存储桶 (medical-report-analysis-<unique_identifier>)
- 进入到 input 目录,点击“上传”并选择相应的文件
通过 AWS CLI 上传
aws s3 cp <medical report>.png s3://medical-report-analysis-<unique_identifier>/input/<medical report>.png
关于如何配置 AWS CLI,参考如下链接:
验证结果
在相应目录中会看到对应的输出文件,如下:
- input: <medical report>.png
- manual: <medical report>/manual.txt
- medical: <medical report>/medicalreport.txt
- phi: <medical report>/phi.txt
- raw:
- <medical report>/medicalraw.txt
- <medical report>/raw.json
- result:
- <medical report>/medicalresult.txt
如下示例:

小结
通过使用 Amazon Textract 和 Amazon Comprehend Medical,可以大大简化医学报告整理和针对性内容采集的工作量,医疗行业客户可以把更多精力致力于医学研究。
场景限制
- 整体架构目前只能用于 AWS Global 账号体系,AWS China 暂时还没有这两个服务。
- 目前 Amazon Textract 和 Amazon Comprehend Medical 都暂时只支持对于英语文本的语义分析。
- 目前 Amazon Comprehend Medical 对于输入文档有 20,000 字节的大小限制。如果输入文档较大的话暂时无法直接使用 Amazon Comprehend Medical 对文档进行自动化语义分析。但是在使用 Amazon Textract 进行原始文档识别输出成序列化文档之后,可以通过 AWS 管理控制台将内容手动粘贴到 Amazon Comprehend Medical 中进行分析。
- 在使用 Amazon Textract 中,目前默认识别为 Form 的格式;而 Amazon Textract 还有一种 Table 格式暂时不在这篇分享中展开。
- 类似场景如果需要在中国实现,可以和 AWS 的业务拓展联系,AWS 有非常完善的合作伙伴生态体系来提供各种解决方案。
优化考虑
- 在定义 AWS Lambda 函数的 AWS IAM 权限的时候,为了简化实现,我们给了两个函数相对较宽松的权限设定;如果要实现更细颗粒度的安全管控,可以对相应 AWS IAM 角色的策略文档进行细化修改,针对于特定资源特定操作实现最小颗粒度的白名单操作。
- 在之前 Amazon S3 存储桶的配置步骤里,我们启用了 Amazon S3 的版本控制来满足输入输出文件的多版本控制;如果希望细化结果输出为不同时期不同结果的话,可以在代码里加上相应的时间定义和输出文件格式的修改来实现这个目的。
- 在此场景中,Amazon Textract 对于文档内容提取和识别的自信度设置为 70%,Amazon Comprehend Medical 对于文本进行语义分析的自信度设置为 60%;在将该架构运用于生产中之前,针对实际文档的清晰度和结构完整性的不同,以及对于内容输出的准确性高低差异,可以相应地在代码里调整这两个值以满足最符合实际场景的要求。
参考文档
本篇作者