亚马逊AWS官方博客
使用 Amazon SageMaker 加速自定义 AI 医疗影像算法构建
随着 AI 在医疗领域的快速运用与推广,越来越多医疗用户在 AWS 平台寻求弹性,安全,高效,高可用的解决方案。同时,基于医疗的行业属性,医疗用户要求在云上的机器学习流程一方面与 AWS 其它服务如监控,安全,审计等服务集成,以符合 HIPAA 要求;另一方面能贴合本地业务环境无缝集成,灵活部署。随着益体康,晶态科技等优秀的医疗+AI 用户通过在 AWS 上快速搭建服务平台,他们极大缩短了产品从构想、开发,再到部署的时间,同时,越来越多的用户发现 AWS 技术上的优势可以让医疗 AI 用户的模型训练变得更为轻松。这篇 blog 旨在以开源的医疗影像数据与语义分割算法为例,探索 Amazon SageMaker 加速自定义医疗 AI 影像分割算法构建的业务场景与优势。
Amazon SageMaker 是一项完全托管的服务,可以帮助开发人员和数据科学家快速构建、训练和部署机器学习 (ML) 模型。SageMaker 完全消除了机器学习过程中每个步骤的繁重工作,让开发高质量模型变得更加轻松。比起本地 AI 集群:SageMaker 有以下优势:
- SageMaker 天然考虑了数据安全,权限控制,审计合规,版本控制等问题,确保在 AI 项目的每一步都符合全球范围内各个行业的规范以及 AI 工程化的最佳实践。
- SageMaker 把 AI 开发步骤解耦合为数据 processing,estimator 与 fit,deploy 等操作,通过sagemaker的API或者SDK指令触发,做到一键运行,高弹性,最大限度在集群调度,分布训练,数据交互,版本控制等问题简化运维工作。同时,控制台可以实时监控各项任务的参数与指标,在算法快速迭代期让开发者对于各项任务一目了然。最后,SageMaker Studio (Web可视化界面), Autopilot (自动构建、训练和调优模型),Experiments (组织、跟踪和评估训练运行情况),Debugger (分析、检测和预警训练过程中的问题)等新特性的推出,SageMaker 越来越成为 ML 用户的全开发周期中的有力助手。
- SageMaker 与其他 AWS 服务高度集成,帮助用户实现精细化权限控制,训练/部署过程中的详细性能监控与事后审计,自动生成报表,帮助用户完成合规需求。同时通过与数据库,大数据分析,数据流,ETL 等服务集成,帮助用户真正做到高效数据洞察,数据驱动决策。
- SageMaker 支持训练使用 spot 实例,通过利用 AWS 云中未使用的 EC2 容量,最高节约90%的训练成本,模型部署使用 Elastic Inference , 可以节约75%的 serving 成本。
SageMaker 控制面板
在 AWS 主控制台搜索 SageMaker 服务,进入后可见 SageMaker 的控制面板。
左侧栏笔记本下,选择笔记本实例,可以看到该区域的笔记本实例列表。如果您需要创建笔记本实例,请点选右上角创建笔记本实例,然后参考https://docs.aws.amazon.com/zh_cn/sagemaker/latest/dg/gs-setup-working-env.html步骤。

在笔记本实例状态是绿色 ‘InService’ 时,点击打开 Jupyter 或者打开 JupyterLab 。右上角点击 New,Terminal


数据集下载与预处理
本次实验所用数据集及代码存储在S3存储桶中,请进行下载,然后输入 unzip blog_files.zip 进行解压。
训练
打开 train.py ,可以看到我们的原始脚本。注意在第30行到39行,分别是本地训练(不使用 SageMaker )和云上训练(使用 SageMaker )所用的模型路径和训练路径。这是因为在 SageMaker 封装 Estimator 进行训练时,训练实例会先从S3指定存储桶下载原始数据到 os.environ[‘SM_INPUT_DIR’],训练好的模型放到 os.environ[‘SM_MODEL_DIR’],在模型结束后上传到 S3 到指定位置。同时,我们通过 argparse 传参。

然后,我们可以在控制台中运行 python 检验脚本正确。

接下来,我们进行脚本初始化,并指定 S3 路径与区域。

上传原始数据到 S3

查看数据


接下来,我们引用 sagemaker 下的 PyTorch 类封装 Estimator 。如果您希望再一次在笔记本实例上检测训练流程是否合理,可以指定 train_instance_type=’local’/’local-gpu’。
您也可以通过训练实例进行训练,灵活加速已有脚本的训练进程。特别的,您还可以使用spot实例进行训练,最多可节省90%的训练成本。为了使用 spot instance , 在封装 estimator 时请设置 train_use_spot_instances=True ,同时参考https://docs.aws.amazon.com/sagemaker/latest/dg/model-managed-spot-training.html#model-managed-spot-training-using设置train_max_wait。
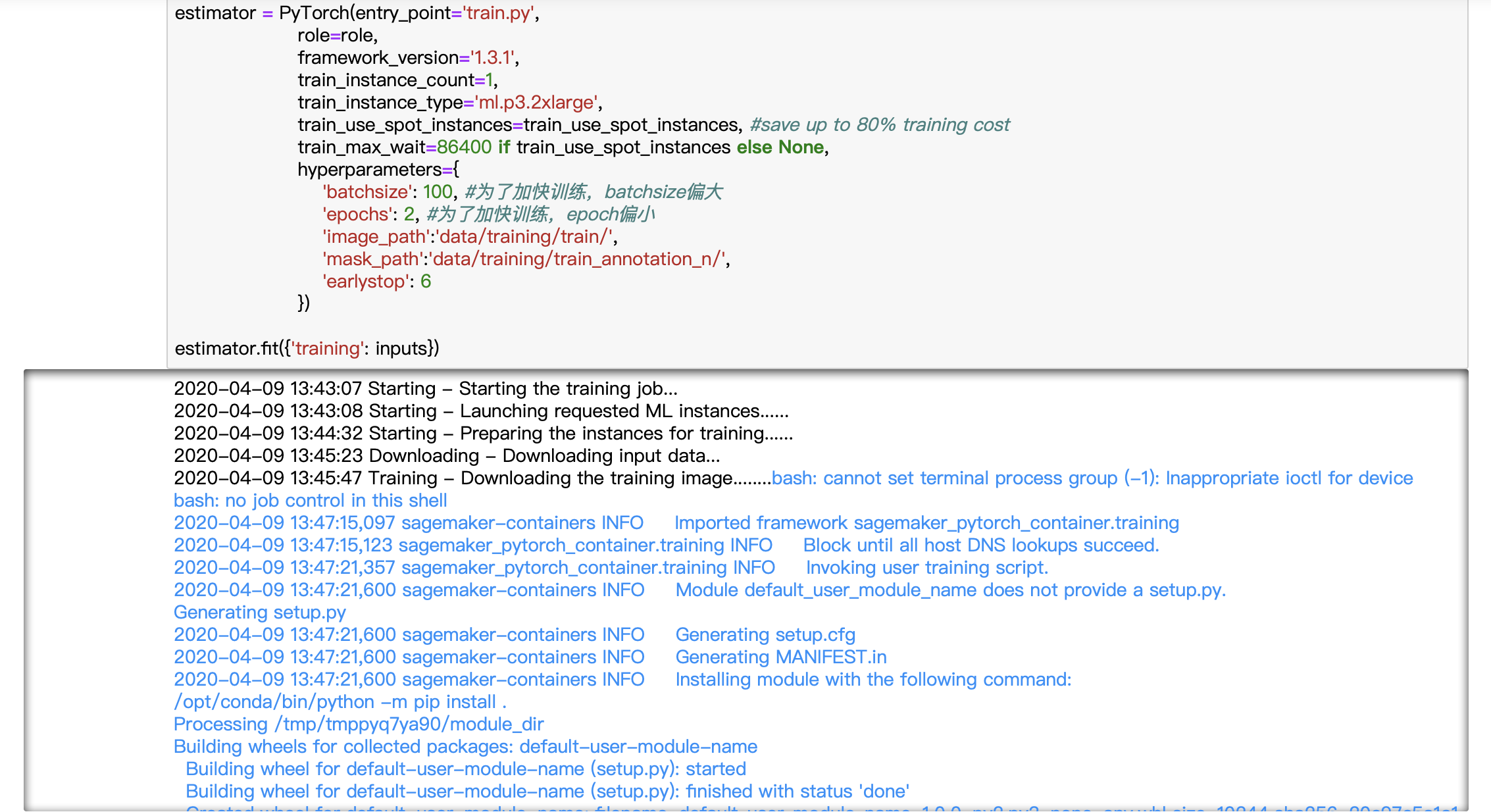
在控制台训练任务下,可以看到该任务正在训练。点击名称,可以看到训练任务的详细配置与监控信息。

点击任务名称进入详细配置页

监控指标

注意:在训练过程中停止 jupyter notebook , 并不会停止训练进程,可以在控制台训练任务下看目前进行的训练进程。
在训练结束后,我们可以看到训练成功的信息与 spot instance 的成本节省信息。

部署
SageMaker 支持一键式部署,如以下代码所示:

删除

需要注意的是,使用 SageMaker Torch 自带推理镜像需要在脚本中指定 model_fn 等推理所用 function, 具体请参考https://sagemaker.readthedocs.io/en/stable/using_pytorch.html。
在实际项目中,针对医疗用户的灵活部署需求,我们可以在 S3 中获取训练好的数据。请在训练任务的配置页找到输出项并到 S3 对应路径下载并解压。

将解压后的文件通过各深度框架命令 load 模型,即可自定义部署。

本地推理

修改epoch和batchsize后,可以得到更准确的预测结果。
总结
在本篇 blog 中,我们以针对医疗公开数据集的语义分割算法为例,探索医疗领域深度学习本地算法迁移到 Amazon SageMaker 的步骤与优势。希望通过我们的努力,让医疗 AI 开发者能够全力以赴优化算法,造福患者。