Was ist der Unterschied zwischen Cassandra und HBase?
Was ist der Unterschied zwischen Cassandra und HBase?
Apache Cassandra und Apache HBase sind zwei NoSQL-Datenbanken, die Daten in einem nicht tabellarischen Format speichern. Beide speichern Daten als Schlüssel-Wert-Speicher in einer Big-Data-Infrastruktur, um riesige Datenmengen präzise und effizient zu verwalten. Sie weisen jedoch architektonische Unterschiede auf, die für unterschiedliche Anwendungsfälle besser geeignet sind. Cassandra bietet beispielsweise eine schnelle Lese- und Schreibleistung, und HBase bietet eine höhere Datenkonsistenz. HBase ist auch effektiver für den Umgang mit großen, spärlichen Datensätzen. Unternehmen verwenden Cassandra und HBase für verschiedene Big-Data-Anwendungsfälle.
Ähnlichkeiten: Cassandra und HBase
Cassandra und HBase sind zwei NoSQL-Datenbanken, die Milliarden von Datensätzen speichern, verarbeiten und abrufen können. Sie weisen in den folgenden Bereichen überschneidende Ähnlichkeiten auf.
Big-Data-Anwendungen
Sowohl mit Cassandra als auch mit HBase können Sie riesige Mengen unstrukturierter, nicht relationaler Daten speichern. Sie unterscheiden sich von einem herkömmlichen Datenbanksystem, das Daten in einfachen Spaltenzeilen speichert. Sie können Cassandra und HBase verwenden, um Bilder, Audio, Videos und andere unstrukturierte Datentypen für die Verarbeitung in großem Maßstab zu speichern.
Open Source
Die Apache Software Foundation veröffentlicht und verwaltet Cassandra und HBase als Open-Source-Projekte. HBase wurde auf der Grundlage des von Google BigTable eingeführten und 2008 von Apache veröffentlichten Konzepts entwickelt. Cassandra ist eine Initiative, die ins Leben gerufen wurde, um die Probleme mit der Inbox-Suche von Facebook zu lösen. Es verwendet bestimmte Features von BigTable und andere von Amazon Dynamo.
Skalierbarkeit
Sie können HBase skalieren, um den wachsenden Datenanforderungen gerecht zu werden, indem Sie dem HBase-Cluster weitere Regionalserver hinzufügen. Das NoSQL-Datenbanksystem kann dann Datenknoten auf neue Regionen verteilen, wenn diese eine bestimmte Kapazität überschreiten. Ein Cassandra-Cluster kann auch mehrere Knoten unterstützen, um seine Datenverwaltungsfunktionen zu skalieren. Durch das Hinzufügen weiterer Knoten können Sie Daten effektiv gleichmäßig verteilen und Verkehrsengpässen vorbeugen.
Datenwiederherstellung
Datenknoten in Cassandra und HBase sind fehlertolerant. In Cassandra unterstützt jeder Knoten die Datenreplikation. Eine Schreiboperation wird automatisch an alle Knoten ausgegeben, die den jeweiligen Daten zugewiesen sind. HBase verfolgt einen ähnlichen Ansatz zur Datenduplizierung, der durch das Hadoop Distributed File System (HDFS), auf dem es ausgeführt wird, automatisiert wird. Das HDFS erstellt und verwaltet Datenduplikate auf verschiedenen Servern. Beide NoSQL-Datenbanken duplizieren Datenknoten in verschiedenen physischen Netzwerken auf der Grundlage des Replikationsfaktors, um das Risiko eines netzwerkweiten Ausfalls zu verringern.
Pfad schreiben
Sowohl Cassandra als auch HBase organisieren Daten in Spalten. Beim Speichern von Daten sucht jede Datenbank nach der entsprechenden Spaltenfamilie, die verwandte Informationen zusammenfasst. Beide Datenbanken schreiben die Daten auch in die Protokolldateien, wenn die Datenbank sie an die Spalte anfügt oder speichert.
Architektonische Unterschiede: Cassandra vs. HBase
Cassandra und HBase arbeiten mit unterschiedlichen Eigenschaften des CAP-Theorems. Das CAP-Theorem spezifiziert, dass verteilte Systeme zu einem bestimmten Zeitpunkt zwei der folgenden Eigenschaften besitzen können:
- Konsistenz
- Verfügbarkeit
- Partitionstoleranz
Da Partitionstoleranz für Datenbanken, die riesige Datensätze speichern, obligatorisch ist, unterscheiden sich Cassandra und HBase in Verfügbarkeit und Konsistenz. Cassandra bietet aufgrund seiner Peer-to-Peer-Knotenanordnung eine hohe Verfügbarkeit und Partitionstoleranz. HBase bietet Konsistenz mit Partitionstoleranz, da ein einziger HBase-Primärserver Daten auf alle Knoten repliziert.
Als Nächstes erläutern wir weitere architektonische Unterschiede in der Art und Weise, wie beide Datenbanken Datenanfragen verwalten.
Datenmodell
Sowohl Cassandra als auch HBase organisieren Daten in Gruppen, Zeilen und Spalten, aber jede Datenbank tut dies mit unterschiedlichen Layouts. In Cassandra werden Spalten mit verwandten Daten in Zeilen unter einer breiteren Kategorie gespeichert, die als Schlüsselraum bezeichnet wird. Eine Cassandra-Datenbank könnte beispielsweise den folgenden Keyspace, die folgenden Spaltenfamilien und die folgende Zellenanordnung enthalten:
- Keyspace : CustomerOrders
- Spaltenfamilie: Client
- ID, FirstName, LastName
- Spaltenfamilie: Bestellungen
- ID, Artikel, Preis
- Spaltenfamilie: Client
Die Client-Spaltenfamilie befindet sich in einer Partition über der Orders-Spaltenfamilie. In praktischen Anwendungen stapelt ein Keyspace mehrere Familienspalten zusammen.
Die HBase-Architektur hat ein Layout, das dem traditioneller relationaler Datenbanken ähnelt. Anstelle einer ID für jede Spaltenfamilie verwendet HBase sequentielle Zeilenschlüssel in einer Tabelle. Anschließend werden Spalten, die zu derselben Spaltenfamilie gehören, nebeneinander angeordnet, damit Daten leicht abgerufen werden können. Hier ein Beispiel:
- Tabelle; CustomerOrders
- Zeilenschlüssel, Spaltenfamilie: Kunde {Vorname, Nachname}, Spaltenfamilie: Bestellung {Artikel, Preis}
Mehr über relationale Datenbanken lesen
Die wichtigsten Komponenten
Cassandra verwendet eine Technik namens konsistentes Hashing, um es jedem Knoten zu ermöglichen, bestimmte Daten in seinem Peer-to-Peer-Netzwerk schnell zu finden. Zu den wichtigsten Komponenten gehören die Tabellen Memtable, Commit Log und SS. Zusammen bilden sie den Schreibpfad für die Knoten, Rechenzentren und Cluster in der Cassandra-Architektur.
HBase befindet sich auf dem HDFS. Es verwendet den HBase-Primär-, Regionsserver und Zookeeper für die Datenverwaltung.
Cassandra bietet Datenmanagement und Datenspeicherung unabhängig, und HBase benötigt externe Systeme für die Datenspeicherfunktionen.
Kerndesign
Cassandra läuft auf der Active-Active-Architektur, bei der jeder Knoten auf Schreibvorgänge und Anfragen reagiert. Selbst wenn ein bestimmter Knoten die angeforderten Daten nicht speichert, ruft er sie mit einer Peer-to-Peer-Kommunikationsmethode, dem sogenannten Gossip-Protokoll, von anderen Knoten ab.
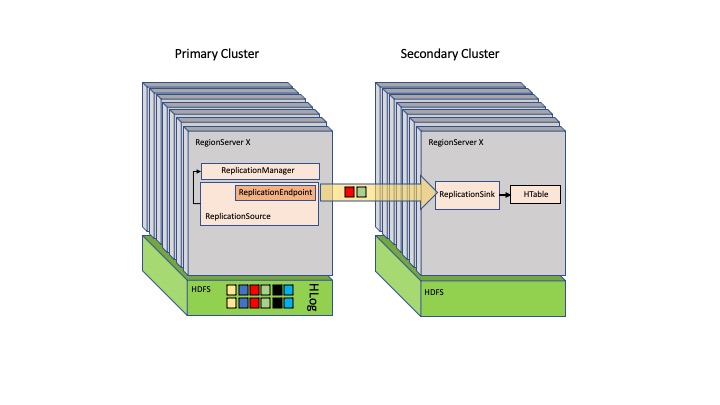
HBase verwendet ein primäres und sekundäres Setup, bei dem das primäre HBase-System die Kontrolle über die Regionsserver anderer Knoten hat. Die HBase-Architektur stellt eine einzige Fehlerquelle dar, wenn keine Replikate des HBase-Primärsystems vorhanden sind. Sie können mehrere HBase-Primärknoten duplizieren, aber nur einer übernimmt die Verantwortung für alle Regionalserver.
Die folgende Abbildung zeigt das primär-sekundäre Setup in HBase.
Abfragesprache
Cassandra ermöglicht die Datenmanipulation in der Datenbank mit Cassandra Query Language (CQL). Sie verwenden CQL, um Datensätze in beschreibenden Anweisungen hinzuzufügen, zu entfernen oder zu aktualisieren, die SQL ähneln. Die HBase-Abfragesprache besteht aus grundlegenden Shell-Befehlen, deren Erlernen mehr Aufwand erfordert.
Aufführung: Cassandra vs. HBase
Sowohl Cassandra als auch HBase bieten Hochgeschwindigkeitszugriff auf große Datensätze für Big-Data-Analytik. Die Datenbanken weisen Leistungsunterschiede in den folgenden Aspekten auf.
Latenz
Latenz ist die Zeitlücke zwischen dem Senden einer Anweisung an das Datenbanksystem und dem Speichern oder Abrufen von Daten. Im Allgemeinen weist HBase eine geringere Latenz auf, wenn die Anzahl der Datenlese- und Schreibvorgänge zunimmt. Das Gegenteil gilt für Cassandra, das größere Verzögerungen zeigt, wenn es mehr Daten abruft.
Durchsatz
Der Durchsatz misst die Anzahl der Lese- oder Schreibvorgänge, die eine Datenbank jede Sekunde verarbeitet. HBase behält einen gleichbleibenden Durchsatz von 100.000 bis 200.000 Vorgängen bei, verzeichnet aber nach 250.000 Vorgängen einen Anstieg. Der Durchsatz von Cassandra steigt, wenn mehr Daten geschrieben oder gelesen werden.
Leseleistung
Bei einem Lesevorgang in Cassandra wird der genaue Speicherort der gespeicherten Daten in der Partitionstabelle ermittelt. Wenn die Suche einen Sekundärschlüssel oder eine Nicht-Partitionstabelle beinhaltet, benötigt Cassandra länger, um jeden Knoten im Cluster zu durchsuchen. Außerdem treten Dateninkonsistenzen auf, wenn mehrere Knoten unterschiedliche Versionen derselben Daten enthalten.
HBase hat eine bessere Leseleistung als Cassandra, da es alle Daten auf einen einzigen Server schreibt. Anders als bei Cassandra muss das Datenbanksystem beim Lesen von Daten in HBase nicht eine Partitionstabelle durchsuchen. Das HDFS, das HBase zum Speichern von Daten verwendet, bietet Bloom-Filter und Block-Caches, was den Datenabruf beschleunigt.
Schreibleistung
Cassandra beendet einen Schreibvorgang schneller als HBase. Mit Cassandra können Sie Daten gleichzeitig in das Protokoll und den Cache schreiben. HBase unterstützt kein gleichzeitiges Schreiben. Stattdessen durchläuft die HBase-Client-Anwendung den Zookeeper, um einen Schreibvorgang zu starten, wobei der HBase-Primärserver die Adresse zum Speichern von Daten bereitstellt. Die zusätzlichen Schritte in HBase verlangsamen den Datenschreibvorgang.
Weitere Hauptunterschiede: Cassandra im Vergleich zu HBase
Sie können sowohl Cassandra als auch HBase verwenden, um Datenwissenschafts-Anwendungen zu erstellen, aber geringfügige Unterschiede beeinflussen die Entscheidung, eine der anderen vorzuziehen.
Sicherheit
Mit Cassandra können Sie den Zugriff auf die Zeilenebene der Datensätze regulieren. Es bietet auch SSL-Verschlüsselung zum Schutz des Datenaustauschs zwischen Knoten. Im Gegensatz zu Cassandra bietet HBase zusätzliche Verschlüsselungs- sowie Verschlüsselungs- und Authentifizierungsfeatures auf Zellebene.
Partitionierung von Daten
Cassandra unterstützt die geordnete Partitionierung und kann die sequentiell geordneten Datensätze scannen, indem sie eine Spalte als Partitionsschlüssel verwendet. Dies mag zwar hilfreich sein, aber eine geordnete Partitionierung erschwert den Lastenausgleich, da mehrere Schreibvorgänge auf einem einzelnen Knoten stattfinden. Eine HBase-Tabelle unterstützt keine geordnete Partitionierung.
Kommunikation zwischen Knoten
In der Cassandra-Architektur sind Seed-Knoten die wichtigsten Punkte für die Kommunikation zwischen Clustern. Diese Knoten verwenden das Gossip-Protokoll, um Daten zwischen verschiedenen Clustern zu verschieben. HBase verwendet einen aktiven HBase-Primärknoten, um die Kommunikation zwischen mehreren Regionsservern zu koordinieren. In dieser Architektur wird die Datenbewegung durch das Zookeeper-Protokoll ausgehandelt.
Einsatzbereich: Cassandra im Vergleich zu HBase
Sowohl Cassandra- als auch HBase-Datenbanken können verschiedenen Arten von Big-Data-Anwendungen helfen. Als Nächstes erläutern wir, welche verteilte Datenbank unter verschiedenen Umständen besser funktionieren würde als die andere.
Verfügbarkeit im Vergleich zu Konsistenz
Cassandra eignet sich für Anwendungsfälle, in denen häufig Daten geschrieben werden müssen, ist jedoch nicht für das häufige Aktualisieren oder Löschen von Daten optimiert. Beispielsweise verwenden Unternehmen Cassandra, um Nachrichtensysteme, interaktive Datenverarbeitungslösungen und Sensordatenspeicher in Echtzeit zu entwickeln. HBase eignet sich besser für Anwendungen, die Datenkonsistenz und häufige Verarbeitung erfordern. Banken-, Gesundheits- und Telekommunikationslösungen verwenden HBase beispielsweise, um große Datenmengen zu analysieren.
Einrichtung der Datenbank
Cassandra ist einfacher einzurichten, da es sich um ein eigenständiges Produkt mit allen erforderlichen Datenbankkomponenten handelt. Im Gegensatz zu Cassandra ist HBase für die Ausführung auf mehrere Hadoop-Komponenten wie Zookeeper, HDFS Primary und HDFS DataNode angewiesen. Die Einrichtung mag einfach sein, aber die Aufrechterhaltung mehrerer Interdependenzen kann sich in realen Anwendungen als schwierig erweisen. Wenn Sie bereits eine Hadoop-Infrastruktur verwenden, ist die Migration zu HBase möglicherweise einfacher als die Migration zu Cassandra.
Zusammenfassung der Unterschiede: Cassandra vs. HBase
|
Cassandra |
HBase |
|
|
Kerndesign |
Verwendet Aktiv-Aktiv-Architekturen. Alle Knoten verarbeiten Lese-/Schreibanforderungen. |
Verwendet eine primär-sekundäre Architektur. HBase steuert primär mehrere Regionalserver. |
|
Die wichtigsten Komponenten |
Memtable-, Commit-Log- und SS-Tabellen. |
HBase-Primär, Regionsserver und Zookeeper. |
|
Datenmodell |
Speichern Sie Zeilen verwandter Spaltenfamilien im Schlüsselraum. |
Horizontal angeordnete Spaltenfamilien mit einem sequentiellen Zeilenschlüssel. |
|
Abfragesprache |
Verwendet die Cassandra-Abfragesprache. |
Verwendet den Shell-Befehl. |
|
Latenz |
Höhere Latenz mit mehr Datenabrufen. |
Niedrigere Latenz mit mehr Datenoperationen. |
|
Durchsatz |
Der Durchsatz steigt mit mehr Datenoperationen. |
Der Durchsatz steigt nach einer bestimmten Anzahl von Vorgängen. |
|
Leseleistung |
Langsam lesen. Verweist auf die Partitionstabelle für den Lesespeicherort. Dateninkonsistenzen können auftreten. |
Bessere Leseleistung und Datenkonsistenz. |
|
Schreibleistung |
Bessere Schreibleistung. Schreibt gleichzeitig in Protokoll und Cache. |
Zusätzliche Schritte. Durchläuft Zookeeper und HBase Primary. |
|
Sicherheit |
Regulieren Sie den Zugriff bis auf Rollenebene. |
Regulieren Sie den Zugriff bis auf Zellebene. |
|
Partitionieren von Daten |
Unterstützt geordnete Partitionierung. |
Unterstützt keine geordnete Partitionierung. |
|
Kommunikation zwischen Knoten |
Verwendet das Klatschprotokoll. |
Verwendet das Zookeeper-Protokoll. |
Wie kann AWS Ihnen bei Ihren Cassandra- und HBase-Anforderungen helfen?
Amazon Web Services (AWS) bietet skalierbare Cloud-Datenbankservices, mit denen Sie Datenwissenschafts-Technologien effizient und kostengünstig implementieren können. Anstatt die zugrunde liegende Infrastruktur manuell bereitzustellen, können Sie die folgenden AWS-Services zur Unterstützung Ihrer Cassandra- und HBase-Datenbanken verwenden:
- Amazon Keyspaces (für Apache Cassandra) ist ein Online-Datenbankservice für die Ausführung von Cassandra-Workloads mit hohem Durchsatz. Mit Amazon Keyspaces können Sie Anwendungen skalieren und gleichzeitig Antwortzeiten im einstelligen Millisekundenbereich einhalten.
- Mit Amazon EMR können Sie HBase-Cluster für umfangreiche Datenverarbeitungsanwendungen bereitstellen. Die Ausführung von HBase auf EMR verbessert die Datenwiederherstellbarkeit, indem gespeicherte Daten auf Amazon Simple Storage Service (Amazon S3) gesichert werden.
Beginnen Sie mit Big Data-Analysen auf AWS, indem Sie noch heute ein Konto erstellen.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages