Analytik in AWS
Ein umfassender Funktionsumfang für jeden Analytik-Workload, optimiert für Preis, Leistung und Skalierung
Übersicht
AWS bietet umfassende Funktionen für jeden Analytik-Workload. Von der Datenverarbeitung und SQL-Analyse bis hin zu Streaming, Suche und Business Intelligence bietet AWS eine unübertroffene Preis-Leistungs-Verhältnis und Skalierbarkeit mit integrierter Governance. Wählen Sie speziell für bestimmte Workloads optimierte Dienste oder optimieren und verwalten Sie Ihre Daten- und KI-Workflows mit Amazon SageMaker. Ganz gleich, ob Sie Ihre Datenreise gerade beginnen oder eine integrierte Lösung suchen, AWS bietet Ihnen die richtigen Analytik-Funktionen, mit denen Sie Ihr Unternehmen mit Daten neu erfinden können.
Mit Analytik in AWS greifbare Geschäftsergebnisse erzielen
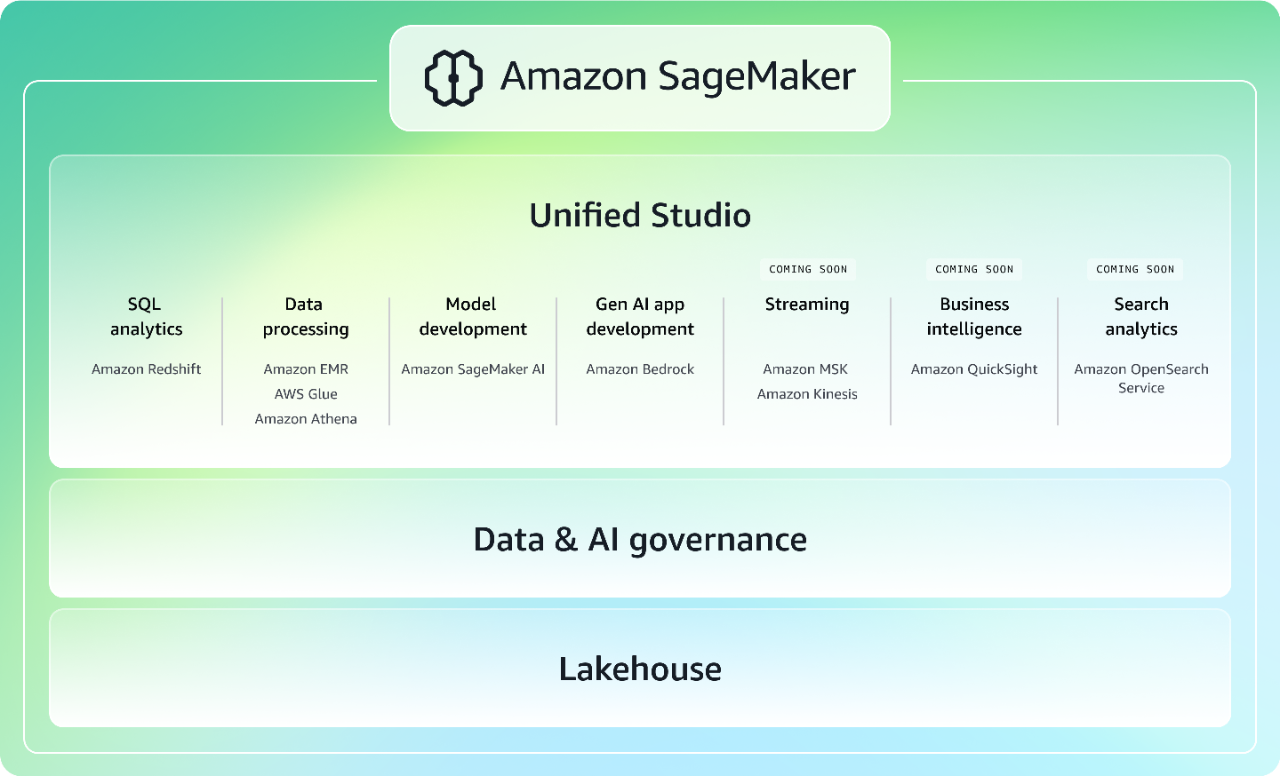
Daten, Analytik und KI mit einem integrierten Erlebnis beschleunigen
Die nächste Generation von Amazon SageMaker vereint die weit verbreiteten AWS-Funktionen für Machine Learning (ML) und Analytik und bietet ein integriertes Erlebnis für Analytik und KI mit einheitlichem Zugriff auf alle Ihre Daten. Kollaborieren und entwickeln Sie schneller von einem einheitlichen Studio aus mit vertrauten AWS-Tools für Modellentwicklung, generativer KI-Anwendungsentwicklung, Datenverarbeitung und SQL-Analytik, beschleunigt durch Amazon Q Developer, den leistungsfähigsten generativen KI-Assistenten für die Softwareentwicklung. Greifen Sie auf sämtliche Daten zu, unabhängig davon, ob sie in Data Lakes, Data Warehouses, Drittanbieter- oder Verbunddatenquellen gespeichert sind, mit integrierter Governance, um die Sicherheitsanforderungen des Unternehmens zu berücksichtigen. Weitere Informationen zu SageMaker.
Unterstützung von Multi-Cloud-Strategien mit AWS
AWS bietet eine umfassende Palette leistungsstarker Services für Analytik, die es ermöglichen, auf Daten nahtlos zuzugreifen und sie nahtlos zu verarbeiten, sowohl in Multi-Cloud- als auch in Hybridumgebungen. Diese Flexibilität erreichen Sie durch Verbund-Abfragen, Datenintegration, sichere Datenübertragung und Kompatibilität mit offenen Standards – so können Sie aus all Ihren Daten Erkenntnisse gewinnen, unabhängig davon, wo diese gespeichert sind.
Mit Amazon Athena können Sie Daten aus einer Vielzahl externer Datenquellen abfragen und daraus Erkenntnisse gewinnen, darunter Azure Data Lake Storage, Google Cloud Storage, Microsoft SQL Server und viele andere – ohne dass die Daten kopiert oder transformiert werden müssen.
AWS Glue vereinfacht die Erfassung, Aufbereitung und Integration all Ihrer Daten in jedem Umfang und bietet Konnektoren für über 100 verschiedene Datenquellen, darunter Cloud-Speicher, Datenbanken und Analytik-Services. Dank der Zero-ETL-Integrationen von Glue lassen sich Daten aus Drittanbieteranwendungen wie Salesforce, SAP, Facebook Ads und Instagram Ads ganz einfach direkt in Ihre AWS-Lakehouses, Data Lakes und Data Warehouses aufnehmen und replizieren. AWS Glue bietet zudem Dateninteroperabilität durch Support für offene Standards wie Apache Hive, Apache Parquet und Apache Iceberg.
Die nächste Generation von Amazon SageMaker basiert auf einer offenen Data-Lakehouse-Architektur und bietet einen einheitlichen Zugriff auf Data Lakes und Data Warehouses in AWS sowie auf verbundene Datenquellen wie Google BigQuery und Snowflake. Diese Lakehouse-Architektur ist vollständig kompatibel mit Apache Iceberg und bietet Ihnen die Flexibilität, auf Daten direkt vor Ort mit beliebigen Iceberg-kompatiblen Tools und Engines zuzugreifen und sie abzufragen.
Analytik im Dienste von Mensch und KI
Leistungsstarke Analytik im skalierten Umfang mit speziell entwickelten Services für die Speicherung, Abfrage, das Streaming, die Verarbeitung und die Verwaltung von Daten. Von Open Table Formats (OTF) bis hin zu agentenbasierter Infrastruktur entwickelt AWS Analyse-Engines und -Anwendungen für die sich rasch wandelnde Welt der Analytik weiter. Erfahren Sie in dieser Sitzung, wie AWS optimierte Lösungen bereitstellt, die sowohl für Benutzer als auch für automatisierte Workflows konzipiert sind.

Services
|
Analytik-Kategorie
|
Beschreibung
|
AWS-Service und Funktionen
|
|---|---|---|
|
Streaming
|
Erstellen, skalieren und betreiben Sie Data Pipelines und Anwendungen in Echtzeit, ohne sich um die Verwaltung der Infrastruktur kümmern zu müssen. |
|
|
Data Lakehouse, Data Warehouse, Data Lake
|
Greifen Sie auf all Ihre Daten in Data Lakehouses, Data Warehouses und Data Lake zu und analysieren Sie sie. |
|
|
Datenverarbeitung
|
Mithilfe von Open-Source-Frameworks Daten analysieren, vorbereiten und für Analytik und KI integrieren. |
|
|
Business Intelligence
|
Erstellen, entdecken und teilen Sie aussagekräftige Erkenntnisse mithilfe moderner interaktiver Dashboards, pixelgenauer Berichte, Abfragen in natürlicher Sprache und eingebetteter Analytik. |
|
|
Suchanalytik
|
Die Echtzeitsuche, Überwachung und Analyse von Geschäfts- und Betriebsdaten sicher freischalten. |
|
|
Daten- und KI-Governance
|
Katalogisieren, ermitteln, teilen und Gewährleisten der Governance von Daten, die in AWS, On-Premises und bei Drittanbietern gespeichert sind. |
Die wirtschaftlichen Gesamtauswirkungen der modernen Datenstrategie von AWS
Laut Forrester wurden durch die moderne Datenstrategie von Amazon Web Services Kosteneinsparungen und Geschäftsvorteile ermöglicht.
Statistiken
Haben Sie die gewünschten Informationen gefunden?
Ihr Feedback hilft uns, die Qualität der Inhalte auf unseren Seiten zu verbessern.