亚马逊AWS官方博客
利用 SageMaker Operator 简化 Kubernetes 上的机器学习任务管理
Amazon SageMaker Operator 可以帮助数据科学家以及开发人员利用Kubernetes的接口来创建和管理SageMaker的任务,如机器学习的模型训练、超参优化、批量转换以及实时推理等。如图所示,SageMaker Operator可以让 开发与运维人员可以通过kubectl命令行或者kubernetes api接口调用的方式来管理和使用SageMaker服务,它就像翻译器一样,在Kubernetes平台与AWS SageMaker 服务之间搭建了一座桥梁,让那些已经很很熟悉Kubenretes 的开发、运维人员在无需投入过多精力的情况下,即可快速地使用SageMaker服务。

应用场景
SageMaker Operator可以让那些已经很了解Kubernetes平台的开发人员以非常熟悉和友好的方式来使用SageMaker服务,它非常适用于以下一些场景。
1、项目团队已经非常熟悉了Kubernetes平台的接口和标准,由于项目需求,希望引进机器学习部分。由于人员数量有限,团队不希望再去单独维护一套机器学习平台,而是在充分利用已有的能力的基础上,适当引进第三方的工具和服务,快速地进行业务创新,降低学习和使用的成本,大幅度提升效率。
2、项目团队已在Kubernetes平台的基础上很好的实现了Devops,很多的业务模块都已经做到了持续集成与持续发布。机器学习部分只是整个业务系统中的一个模块,团队希望能够能将机器学习模块与其它业务模块统一进行工程化的管理,最终实现业务流程的全自动化。
技术原理
与其它第三方应用的Kubernetes Operator实现机制一样,SageMaker Operator由Kubernetes CRD和Controller两部分组成。如图所示,在安装好SageMaker Operator之后,SageMaker Operator会向Kubernetes 平台新注册一些与SageMaker服务相关CRD,同时以Pod的方式在Kubernetes Worker Node上运行SageMaker Operator Controller。当开发人员需要创建机器学习的任务时,首先需要在yaml文件中定义与CRD资源相关的关键配置参数,然后通过kubectl提交命令创建CRD资源,在CRD资源资源成功创建后,SageMaker Controller可以从Kubernetes API server监听到与该CRD相关的信息,之后解析参数并调用SageMaker服务,完成机器学习任务的创建。

Operator是Kubernetes中的一个重要概念,它可以让开发人员在Kubernetes的基础上进行高级的抽象和封装,从而可以更加容易地安装和管理复杂的应用。除了SageMaker Operator,很多公司和开源机构都会按照Kubernetes的标准把封装自己的Operator。Kubernetes Operator概念相对抽象,技术实现细节也比较复杂,若想对它更深入的了解,我们首先需要理解Kubernetes资源创建的机制和流程,同时也需要理解Kubernetes CRD和Controller等一些重要的概念,不篇博客不会就Kubernetes Operator的技术细节做过多的展开,关于更多有关Kubernetes Operator的介绍,请参考以下链接。
Kubernetes CRD: https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/
Kubernetes Controller: https://kubernetes.io/docs/concepts/architecture/controller/
Kubernetes Operator: https://kubernetes.io/docs/concepts/extend-kubernetes/operator/
实验演示
在本篇博客中我们将演示一个具体的例子,从而更好地说明如何如何利用AWS SageMaker Operator来实现机器学习任务的创建和管理。在该方案中,我们会用到以下服务
- AWS S3 :AWS对象存储服务,用于存放训练数据集以及机器学习模型。
- AWS EKS :AWS Kubernetes 托管服务,用于运行SageMaker Operator以及其它与Kubernetes相关的应用。
- AWS SageMaker: AWS机器学习托管服务,用于实现数据处理、模型训练、模型优化以及模型部署等机器学习任务的自动化创建和管理。Operator会自动解析参数并调用SageMaker服务完成机器学习任务的创建。
- AWS IAM: AWS安全管理服务,用于控制SageMaker Operator以及SageMaker对AWS资源的访问权限。
- AWS CloudWatch:AWS日志管理服务,用于记录SageMaker机器学习任务的日志同时将日志以事实的方式推送至AWS EKS。
实验内容
- 搭建EKS集群,配置IAM权限,安装SageMaker Operator。
- 通过kubectl命令创建SageMaker机器学习训练任务,提交任务后可以在SageMaker界面上看到机器训练任务,任务结束后确认模型会自动上传至S3。
- 通过kubectl命令创建SageMaker机器学习部署的任务,提交任务后可以在SageMaker界面上看到机器学习部署任务,SageMaker 会自动创建虚拟机并加载模型。

实验步骤
1、EKS集群搭建
EKS是AWS的Kubernetes托管集群,我们可以通过图形界面或者命令行的方式实现集群的创建。在本实验中,我们在ap-southeast-1 区域部署Kubernetes集群,该集群会包含一个Worker Node Group,该Node Group内有三个c5.xlarge的计算实例。在默认情况下,节点会采用高可用的方式均匀地部署在该区域的多个可用区内,如果有定制化需求,我们也可以通过指定命令行参数或者编写配置文件来指定可用区。
1.1 运行命令,创建集群。
eksctl create cluster --region <region-name> --name=<cluster-name> --nodes-min=3 --nodes-max=5 --node-type=c5.xlarge --ssh-access —ssh-public-key <ssh-keyname>
1.2 运行命令,查看Kubernetes节点的工作状态。
kubectl get node

2、创建OpenID Connect Provider
OpenID Connect Provider可以将Kubernetes内的Service Account与AWS IAM的role进行关联。在上文中我们提到过,SageMaker Operator Controller会以pod的方式运行在EKS的节点之上,该pod在监听到资源的创建信息后会调用SageMaker服务,而成功调用SageMaker的前提是该Pod要具备相应的权限,我们知道Kubernetes内Pod的权限分配一般是要通过service account传入的,所以OpenID Connect Provider的作用便是将集群外的IAM role与集群内的service account进行关联。
2.1 运行命令获取OIDC ID,将${CLUSTERNAME}替换成实际的EKS集群名称,将${AWSREGION}替换成实际的region。
aws eks describe-cluster --name ${CLUSTER_NAME} --region ${AWS_REGION} \
--query cluster.identity.oidc.issuer --output text
命令运行成功或会返回如下类似的结果。
https://oidc.eks.${AWS_REGION}.amazonaws.com/id/D48675832CA65BD10A532F597OIDCID
2.2 创建名为trust.json的文件,文件模板如下所示,将<OIDC ID>替换成为上一步获取的ID,将<AWS account number>替换成当前账号的ID,将<EKS Cluster region>替换成EKS的名称。
使用上一步创建成功的trust.json文件,并运行下面命令创建IAM role,将<role name>替换成一个自己需要的名称。
aws iam create-role --role-name <role name> --assume-role-policy-document file://trust.json --output=text
命令运行成功后会返回如图所示的结果。

2.3 运行下面命令,将SageMaker FullAccess的权限赋予上一步所创建的role。
aws iam attach-role-policy --role-name <role name> --policy-arn arn:aws:iam::aws:policy/AmazonSageMakerFullAccess
在完成role的创建和权限的配置之后,请记录role的arn,在后面创建SageMaker Operator时,我们需要为SageMaker Opearator配置该role。从而确保SageMaker Operator Controller具备操作SageMaker的权限。
3、安装SageMaker Operator
SageMaker Operator的安装方式很灵活,我们可以直接通过yaml文件进行部署或者通过Helm的方式进行安装部署,本次实验中我们通过yaml的方式进行部署。在前面的文章我们提到过,SageMaker Operator由CRD和Controller两部分组成,其中Controller会以Pod的形式运行在EKS Worker Node上。
3.1 运行命令下载用于安装SageMaker Operator的yaml文件。
wget https://raw.githubusercontent.com/aws/amazon-sagemaker-operator-**for**-k8s/master/release/rolebased/installer.yaml
3.2 下载完yaml文件后,进入文件内,找到 eks.amazonaws.com/role-arn参数项,将该参数对应的值更新为2.3步所创建role的arn。
3.3 运行下面命令安装SageMaker Operator。
kubectl apply -f installer.yaml
上文中我们曾提到,SageMaker Operator由CRD与Controller两部分组成,当SageMaker Operator安装成功后,SageMaker Operator会像Kubernetes集群内注册新的CRD,同时以pod的形式在Kubernetes Worker Node上运行SageMaker Operator Controller。
3.4 运行下面命令查看新创建的CRD。
kubectl get crd | grep sagemaker

3.5 运行下面命令查看新创建的SageMaker Operator Controller。
kubectl -n sagemaker-k8s-operator-system get pods

4 安装SageMaker Operator日志插件
SageMaker日志插件是SageMaker Operator中的一个可选项,SageMaker的任务在运行过程中会将日志推送至CloudWatch的日志组中,而SageMaker Operator日志插件则可以实时地将CloudWatch的日志收集到Kubernetes集群上,从而让开发人员通过kubectl命令就可以对SageMaker任务的日志进行查看。SageMaker Operator日志插件的安装是可选项,若安装则可以方便用户对日志进行管理,不安装也不会影响到任务自身的创建。
4.1 运行命令,安装SageMaker 日志插件
4.2 运行下面命令验证插件是否安装成功。
kubectl smlogs

5、创建机器学习训练任务
接下来,我们将创建一个SageMaker机器学习模型训练的任务,这里我们以SageMaker内置算法xgboost为例,对MINIST数据集进行模型的训练和部署。
5.1 运行命令,生成数据集并将数据集上传至S3存储桶。将<BUCKET_NAME>替换成自己的S3存储桶名称。
`wget https://raw.githubusercontent.com/aws/amazon-sagemaker-operator-for-k8s/master/scripts/upload_xgboost_mnist_dataset/upload_xgboost_mnist_dataset \
chmod +x upload_xgboost_mnist_dataset \
./upload_xgboost_mnist_dataset --s3-bucket <BUCKET_NAME> --s3-prefix xgboost-mnist`
查看S3存储桶,可以发现训练、测试和验证数据集都已成功上传至S3存储桶上。

5.2 运行命令创建SageMaker role,在创建SageMaker任务之前,我们需要为SageMaker创建好role,从而确保SageMaker可以顺利运行相关的任务。
5.3 准备机器学习训练任务yaml文件,在该文件中,我们需要配置与SageMaker训练任务相关的重要参数。关于机器学习训练任务yaml文件的模板请参考如下,请将变量部分替换成实际的参数,关键参数解释请参考模板中的备注信息。
5.4 运行命令,创建SageMaker训练任务。
`kubectl apply -f train.yaml`
5.5 运行命令,查看SageMaker训练任务状态。
`$ kubectl describe trainingjob xgboost-mnist
$ kubectl get trainingjob xgboost-mnist`

5.6 进入AWS控制台,查看AWS SageMaker训练任务状态。

5.7 任务训练结束后,模型会被自动存放至S3。进入S3控制台,可以查看到模型以及成功上传。

6、模型部署
模型训练结束后,我们将创建模型部署任务,SageMaker Operator会自动调用SageMaker服务完成模型的部署。
6.1 创建模型部署yaml文件,在该文件中,我们需要配置与SageMaker模型部署任务相关的重要参数。关于模型部署任务的yaml文件的模板请参考如下,请将变量部分替换成实际的参数,关键参数解释请参考模板中的备注信息。
6.2 运行命令查看模型部署任务状态
kubectl get hostingdeployments

6.3 进入AWS控制台,查看SageMaker模型部署任务。
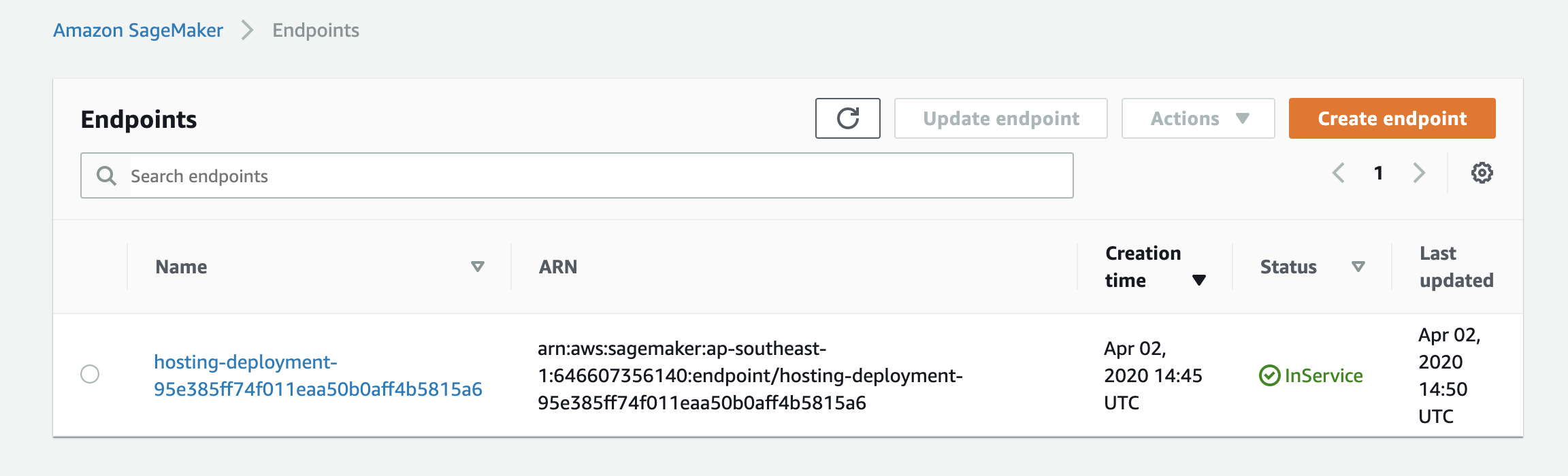
在上面实验中,我们举了模型训练和部署的例子,除了这两种任务,SageMaker Operator还支持参数优化、批量转换以及模型部署配置等其它任务,我们可以根据项目中的实际需求灵活选择相对应的任务。
总结
利用SageMaker Operator,项目团队可以使用所熟悉的Kubernetes命令以及接口管理复杂机器学习任务与流程,无需在已有的基础设施和平台上做出改动便可以快速地启动与机器学习相关的项目,从而极大程度地提升效率、降低成本。在真实的项目中,机器学习部分往往只是整个业务系统的一个模块,因此在设计方案时也需要系统性的考虑,除了机器学习流程本身,还需要考虑CI/CD、监控运维、安全控制、服务集成等多方面的因素,AWS可以做到服务之间的高度集成,在实际生产中,我们完全可以在上面实验案例的基础上进一步扩展,集成新的服务,从而构建一个端到端的解决方案。