亚马逊AWS官方博客
基于 Amazon Comprehend 的命名实体抽取及主题建模的社交媒体数据分析
摘要
自然语言处理 (NLP) 是语言学、计算机科学和人工智能的一个子领域,涉及计算机与人类语言之间的交互 (引自维基百科) 【1】。NLP 的目标是让计算机理解人类所说和所写的内容,并以同样的方式进行交流。 NLP 在过去十年中一直是一个有趣的领域,伴随着人们对自动化信息提取、处理和生成业务价值的期望越来越高。通常,专业知识领域的上下文和非结构化数据会给NLP增加额外的难度。
命名实体识别(NER)是 NLP 的一类子任务,专注于信息提取、实体定位和文本分类。它用于将非结构化文本中的命名实体映射到预定义的类别,例如人名、组织、医疗代码、货币价值 【2】。 NER 可用于构建语义搜索引擎并帮助提高文档的性能和索引。现在著名的 NER 平台包括 GATE、OpenNLP 和 SpaCy。
另一方面,主题模型是用来探索和提取文本主题的统计模型,而主题建模通常用于文本挖掘,以发现文本正文中隐藏的语义结 【3】。
在这篇博文中,我们演示了如何利用 NER 和主题建模将 Amazon 服务用于社交媒体数据分析。我们应用 Amazon Comprehend 作为 NER 步骤来微调 AWS 中的预训练语言模型。选择社交媒体数据的原因是为了简单起见,并避免行业(例如金融服务和医疗保健)特定术语带来的额外复杂性。事实上,对于热衷于通过社交聆听监控其品牌的企业来说,更好地了解社交媒体数据的背景和分类是至关重要的。
本文剩下的部分结构如下:
- 介绍Amazon Comprehend的NER和主题模型API
- 实验数据
- 系统性框架和数据流程图
- 结果和展望
-
Amazon Web Services在自然语言处理的云服务
Amazon Web Services 提供了广泛的自然语言处理服务,帮助客户轻松利用基于机器学习的模型,构建 AI 应用程序,用于文本分析、聊天机器人、语言翻译、情感分析、语音识别等领域。Amazon Transcribe 是一项自动将语音转换为文本的语言处理服务。它使用一种称为自动语音识别的深度学习过程,可用于为媒体资产添加字幕,将客户服务电话数字化为文本,以创建存档或开展进一步的分析。 Amazon Web Services 还提供了一项名为 Amazon Polly 的服务,用于将文本转换为逼真的人类语音。 Amazon Translate 是另一种基于深度学习的语言服务,可以支持71 种语言和变体之间的翻译。此外,Amazon Web Services 提供了功能强大的语言服务 Amazon Lex,它作为在Amazon Alexa上得到应用的底层技术,可基于其语音识别、自然语言理解和生成模型,轻松构建出成熟的聊天机器人。
除了上述服务外,Amazon Comprehend 是 Amazon Web Services 中另一项功能强大的自然语言处理服务,它使用机器学习技术来提取文本中的信息,并揭示有价值的见解。 Amazon Comprehend 原生支持实体识别操作,可以检测文本中的日期、事件、位置、人物等实体。除了预设的通用实体类型外,Amazon Comprehend 还支持自定义实体识别,让用户能够创建自定义模型来识别新的实体类型。
Amazon Comprehend 还提供主题建模 API,用于将文档语料库组织成主题。通过主题建模,每个文档都是整个语料库中主题的组合,而每个主题是单词的统计分布。主题建模提供的见解在信息检索、文档分类和文档摘要等领域有重要用途。Amazon Comprehend内置了两种主题建模算法:Amazon SageMaker 神经主题模型 (NTM) 和 Amazon SageMaker 潜在狄利克雷分配 (LDA)。在 SageMaker NTM 中,主题建模由基于神经网络的变分推理框架实现,该框架可以从语料库的单词分布中学习与文档相关的主题。
-
实验数据
本文中选用的实验数据来自第三方工作室所提供的W-NUT17的实体识别任务数据集【4】【5】。W-NUT数据在源数据的基础上,增加了人工合成的噪声文本已满足自然语言处理的需要。其中源数据包括,社交媒体,在线评估,众筹数据,网络论坛,临床诊断以及学习笔记等等。
数据集中包含了1000条带标注的tweets,一共65124个tokens. 评论文本来自Twitter, Stack Overflow, YouTube 以及Reddit. 命名实体的标注包括类别如下:
- 人名
- 地点 (包括地理位置和机构位置)
- 分组(如乐队,体育团队, 以及非企业单位)
- 创造性的工作 (歌曲, 电影, 书籍等等)
- 企业
- 产品(有形的产品或者定义良好的服务)
本文的开发训练样本和测试样本的划分来自2017年国际学术会议的参考文献 “Results of the W-NUT 17 Shared Task on Novel and Emerging Entity Recognition” 。具体情况如表1所示。
| 类别 | 训练 | 测试 |
| Documents | 1,008 | 1,287 |
| Tokens | 15,734 | 23,394 |
| Entities | 835 | 1,070 |
表 1: 命名实体数据的样本统计
-
系统架构及流程
下图展示了解决方案的架构:
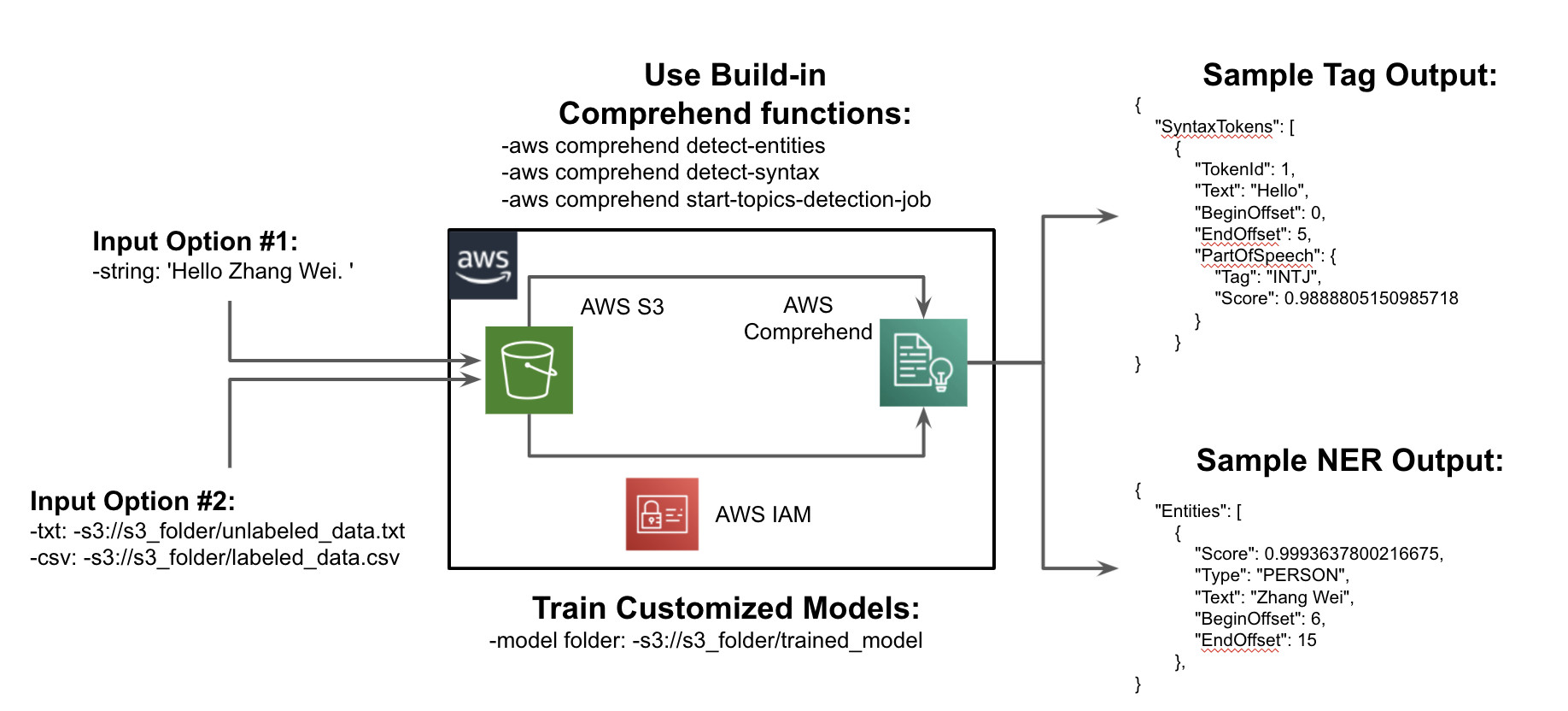
图1. 基于Amazon Comprehend 和NER的简单流程图
在此解决方案中,我们通过将 Amazon Comprehend 与 Amazon S3 用于 NLP 任务来展示其简单性。例如,我们可以将 Comprehend 函数与输入的句子字符串一起使用,如图1左上角所示。它使用内置的 Comprehend 模型来实现命名实体检测、单词标记等功能。或者,如图1左下角所示,我们可以提供 txt 或 csv 文件作为文本语料库来自定义训练模型。如图1右侧所示,返回的结果以json形式呈现以方便进一步处理。句子标记(右上)和句子 NER(右下)可以方便的进行进一步分析和建模。
使用 Amazon Comprehend 进行 NER 和主题建模相当简单,我们可以应用内置模型或自行训练模型。对于 NER 任务,我们只需提供目标句子、语言代码和区域即可使用理解检测实体 Amazon NER API 文档 。设置主题建模比 NER 任务稍微复杂一些,在主题建模任务中,我们需要首先使用启动主题检测作业 API ,通过指向包含请求数据的 json 文件来启动主题检测作业。或者,Amazon SDK 是另一种利用 AWS 理解主题建模的方法。有关 Amazon Comprehend 主题建模服务的详细使用,请参阅 Amazon 文档。
端到端的流程如下:
- 将一组带有实验数据的文本文件上传到 Amazon S3。
- 清晰标注所有文本文档的标签。
- 在 Amazon Comprehend 控制台上,使用 AWS Lambda 生成的数据集启动自定义 NER 训练作业
- 在 Amazon Comprehend 控制台上,启动自定义主题建模作业。
-
结论
我们开发了一个可以根据Amazon Comprehend指南来注释训练集的脚本。该注释内容一共有5列(如下图),其中包括了标明在S3上训练集文件名的‘File’,标明在训练集中具体第几行的‘Line’,标明在对应行上entity字段起始位置的‘Begin Offset’,同样标明在对应行上entity字段结束位置的‘End Offset’以及说明entity类型的‘Type’列。更多有关注释格式的信息,可以参照Amazon 文档(https://docs.aws.amazon.com/Comprehend/latest/dg/cer-annotation.html).

图2.训练集数据的注释
Amazon Comprehend要求每一个类型的entity至少输入200个不用的注释。然而所用的训练集中的‘product’和‘creative-work’类型分别只有139和137个注释,因此这两个类型的注释内容被暂时的排除在我们的数据集之外。在训练集文件和注释文件被上传到S3之后,Amazon Comprehend下面的custom entity recognition模组会使用这两个文件来训练模型,具体的操作页面如下图。

图3.基于Amazon Comprehend 的模型训练
训练过程大概需要25分钟左右完成。在训练过程中我们发现Amazon Comprehend会返回一个entity类型识别重叠的错误值,例如像‘Jessica Simpson’ 和‘Simpson’。因此,为了确保训练集和模型质量,我们只保留了全名。Custom entity recognition模组会自动测试并选出最合适的算法和参数,因此并不需要额外输入测试数据集。下图包含了最终模型结果的精确度,召回率和F1分数。Entity类型‘corporation’ 和 ‘group’的相对较低的指标可能是因为这两种类型的样本数据也相对较少。模型的平均F1分数在0.32左右,这个结果接近和其他用了同样训练数据集的研究【6】,表明了我们模型的可靠性。

图4.模型结果的性能参数
有了训练好的custom entity recognizer模型之后,另一组没有标签的数据集被放入到模型中来做预测,会生成一份带有named-entity recognition(NER)注释的新数据集。原始数据集和带有注释的新数据集会被分别放入Amazon Comprehend下面的topic modeling模组来生成不同的结果作比较。该模组采用了基于Latent Dirichlet Allocation(LDA)算法的模型来模拟topic modeling,这是一个在类似场景中非常常用的算法。更多详细信息可以在Amazon 关于topic modeling的文档中找到。(https://docs.aws.amazon.com/comprehend/latest/dg/topic-modeling.html)。
下图是使用了带注释的数据集所生成的topic modeling 模型的前五个主题以及对应的关键词和权重。

然后下图是使用了原始数据集(不带有NER注释)所生成的topic modeling 模型的前五个主题以及对应的关键词和权重。因为LDA算法自身的特性,即便是相同的主题,每一次运行之后其对应的关键词可能会有略微的差异。尽管如此,对于使用不同数据集的两个模型, Amazon Comprehend的topic modeling还是稳定的预测出了0号主题(topic0),并且两个模型的该主题的关键词也都相同。使用带NER注释的模型所预测出的1号主题和使用不带有NER注释的模型所预测出的2号主题也都包含了相同的关键词。

使用了带NER注释的模型预测出的2号主题和另一个模型的1号主题看上去可能都是和感情有关的主题,因为他们的关键词都包括了‘love’。但是我们提议的带NER注释的模型能够预测出更具有信息性的词汇,例如‘hate’,‘pain’和‘gallifreyan’等,这可能表明了该主题其实是有关小说或者电视剧的。带NER注释的模型的3号主题和不包括注释的模型的4号主题拥有几乎相同的关键词,说明这两个主题可能非常接近。最后,带NER注释的模型的4号主题预测出了包括‘location’, ‘calgary’, ‘adelaide’ 和 ‘europe’等关键词,表明了该主题很有可能和旅游相关,然而另一个不带NER注释的模型没有办法预测出类似的主题。
参考文献:
- https://en.wikipedia.org/wiki/Natural_language_processing
- https://en.wikipedia.org/wiki/Named-entity_recognition
- https://en.wikipedia.org/wiki/Topic_model
- https://github.com/juand-r/entity-recognition-datasets/tree/master/data/WNUT17
- http://noisy-text.github.io/2017/pdf/WNUT18.pdf
- https://www.aclweb.org/anthology/W17-4418/