亚马逊AWS官方博客
SHAREit 大数据平台 DataCake 在 Spark on EKS 的实践
一、前言
SHAREit(茄子科技)是一家主要从事移动互联网软件研发、互联网广告平台运营、互联网海外支付业务的公司,在全球市场一路高歌猛进,茄子科技产品矩阵全球累计安装用户量近 24 亿。目前已经成为印度,印尼,中东,南非,俄罗斯等国家和地区的“国民应用”,成为亿万用户获取内容、千万企业开辟市场的重要桥梁。
作为一家新兴的广告业务解决方案提供商,为了提高广告投放的精准度,提升用户体验,每天将启动几千台实例、运行数万的大批量任务,进行算法数据准备、用户行为分析、广告投放预估等,大规模的计算任务、复杂的任务调度、多元的任务类型、面向不同的用户需求,需要一个灵活调度、统一治理、快速响应、成本可控的大数据平台,使数据能够真正快速为业务服务,使业务人员、运营人员、数据科学家、算法人员、技术人员能够真正从数据中获取价值。
SHAREit 自研大数据平台 DataCake 正是在这样的背景下应用而生,经过 3 年迭代,逐步形成为一套一站式、自助化大数据平台,通过 SaaS/On-Prem 方式,为企业提供低门槛,低成本的大数据解决方案。DataCake 充分利用 AWS 云的强大、弹性的基础设施,实现资源的灵活调度、高效利用,例如,计算引擎基于 EKS 部署,底层计算资源优先调度 Spot 实例,实现 On-demand 和 Spot 实例的混合调度,充分利用了 Spot 实例的优势,节约成本。
在 DataCake 平台上,我们使用 Spark on EKS 来负责数据 Batch 计算的场景。Batch 计算对延迟不敏感,且 Spark 有完善的容灾机制,非常适合构建在 Spot 实例之上来充分利用 Spot 的成本优势。但由于 Spot 实例会有随时被回收的缺点,Spark 的容灾机制需要重新计算数据来弥补 Spot 回收带来的影响。
DataCake 一直在探索 Spot 实例的使用,我们通过自研的 Spark PVC Reuse 方案,最大限度地降低 Spot 回收的影响。目前 DataCake 线上全部的 Spark 任务都运行在 Spot 实例之上,整体成本降低了 39%。
二、DataCake 架构
2.1 功能架构
 |
DataCake 构建 AWS Infrastructure 层之上,提供一站式、自助化大数据服务,让企业拥有低门槛低成本的方案,拿捏数据生产资料,落实数据方法论,快速试错,获得竞争优势。 功能上,DataCake 可以分为两层,下层为湖仓一体的 PaaS,通过 Serverless 的方式满足 Adhoc/Streaming/Batch 多场景计算;上层为自助式大数据服务,包括高性能的数据分析、低门槛的数据集成和开发、简单易用的 BI 报表等。同时,DataCake 配备简单又强大的管理和治理平台,为用户提供一体化的 FinOps 方案。
2.2 技术架构
 |
架构上,DataCake 可以分为三层,基础设施层,数据源采用 S3 作为数据底座,计算任务中间存储层采用 EBS,计算任务采用 EKS 混合调度按需和 Spot EC2。湖仓一体的 PaaS 层采用可拔插的方式,兼容 Amazon EMR、Amazon Athena、Spark on EKS、Trino on EKS、Flink on EKS 计算引擎,通过 Serverless 的方式满足 Adhoc/Streaming/Batch 多场景计算。上层为自助式大数据服务,部署在 EKS 集群,包括高性能的数据分析服务,促进数据的应用、协作与分享,统一语法查询多源数据,智能地根据 SQL 特点和数据源类型适配最佳的计算引擎;低门槛的数据集成和开发服务,无需开发人员介入,业务人员即可完成整个 Data Pipeline 的建设,包括模版开发、可视化编排与运维等;统一数据管理来实现数据的注册、发现、管理、权限、数据血缘、数据质量等。
三、Spot 使用最佳实践
3.1 优化旅程
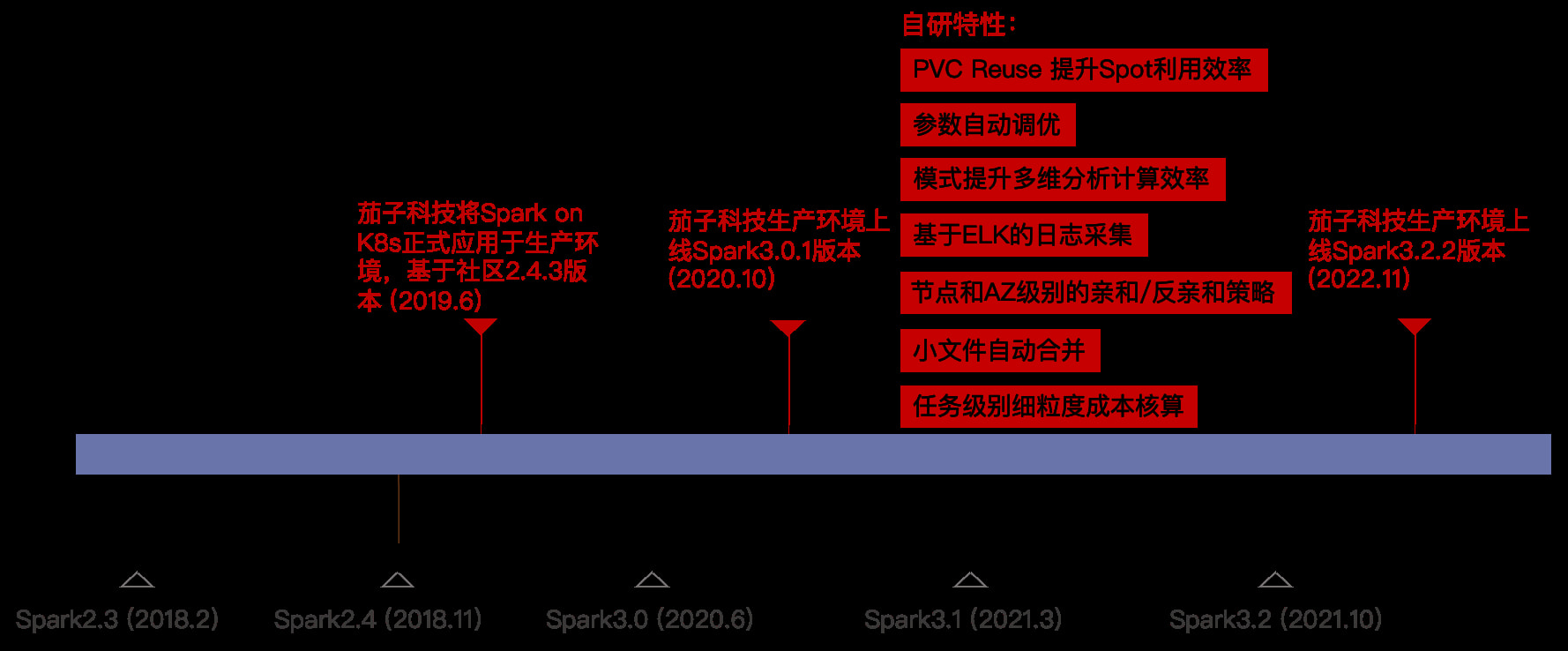 |
在 Batch 计算场景,DataCake 使用 Apache Spark 作为默认的计算引擎,Spark 版本的时间线如上图所示。为打造成稳定的、高性价比的 Batch 计算,DataCake 自研了 PVC Reuse 提升 Spot 利用率、Spark 参数自动调优、多模式多维分析等多个特性。相比社区 Spark,DataCake 的 Batch方案的 TCO 降低 50%。
3.2 Spot 回收对 Spark 的影响
Spark 运行过程中会通过 Shuffle 的方式来交换数据,Map 阶段会先将数据写到本地,然后 Reduce 阶段读取 Map 阶段产生的数据。当 Spark 运行在 Spot 实例上时,Spot 回收会导致 Map 阶段产生的数据丢失,当 Reduce 阶段读取数据时,Spark 需要重启 Map 阶段的计算,重新计算丢失的数据。如下图所示,Executor2 所在的 Spot 被回收时,上面的 Shuffle 数据丢失,当 Executor3 和 4 读取数据时会报 FetchFailed 异常,Spark 需要重新计算丢失的数据。Spot 回收不仅会影响计算的性能,还会产生额外的成本。
 |
3.3 PVC Reuse 降低 Spot 回收影响
DataCake 自研 PVC Reuse 特性来最大限度地降低 Spot 回收的影响。PVC Reuse 背后的逻辑比较简单,通过把 Shuffle 数据保存 PV 里,这样 Spot 回收不会导致 Shuffle 数据的丢失,新创建的 Executor 通过复用历史 PVC 来恢复 Shuffle 数据,从而避免数据重算。
 |
要实现 PVC Reuse,以下两点技术挑战需要克服:
- 新创建的 Executor 能够复用正确的 PVC
- Task 调度能够复用恢复的 Shuffle 数据
为了解决第一个挑战,我们在 Driver 里维护一个 PVC 的状态集如下图所示,这个状态集随着 ExecutorPodsAllocator 中接收 SnapShot 更新事件来更新每个 PVC 的状态,保证 Pod 状态和 PVC 状态一致。当因 Spot 回收而创建新 Executor 时,能够查找从而挂载正确状态的 PVC。
 |
为了解决第二个挑战,我们在 TaskSetManager 中处理 ExecutorLost 事件时,不立即重算丢失的 Executor 上的 task,当进入下一个 Stage 时,如果数据还未恢复才会执行 task 的重算。这样可以为从 PVC 里恢复 Shuffle 数据创造一定时间窗口。同时在 Executor 初始化 blockManger 后,立即上报本地 Shuffle 数据给 MapOutTrack,解决只有执行 Shuffle write 时才触发上报数据,可能会导致历史数据无法上报的问题。
3.4 实际效果
- 单个任务表现
下图是线上单个 Spark 任务在 Spot 回收严重时 PVC Reuse 的效果。可以看到,PVC Reuse 避免了大量的 Shuffle 重算,大大降低了 Spot 回收的影响。
 |
- 集群性能和成本
我们线上 Spark 集群已经全部启动 PVC Reuse 功能。可以看到,PVC Reuse 对于集群性能提升和成本降低都有明显的效果,任务平均执行时间下降 41%,整体成本下降 39%。
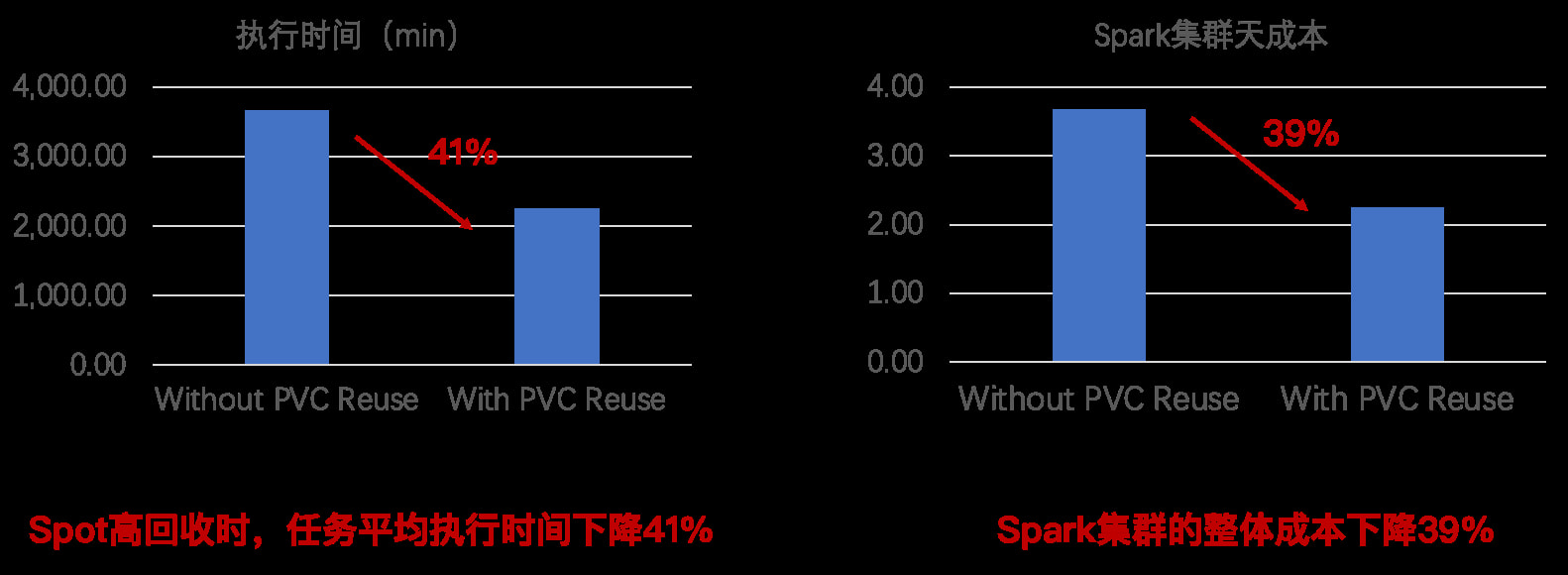 |
四、总结
SHAREit 自研一站式、自助化大数据平台 DataCake,采用 Spark on EKS 调度 Spot 实例来进行数据 Batch 计算。我们通过自研的 Spark PVC Reuse 方案,最大限度地降低 Spot 回收的影响,任务平均执行时间下降 41%,整体成本降低了 39%。
五、参考文档
[1] 一站式、自助化大数据平台 DataCake:https://www.datacake.cloud/
[2] Spot price:https://aws.amazon.com/ec2/spot/pricing/