亚马逊AWS官方博客
使用 Debezium 将 MySQL 数据导出到 Amazon S3
大数据应用需要针对海量数据进行统计操作,而数据库和数仓的存储空间有限。所以,我们通常会将数据从数据库中导出,并转换成列式格式的文件,存在 Amazon S3 这样的对象存储服务中。
我们可以通过扫描的方式查询这些文件中的数据,虽然效率有所降低,但是可以极大降低存储成本,并且提供近乎无限的扩展性。
要持续导出更新的数据,我们可以借助类似 Amazon Database Migration Service(DMS)这样的托管服务,也可以使用成熟的开源工具。前者可以提供更简便的体验,而后者则更为灵活。
在这篇文章中,我们来梳理下如何结合开源工具 Debezium 和 Amazon S3 Sink Connector,把 MySQL 数据库中的数据导出为 Parquet 格式,并存到 Amazon S3 桶中。
注意:本文基于 Amazon Linux 2 写作。CentOS 等类似的操作系统操作流程应该高度类似,其他系统可能需要调整服务的创建方式等细节。
整体架构
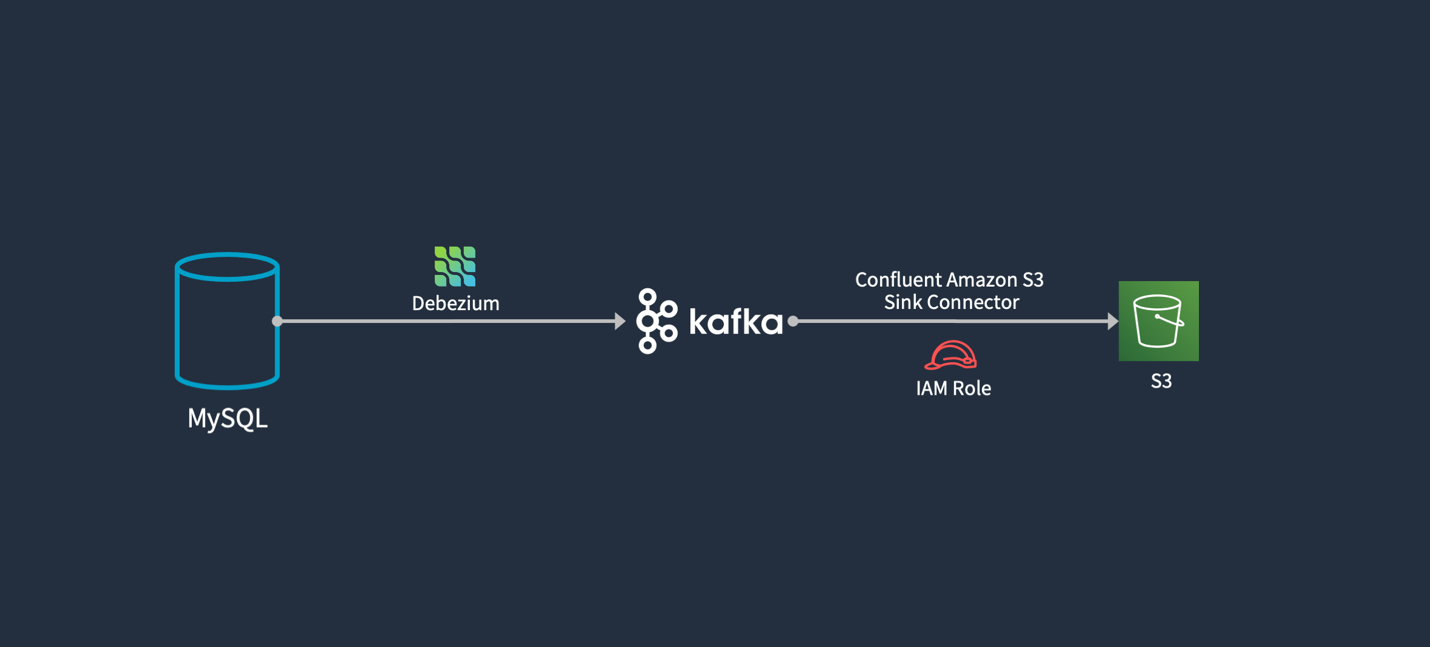
步骤概览
- MySQL 和 S3 桶准备
- 准备 IAM 角色
- 安装并配置 Kafka
- 安装并配置 Debezium
- 安装并配置 Amazon S3 Sink Connector
MySQL 和 S3 桶准备
在开始之前,我们需要确认 MySQL 数据库已经准备好,并且可以接受来自 EC2 实例 IP 地址的连接。如果安全性要求高,可以创建单独的只读用户。
此外,我们还需要在本区域创建一个 S3 桶,用于存放 Parquet 文件。
IAM 角色准备
MySQL 和 S3 桶都确认无误后,我们使用 Amazon Linux 2 镜像来启动一台 EC2 实例。我们为这台实例创建一个 IAM 角色,为该角色赋予权限,让它可以读写目标 S3 桶。将这个角色以实例配置文件的形式挂到实例上。
参考 IAM 策略如下:
注:权限配置相关步骤不是这篇文章的重点,所以此处略过。如有需要,请参考 IAM 相关文档。
接下来,我们使用 SSH 登录到这台实例,并使用 aws s3 ls s3://<BUCKET-NAME> 等命令确认其拥有对该桶有读写权限。
安装并配置 Kafka
接下来我们需要安装并配置 Kafka。
Apache Kafka 和 Kafka 连接器介绍
在正式开始安装配置之前,我们需要简单介绍一下 Kafka 和 Kafka 连接器(Kafka Connector)。
Kafka 是一款开源数据流应用。它可以高效地接收大量的数据,并提供给下游应用进行消费。为了方便用户把某些类型的数据输入和取出数据流,Kafka 提供了 Kafka Connect 框架,采用这个框架的客户端称作「Kafka 连接器」。既然是做输入和取出,就会有两种连接器:源连接器(Source Connector)负责输入,槽连接器(Sink Connector)负责取出。
之所以要介绍 Kafka 和 Kafka 连接器,是因为今天我们要介绍的两款工具都不是独立应用,而是以 Kafka 连接器的形式存在。
Debezium 是源连接器,负责读取 MySQL 的 Binlog 日志并且转化成 JSON 格式存入 Kafka 数据流。而 Amazon S3 Sink Connector 的名字就比较直白了,它是槽连接器,负责把 Kafka 里面的数据读取出来并以指定格式存到 S3 上。
所以,要使用这个方案,我们必须先安装 Kafka。接下来我们就先来安装并配置 Kafka。
我们通过 SSH 登录到实例上。注意 Kafka 通常需要 6GB 左右的堆空间(heap space)才能达到较好效果,所以我们应该尽量选择带有至少 8GB 内存的实例。
更新系统并安装 Java
因为我们要安装应用,所以在登录后,换用管理员身份,并对系统做更新。
接下来,安装 Java 环境,因为 Kafka 是用 Java 写的。
yum install java -y
创建 Kafka 用户和组
接下来,我们先为 Kafka 创建专用的用户和组,避免权限泄露。
useradd --system --no-create-home --shell /sbin/nologin --user-group kafka
这个命令会创建一个「服务用户」,用于运行服务。这个用户不会自动创建主文件夹,也没有登录的 Shell,无法作为一个普通用户来登录。此外,我们还创建了与用户名同名的组。
下载并安装 Kafka
Java 安装完成后,我们来下载 Kafka。本文写作时 Kafka 最新版本是 2.8.0,所以此处以 Kafka 2.8.0 为例。
打开 Kafka 官网下载页面。
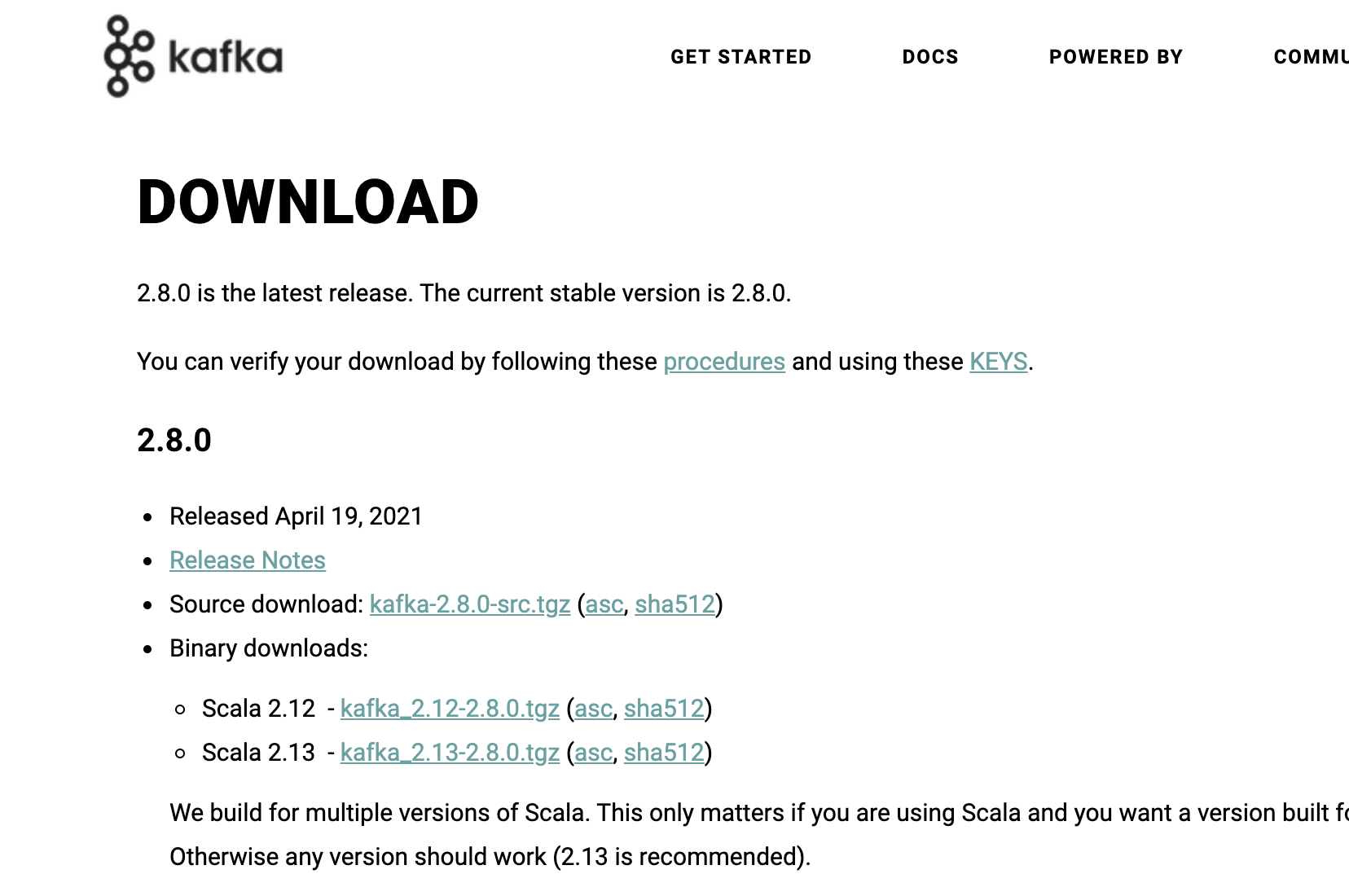
点击下载页面的「2.8.0 → Binary downloads → Scala 2.13」右边的链接,就会进入镜像选择页面。复制页面上方推荐的镜像链接。
接下来回到命令行,使用 wget 把 Kafka 下载到本地。注意:根据你所在地理位置不同,分配到的镜像网址可能不同,可将下面实例命令中的网址换成你所获得的镜像网址。
wget https://dlcdn.apache.org/kafka/2.8.0/kafka_2.13-2.8.0.tgz
再用下面的命令解压并删除原来的压缩文件。注意:版本不同则文件名可能不同,请将下面的文件名字更换成你所下载的文件名字。后续命令也需做好调整。
tar xfz kafka_2.13-2.8.0.tgz && rm kafka_2.13-2.8.0.tgz
接下来我们把 Kafka 移动到 /opt 目录。这个目录通常用于在 Linux 上安装第三方应用。在这里我们还创建了一个软连接 /opt/kafka 指向实际带版本的应用目录,这可以帮助我们快速找到 Kafka 应用目录,并且使用统一的软连接名字来做配置。这样,在应用版本升级的时候就仅需修改软连接,而不需要各处去修改配置文件。
这样,Kafka 就安装完毕。
配置 Kafka
Kafka 本身依赖 Apache ZooKeeper 来为其提供元数据服务,比如集群内有哪些节点,哪个是主节点,各个客户端目前的流位置读取记录等。这就要求 Kafka 的用户维护两套分布式服务,使系统变得庞杂而很难管理,所以在 Kafka 的发展路线图中很早就有了去除 ZooKeeper 的规划。去除 ZooKeeper 之后,Kafka 将通过自身实现的投票算法并用自身的数据流来存储元数据。
在这个版本中,我们已经可以不使用 ZooKeeper。为了简便起见,我们使用默认配置,单节点,并且不使用 ZooKeeper。
首先,我们按照 Linux 目录规则,把 Kafka 的配置文件放到 /etc/opt/kafka 目录。
注:此处我们没有修改配置文件,所以 Kafka 的日志(也就是持久化的流数据)会存放到 /tmp/kraft-combined-logs;如果对日志持久化有要求,可编辑文件修改 log.dirs 配置到其他目录。
接下来,到 Kafka 安装目录,使用以下命令,给集群配置一个 ID,并格式化本地存储流数据日志的目录。我们希望 kafka 用户能操作这个目录,所以用 sudo 换用 kafka 用户来执行格式化操作。
格式化完成后,我们先创建一个目录用于存储应用运行日志,并设置 kafka 用户为拥有者。
测试启动
接下来,我们测试把 Kafka 作为后台服务来启动。启动时设置 LOG_DIR 环境变量,这样日志就能放到 /var 目录下。
LOG_DIR=/var/opt/kafka bin/kafka-server-start.sh -daemon /etc/opt/kafka/server.properties
启动完成后,我们可以使用 jps 命令,应该就可以看到 Kafka。如果这一步因为堆空间不足而启动失败,请使用更大内存的实例。
配置 Kafka Connector
为了保存各种 Kafka 连接器并方便管理,我们建立一个专属目录。
再把 Kafka Connector 的配置文件复制到 /etc/opt/kafka 文件夹。
cp /opt/kafka/config/connect-standalone.properties /etc/opt/kafka/connect-standalone.properties
本次使用最基础的单机版 Kafka Connector,所以只需要把存放 Connector 的目录加到 connect-standalone.properties 配置文件后即可。
安装并配置 Debezium
接下来我们安装 Debezium。
先下载 Debezium。写作本文时,最新的版本是 1.6.1,所以以此为例。
我们到 Debezium 官方下载页面。点击「1.6.1.Final → Downloads」,在下拉菜单中右键选择「MySQL Connector Plug-in」并复制其链接地址。
回到命令行,使用 wget 下载,解压并删除原压缩文件。
wget https://repo1.maven.org/maven2/io/debezium/debezium-connector-mysql/1.6.1.Final/debezium-connector-mysql-1.6.1.Final-plugin.tar.gz
tar xfz debezium-connector-mysql-1.6.1.Final-plugin.tar.gz && rm debezium-connector-mysql-1.6.1.Final-plugin.tar.gz
接下来我们配置 Debezium。先创建一个配置文件夹。
mkdir -p /etc/opt/kafka-connectors
然后写入配置。
部分配置解释如下:
- hostname = 数据库节点地址,如果使用 Amazon RDS,可以选择只读节点
- server.name = 在这个 Kafka 流中唯一标识这个数据库服务器,使用英文字符即可
- include.list = 输入一个或多个数据库名字用英文逗号区分,只有这里设置了的数据库会被导出
- history.kafka.topic = 用于存储数据库表结构变化的 Kafka 主题,仅供 Debezium 内部使用
- schema.changes = 是否捕捉表结构变化并存到数据库名称同名的 Kafka 主题,此为外部使用,与上一条不同
注:此处未对 UPDATE 和 DELETE 做过滤处理,如果源表有此两项操作,会生成同 ID 的记录,造成重复。如果需要过滤该类记录,可使用 transforms.unwrap.add.fields=op 配置加入原始的 op 字段,该字段值 u 代表 UPDATE 而 d 代表 DELETE。
Kafka 主题名称使用 <SERVER_NAME>.<DATABASE_NAME>.<TABLE_NAME> 这样的格式。
安装并配置 Amazon S3 Sink Connector
接下来我们安装 Amazon S3 Sink Connector(下简称「S3 Sink」)。到官方下载页面找到下载链接,并到命令行下载。本文写作时版本为 10.0.2,所以以此为例。
注:Amazon S3 Sink Connector 是研发 Kafka 的 Confluent 公司出品,也可以通过 Confluent 的工具 confluent-hub 下载。此处为简便起见采用手动下载安装。因为官方未直接提供下载链接,可能需要用户在点击「Download」按钮后,在浏览器的控制台复制其下载地址,或者,先下载到本地机器再通过 scp 等工具传至 Kafka 所在的机器。下方 10.0.2 的官方下载地址可直接使用,但无法确保永久有效。如已失效,请用户从官方页面找到最新地址后下载。
使用找到的下载地址,我们下载、解压 S3 Sink,并移动到我们的 Connector 专属目录。
接下来,写入 S3 Sink 相关配置。
部分配置解释如下:
- region = S3 所在区域
- bucket.name = S3 桶名
- dir = 用于存放 MySQL 日志的 Kafka 主题,名称格式参见前面 Kafka 配置
- class = 分区(数据落盘)的规则,此处我们使用 Kafka 所在机器的时间来分区,详见此处
- duration.ms = 分区区间,此处设置为 10 分钟,意味着每个数据文件最多包含 10 分钟的数据
- format = 使用时间分区法时,目录的命名规则
- size = 分区要求,当未落盘的数据量达到此数字时创建新的数据文件进行落盘
注:如果当前区间内累积的数据量未达到 flush.size 要求则可能落盘操作会暂停直到数据量达标为止。如需在经过一段时间后强制落盘,则需要使用 rotate 相关配置。此外,本次使用 Kafka 所在机器的时间来分区,如果需要使用数据中的某个字段作为分区依据,需要修改 timestamp.extractor 配置。详见S3 Sink 文档。
生成服务
因为我们是手动安装的 Kafka、Debezium 和 S3 Sink Connector,所以还需要手动把他们添加成服务,并且加上自动重启。这样,在机器重启时,整套体系还可以继续运转。此外,如果 Kafka 和 Kafka Connector 进程被终止了,还能尝试自动重新启动起来。
下面是生成 kafka.service 的代码。
然后是生成 kafka-connect.service 的代码。
创建好服务单元文件(Service Unit File)后,启用这两个服务。
systemctl enable kafka kafka-connect
从执行结果可以看出,systemd 应用在 /etc/systemd/system/multi-user.wants 下创建了两个软连接。在系统启动时,当网络相关服务都已启动,用户也可以登录的时候,systemd 就会按指示启动这个目录下的服务。
启用服务
启用服务和激活服务是两个步骤。现在,我们可以使用 reboot 命令重启系统,看服务是否会正常启动,也可以直接使用 service kafka start 的形式直接启动这两个服务。测试启动之前可以 kill 掉之前测试运行中的 Kafka 进程。
使用 root 身份,运行 jps 命令,我们应该能看到 Kafka 和 ConnectStandalone 进程和对应的进程 ID(PID)。
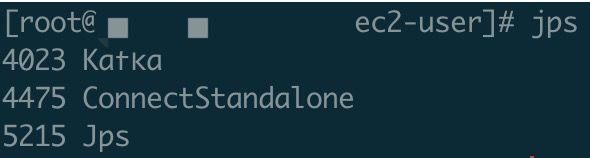
为测试服务在遇到错误时是否能重启回复,我们可以对 Kafka 的两个进程执行 kill <PID>(把 <PID> 更换成实际 ID),并马上 jps,确认进程消失。稍等几秒,再执行 jps,确认进程已经自动重启。
测试
此时,我们可以连接到 MySQL 数据库,选择 Database,并且插入 10 条以上的数据,则应该可以在 S3 桶中看到对应的数据文件。

我们可以使用 Hive 等数据库,创建外表,对这部分数据进行查询。更简便的方式,是使用 Amazon Glue 爬虫对这个桶内的数据进行爬取,自动创建和更新数据表,并且使用 Amazon Athena 对数据表进行直接查询。

排错
这套方案涉及到 Kafka、Kafka Connect 两个组件,又有 MySQL 和 Amazon S3 作为外部依赖,所以中间还是有诸多出错的可能。在这里,我简单列一些辅助排查的方法和命令。
MySQL
Kafka 实例需要能访问到 MySQL 数据库,并且有权限读取 Binlog 日志。这一点可以通过在实例上安装 MySQL 客户端来进行验证。验证用户权限可以使用 SHOW GRANTS [ FOR user ] 命令。
Debezium 建议的权限是:
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'user' IDENTIFIED BY 'password';
此外,为了快照的可靠性,还建议赋予该用户 LOCK TABLES 权限。
S3
Kafka 实例需要读写 S3 桶。因为我们使用了 Amazon Linux 2,自带了 AWS 命令行工具,所以可以直接使用命令做测试。
Java
Kafka 和 Kafka Connect 都是基于 Java,所以我们可以使用 jps 命令来确认目前正在运行的 Java 应用进程和它们对应的 PID。通常 Kafka 的 Java 进程名会是 Kafka 而单机版的 Kafka Connect 的则会是 ConnectStandalone。
比如在启动 Kafka 之后迅速执行 jps 可以看到 Kafka 进程,而稍等数秒再执行则发现进程消失,就说明进程遇到了问题执行失败,就可以去看 Kafka 日志了。
运行此命令时请注意切换到管理员用户,否则它只能列出当前用户运行的 Java 程序。
Kafka 和 Kafka Connect
Kafka 如果出错了,日志可以在 /var/opt/kafka 中找到。其中:
- log 是 Kafka 日志,启动失败等信息会在里面
- log 是 Kafka Connect 日志
后台服务
我们的服务已经做了设置,如果 Kafka 和 Kafka Connect 出错,就会自动重启。但如果你发现 Kafka 持续不可用,那么可能需要临时停止这两个服务进行排查。
停止服务的命令是:
启动的命令是:
查看最近的服务日志的命令,并持续跟踪输出的命令是:
journalctl --no-page -u kafka -f
后续
现在,Kafka 和两个 Kafka Connector 服务就已经运行在实例上,源源不断地把新数据导出到 S3。
如果我们希望能让整套系统分布式运行,形成高可用的架构,就还需要对 Kafka 和 Kafka Connector 做分布式部署,这个留待后续文章详述。此外,这套体系目前仅支持增加数据,如果需要捕捉变更,则较为麻烦,还有改进空间。
此外,为了简便,我们把 Debezium 和 Amazon S3 Sink Connector 启动到了一个 Kafka Connect 进程中,这会让他们的日志混合在一起,并且其中一个失效也会影响另一个。在实际生产环境中,我们可能更希望它们各自跑在单独进程中,方便管理。
总结
本文介绍了使用 Debezium 将 MySQL 数据用 Parquet 格式持续存储到 Amazon S3 的方式。作为 DMS 服务之外的另一个自建方案,它很灵活而且调试方便。希望对读者有所帮助。