亚马逊AWS官方博客
使用 Amazon Redshift 构建分层数据仓库分析 OLTP 数据
一.前言
随着企业数据量的不断增长,企业对于数据管理使用和用于分析的依赖性越来越强,一般而言我们会将数据的操作可以分为两大类,即OLTP(联机事务处理) 和 OLAP(联机分析处理),传统的数据库主要适合OLTP的应用,数据库更多的是提供数据的查询功能,基于事务保证ACID,数据量通常在GB的级别,更大的数据量往往导致系统出现瓶颈。如果在数据规模很大的情况下还进行额外的数据分析操作,则会导致数据库性能更严重的下降。
对于OLAP的应用场景,更多的不是查询的任务,而是基于大量的数据集,通过复杂的联表,分组,聚合,排序等操作,得出基于某些维度的分析结果,为决策层提供数据参考,同时可以通过对接BI工具,最大化地挖掘数据的价值 因此,如果我们需要将OLAP业务从现有OLTP业务中剥离出来,使用专业的数据仓库工具进行数据的管理和分析。 接下来,我们Amazon RDS 为例,介绍如何提取Amazon RDS中的OLTP数据并使用的数据仓库分层架构进行数据处理和分析。
二.数据访问和抽取
在数据进入Amazon Redshift 服务进行数据分析之前,亚马逊云计算提供了多种服务和方法访问或者抽取OLTP业务也就是RDS中的数据,其中包括以下方式:
- 使用Amazon Redshift联合查询来查询RDS数据,通过使用使用联合查询,您可以跨操作数据库、数据仓库和数据湖查询和分析数据。通过使用Amazon Redshift 联合查询功能你可以直接查询操作数据库,亦可以在查询过程中应用转换,并将数据加载到目标表中,而无需复杂的提取、转换、加载 (ETL) 管道。参考[1]
- 使用AWS Data Pipeline,AWS Data Pipeline 是一项 Web 服务,您可用于自动处理数据的移动和转换。使用 AWS Data Pipeline,您可以定义数据驱动的工作流,通过创建SqlDataNode和RedshiftDataNode和建立数据复制的管道,可以将将完整的 Amazon RDS MySQL 表复制到 Amazon Redshift 表.你也可以通过指定每日或每周复制任务将数据定期同步数据到Amazon Redshift中.参考[2]
- 使用AWS Database Migration Service (AWS DMS),AWS DMS可以快速,安全,低延迟,持续的将源数据库复制到支持的目标, AWS DMS支持对数据的一次性复制或持续复制,此外在持续复制的过程中我们还可以对数据源库(Schema),表进行选择、排除和重命名,这里我们主要使用AWS DMS将Amazon RDS中的数据持续复制到Redshift中。
- 其他方式如使用AWS Glue Elastic Views或使用RDS离线拷贝的方式,感兴趣可以参考[3]
三.数据仓库分层架构搭建
完成数据的访问和抽取工作后,我们需要在Amazon Redshift中完成数仓分层架构的搭建。一般而言,我们通常会将数据仓库分为ODS(原始数据层),DMS(明细整合层),DWS(数仓汇总层),ADS(应用服务层)。这些分层的具体作用和主要操作包括:
| 层名称 | 主要作用 | 主要操作 |
| ODS层 | 数据仓库的数据准备层,RDS数据源抽取到数仓中的第一个层 | 直接映射操作数据,尽可能保持数据原貌,不做修改,可以在这一层对数据进行分区和压缩操作,同时这一层也是一个原始数据的备份层 |
| DWD层 | 对ODS层的表按主题进行加工和划分以及数据清洗和映射,主要存放的数据包括事实表,实体表和维度表 | 数据清洗,脱敏,维度退化,减少事实表和维表的关联 |
| DWS层 | 汇总成分析主题域的数据,构建宽表供业务查询和分析 | 对数据做轻聚合,构建主题宽表,主题建模,维度建模等 |
| ADS层 | 存放结果类型数据,可以直接通过API或通过其他应用供前端业务直接使用,可提供数据报表 | 配置数据访问接口,视图访问等 |
通过将数仓分层,我们实现了以下优势:
- 把复杂问题简单化, 每一层只处理单一的步骤
- 数据结构清晰,每一个数据分层都有它的作用域,使用和维护的时候能够更便捷
- 提高数据的复用性,增加通用的中间层,增加一次计算结果的复用性,减少重复计算
- 隔离原始数据,加强数据安全,使真实数据与统计数据解耦开,避免跨范围访问数据
- 通过数据分层,提供统一的数据出口,统一输出口径
四.数据仓库分层架构在Amazon Redshift的实现
接下来我们利用Amazon Redshift提供的各种功能来实现上述的分层数据仓库,下图是分层数仓在Amazon Redshift中实现参考架构图:

-
ODS(Operation Data Store)层
ODS层作为数据原始数据准备层,需要关注数据的摄取情况和质量,如果使用AWS DMS 进行数据摄取需要注意对 Amazon RDS和Amazon Redshift做一些相应的修改配置,具体参考[4]和[5],在做数据迁移时,可以通过采取手动配置Json配置的方法实现数据库或表的过滤和重命名,也可以对表格中数据的数据类型进行修改,例如以下配置演示了迁移所有Amazon RDS Test数据库中的所有表格,但是排除DMS表格。
在迁移完成后的表格也可以依据来源,业务类型再进行二次命名和分类,方便后期分析。
2. DWD(Data warehouse detail)层
在完成数据原始表的摄取和装载工作后,需要再DWD层构建数据明细层,这一层通常需要创建明细表,在明细表创建的过程中,可以使用Amazon Redshift的最佳实践对明细表的分区和排序键和压缩方法进行设置,也可以后期通过ANALYZE命令进行分析,现在你也可以通过配置Amazon Redshift的集群参数组,将auto_analyze配置为True以启用自动分析功能。
除此之外,在DWD层需要做的另外一个重要操作是对数据进行清洗和转换操作,这个过程可以使用Amazon Redshift提供的存储过程进行处理,存储过程通常用于针对数据转换、数据验证和特定于业务的逻辑来封装逻辑。通过将多个 SQL 步骤组合到一个存储过程中,可以减少应用程序与数据库之间的往返次数。这里是Amazon Redshift存储过程的语句结构
同样的 ,也可以在使用视图功能,将视图封装到存储过程中,进一步加快数据的处理效率,后续只需要给存储过程传递相应参数即可进行数据的ETL工作,例如以下代码演示了将视图封装到存储过程中
此外,在这一层也可以通过Redshift Spectrum创建和使用外表,实现和外部数据的联合查询分析.
3. DWS(Data warehouse service)层构建
在DWS的层的数据就已经可以面向业务提供分析查询功能了,DWS 层主要的作用是将各DWD层处理后的表格汇总成分析主题的数据,构建宽表供业务查询和分析,例如需要分析网站的留存、转化、GMV 等指标。 这一层通常直接提供业务查询,因此也建议对DWS的表格进行优化,对于一些批量处理业务,如每日汇总分析等,可以使用Amazon Redshift提供的计划查询功能,典型的需要做计划查询的任务包括:
- 在非工作时间运行 SQL 查询
- 定期如每晚使用 COPY 语句加载数据
- 每晚或全天定期使用 UNLOAD 卸载数据
- 根据监管或数据保留政策从表中删除和归档旧数据
- 每晚备份系统表和数据等 要创建运行 SQL 计划计划,可以使用 Amazon Redshift 控制台上的查询编辑器。您可以创建一个计划,也可以直接将现有查询语句保存后添加为计划查询,以便按照与您的业务需求相匹配的时间间隔运行 SQL 语句。当计划查询运行时,Amazon EventBridge 会启动查询。
4. ADS(Application Data Store)应用层
ADS层在通常会使用DWD和DWS层更进一步进行数据抽取分析以提供结果报表,这些报表通常直接提供给到业务部门使用,下游直接对接业务系统或大屏幕应用。
如果需要将这些分析数据卸载或持久化到S3存储桶中,也可以通过Amazon UNLOAD功能,你可以使用 Amazon Redshift 支持的任意 SELECT 语句通过UNLOAD 命令将数据串行写入到一个或多个文件而且你可以通过在 UNLOAD 命令中指定 MANIFEST 选项来创建和列出卸载文件的清单文件(清单是一个 JSON 格式的文本文件,其中显式列出写入到 Amazon S3 的每个文件的 URL)。后期你可以使用例如Amazon Athena或其他服务对这些数据进行进一步的离线分析和查询。
5. 引入物化视图(Materialized View)
当数据在各层中流转时,通常通过调度设定固定的时间,去执行各层的更新和写入,这本身带来了数据实效性的滞后,这时我们可以引入物化视图来构建数据分层中的表,实现各层数据的自动增量更新。参考[6]
物化视图(Materialized View)本质是一种预计算,即把某些耗时的操作(例如JOIN、AGGREGATE)的结果保存下来,以便在查询时直接复用,从而避免这些耗时的操作,最终达到加速查询的目的。
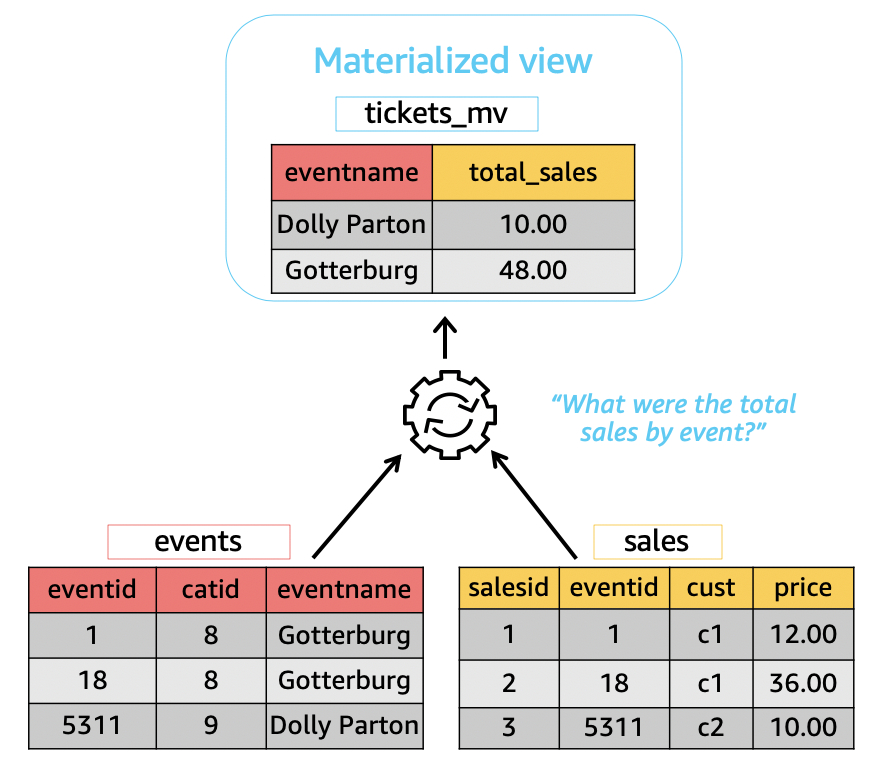
Amazon Redshift 提供了几种方法来保持物化视图的最新状态
- 自动刷新选项配置物化视图。当物化视图的基表有更改时,redshift 会标示这些基表的更改,并会自动刷新物化视图。此自动刷新操作在集群资源可用时运行,以达到最大限度地减少对其他工作负载的中断,同时保证物化视图尽可能快的更新的需求。
- 手动刷新物化视图。当我们不确定集群负载情况或强要求物化视图保持最新时,我们可以在执行物化视图查询前,先进行手动刷新后再进行查询,语句如下
REFRESH MATERIALIZED VIEW mv_name
我们可以使用create materialized view SQL语句来进行物化视图的创建例如
接下来 你可以像查询常规视图或表那样查询这套物化视图,使用 SELECT catgroup FROM tickets_mv 即可对该视图进行查询,您也可以在物化视图之上继续构建物化视图,已达到数据分层和业务需求快速开发的目的。
需要注意的是,构建物化视图需要满足以下要求
– 基表必须物理表或物化视图
– 不能使用UDF 函数
– 当基表为外部 schema 如通过 spectrum 查询的表时,无法使用 AUTO REFRESH YES 选项
五. 总结
Amazon Redshift 作为亚马逊使用速度最快且使用最广泛的云数据仓库,是构建云上数据仓库的最佳选择,你仍然可以将传统数仓的分层架构沿用到云上的数据仓库中,借助物化视图功能,同时利用Amazon Redshift 的各种新功能例如 AQUA(高级查询加速器),并发扩展,AutoWLM 等新特性可以极大的提升数仓集群的查询性能。此外,Amazon Redshift 能够与Amazon S3 等其他 Amazon Web Services 原生服务紧密集成,帮助用户以多种方式实现 Amazon Redshift 集群与数据湖间的交互,打通OLAP、OLTP与数据湖等各种数据源,加速构建企业智能湖仓。
参考:
- https://docs.aws.amazon.com/zh_cn/redshift/latest/dg/getting-started-federated-mysql.html
- https://docs.aws.amazon.com/zh_cn/datapipeline/latest/DeveloperGuide/dp-template-redshiftrdsfull.html
- https://aws.amazon.com/cn/glue/features/elastic-views/
- https://docs.aws.amazon.com/zh_cn/dms/latest/userguide/CHAP_Source.MySQL.html
- https://docs.aws.amazon.com/zh_cn/dms/latest/userguide/CHAP_Target.Redshift.html#CHAP_Target.Redshift.Limitations
- https://docs.amazonaws.cn/redshift/latest/dg/materialized-view-overview.html