亚马逊AWS官方博客
使用JDWP远程debug Amazon EMR上离线&在线应用
为什么需要remote debug
熟悉大数据应用的数据分析师或者开发小伙伴都会在大数据集群上使用Spark,Flink进行离线,实时在线业务应用的开发和部署。
Spark,Flink是典型的分布式计算框架,其内部各种算子,设计原理,运行机制等博大精深,而大数据集群通常是通过Yarn进行计算资源调度,在业务逻辑复杂和海量数据量场景下,业务系统常常会遇到各种疑难问题,比如
- 明明代码在自己的环境上运行正常, 但在QA及生产环境运行报错
- 测试环境dummy数据运行正常,但在生产数据一上来就会异常
- 生产环境上程序突然hung住
- 本地单机环境逻辑正常,生产集群环境异常
…etc
在开发测试环境,我们可以用业务数据来debug本地程序进行调试,但如果生产上业务急需解决,或者业务不允许生产数据下载到开发测试环境,这时候就需要远程debug来快速trouble shooting或者进行性能调优
基于此需求,在AWS的云上大数据服务平台Amazon EMR上,我们可以使用JAVA技术栈的JDWP技术,对Spark,Flink两大最流行的离线、实时计算框架应用,在on yarn的hadoop集群上进行远程debug,这样开发的小伙伴能快速调试和定位生产环境中遇到的各种问题,而不用下载业务数据并在本地,或者只能依赖输出日志去推断问题,简化整个业务敏捷开发的运维和调优。
Amazon EMR remote debug实现原理
Spark, Flink均为Java/Scala应用,Java应用程序可以利用JVM的JDWP功能进行远程debug,JDWP是JVM自带的java调试传输协议,即远程的JVM作为debug Server,本地java程序作为调试器,二者之间通过RPC传输协议进行与本地debug一样的断点,单步等调试操作。
关于JDWP具体内容本文不再赘述,感兴趣的小伙伴可以参考jdwp官方说明
Amazon EMR同样使用JDWP作为远程debug的具体实现,结合Amazon EMR的实例组,安全组和组件配置工具,可以方便修改生产环境JDWP开关,针对spark-submit,spark-sql,flink session,flink per job等各种模式下enable/disable远程debug,具体实现方式如下图所示:

在Amazon EMR上开启 JDWP debug非常方便,EMR console控制台提供了图形化的配置功能,针对不同节点实例组和不同类型的组件的配置文件,可以以表格或者json方式修改其jdwp的启动参数值,保存后Amazon EMR会更新其配置到需要的所有选择节点,并自动重启需要的组件服务。
以Flink 流式计算应用开启jdwp为例,在已经启动的EMR集群上,登录Amazon EMR控制台,进入如下所示配置界面,修改主实例组下flink-conf的configuration group下的配置参数,即对应/etc/flink/conf/flink-conf.yaml 配置文件:

调试完成后,同样通过配置界面,删除主实例组下flink-conf的相应配置,EMR会使用默认配置覆盖(清除)JDWP调试参数,即可关闭远程debug开关。
下文会详细介绍如何使用开启和使用JDWP调试在Amazon EMR上的Spark和flink离线&在线应用。
离线应用(Spark) remote debug
Spark 不同提交客户端spark-sql, pyspark都是底层用的spark-submit,比如Spark-sql:
spark-submit是通过spark-class,spark-class会去执行 java -cp xxx的命令 来启动spark:
因此只需要在spark-submit提交时通过—driver-java-options或者spark.driver.defaultJavaOptions动态增加JDWP参数,针对该job启动JDWP(如果是调试executor 闭包代码,则启动时应该加—conf spark.executor.defaultJavaOptions动态参数),如下示例所示:
我们以一个sample的出租车trip统计分析的程序来测试远程debug
sample的spark df统计分析代码如下:
EMR啓動一个新的集群,ideal 本地IDE中配置jdwp启动参数:

Host:提交spark-submit的节点DNS,在本例子中就是EMR主节点
Port:JDWP的远程监听端口,本例子中是EMR主节点的5005端口
suspend=y:submit的spark job会hung住等待debug的本地程序连接
设置好idea中的JDWP之后,在EMR主节点通过spark-submit提交job:
spark-submit —conf “spark.executor.memory=4G” —conf “spark.dynamicAllocation.enabled=true” —num-executors=4 —conf “spark.executor.instances=4” —class org.example.SQLContextExample —master yarn —deploy-mode cluster spark-scala-examples-1.0-SNAPSHOT.jar
此时spark job的启动过程会hung住,等待在本地的代码客户端的连接,我们在相应位置打好断点, 然后点击debug按钮,过一会儿之前spark-submit的代码就会在EMR上运行起来, 然后看到命中你在本地打的断点, 如下

至此即可像本地应用程序一样使用F8,F9 ,F7等快捷键方便的进行spark job的代码调试。
实时在线应用(Flink)remote debug
Flink 框架debug
Flink框架本身包含很多设计模式,比如watermark机制,checkpoint快照实现高可用,pressure反压等,如果你想了解具体实现的细节,比如StreamGraph 如何生成, Exactly Once 究竟如何实现的,那么调试Flink框架本身是一个很好的学习方式
Flink Job 提交也是一个拉起一个JVM虚拟机,我们同样以job提交的EMR 主节点为例,配置客户端远程debug的JDWP参数
与上文所述一样,EMR控制台上的“配置”选项下,flink-conf分类即对应/etc/flink/conf/flink-conf.yaml配置文件中,
- flink jobmamager的JVM启动参数,如果我们调试flink主流程(StreamEnv, TableEnv等),在这里面配置JDWP,以便我们的本地flink main方法的代码能连上flink的jobManager
- flink taskmanager的JVM启动参数,如果我们调试Flink流的分布式处理的具体task,配置这个参数,Flink job task执行时,本地flink source,sink,processor的代码会连接到taskManager
- env.java.opts.client: Flink client 的job提交JVM启动参数,如果我们调试Flink client客户端(如JobGrap),在这里配置JDWP,以便flink run提交时本地代码能连上其监听端口
注意EMR5.25以上Flink JobManager和TaskManager均可以启动在core或者task节点,因此最好JDWP的端口分开,避免在同一个节点上JM和TM的远程debug端口冲突(本例中JM的端口设置为5005,TM的端口为5006)
以Flink client job提交使用的Flink框架源代码的CliFrontend为例,我们在idea中设置remote JVM debug的调试配置如下:

Host:配置为提交flink job的客户机,这里为EMR集群主节点
Port:远程调试端口,与上文我们开启的EMR上server端端口一致
Module classpath:我们要调试的flink框架模块,这里为Flink-client
Flink源代码中框架设置debug断点如下:

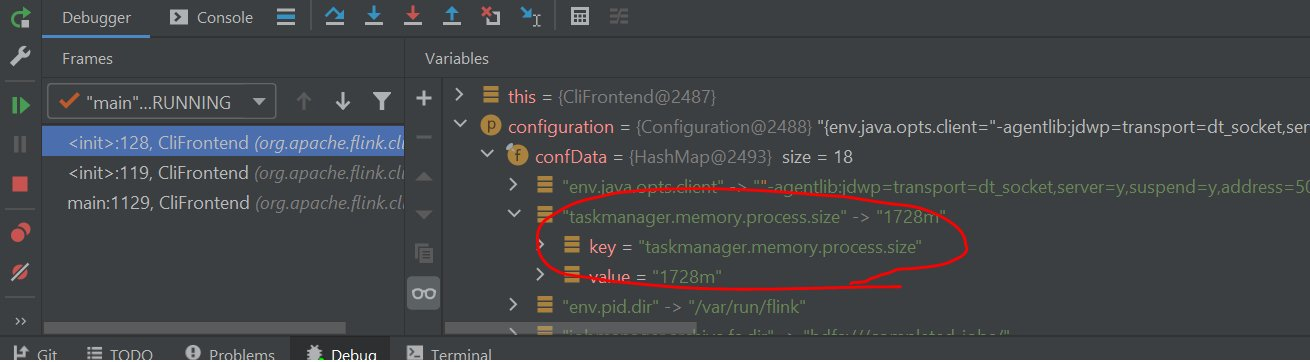
可以看到程序停在flink框架源代码的CliFrontend类我们设置的断点处,其flink job提交的参数在调试模式下清晰可见
Flink job (on Yarn) debug
以一个简单的flink 读入文本作为流的sample程序进行远程debug,sample代码在aws的Kinesis stream应用的awslab github下,可以方便的下载
在idea里面Remote JVM debug配置并启动debug

注意:
Hosts选择其中一台core或者task节点主机DNS,因为Flink on yarn模式,jobManager是在其中一台core节点上拉起来的,而taskManager在core和task节点上启动
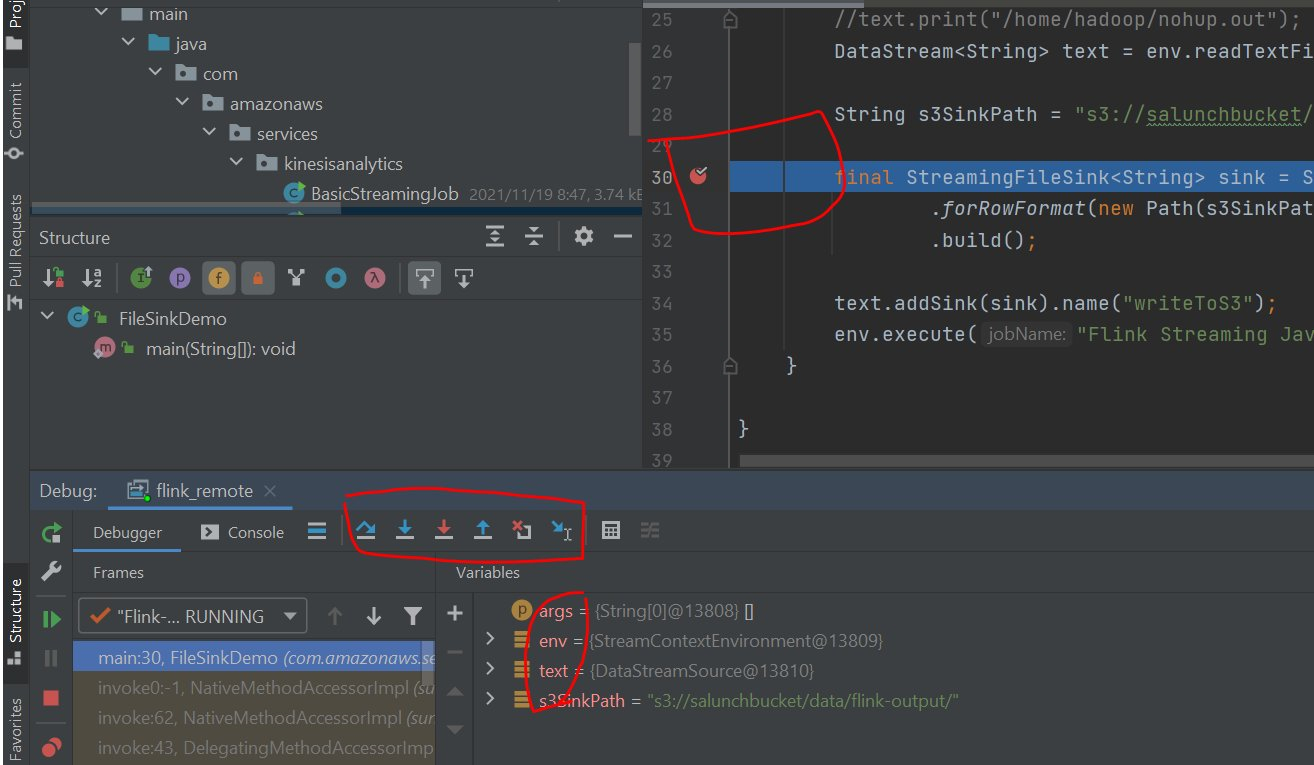
在EMR主节点提交Flink job:
可以看到本地的app应用代码停在断点处,后续操作与上文中flink框架代码的本地调试一样,F8单步,F7跳出,F10 step into…etc
小结
本文介绍了在AWS的云上大数据服务平台Amazon EMR上,对Spark,Flink两大最流行的离线、实时计算框架应用,在on yarn的hadoop集群上进行远程debug的具体实现,文本可作为相关开发的小伙伴使用JDWP远程debug的startup快速上手和不同场景下(框架源代码,应用代码,提交客户端…etc)调试生产环境的指导手册。
参考文档
JDWP:https://docs.oracle.com/en/java/javase/18/docs/specs/jdwp/jdwp-spec.html
EMR configuration组件配置:https://docs.amazonaws.cn/emr/latest/ReleaseGuide/emr-release-6x.html#emr-630-release
AWS Flink lab示例代码:https://github.com/aws-samples/amazon-kinesis-analytics-taxi-consumer